内存硬件架构
现代内存硬件体系结构与内部Java内存模型有所不同。重要的是要了解硬件体系结构,以便理解Java模型是如何工作的。本节描述了常规的内存硬件体系结构,下一节描述了Java如何使用它。
这是现代计算机的硬件体系结构的简化图:
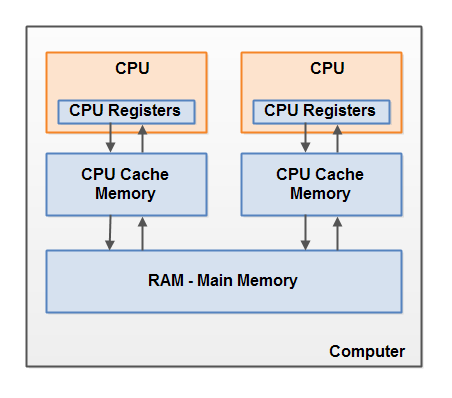
现代计算机通常具有2个或更多处理器。其中一些处理器可能还具有多个内核。在这样的计算机上,可以同时执行多个线程。每个处理器(译者注-在下文中,作者可能指处理器核心或由处理器组成的单核处理器)能够在任何给定时间运行一个线程。这意味着,如果您的Java应用程序是多线程的,则在您的程序中,每个处理器可以同时运行一个线程。
每个处理器包含一组实质上在其内存中的寄存器。它对寄存器中的数据执行操作要比对计算机主内存(RAM)中的数据执行操作快得多。这是因为处理器可以更快地访问这些寄存器。
每个CPU也可以具有一个缓存层。实际上,大多数现代处理器都有它。处理器访问高速缓存的速度比主存储器快得多,但通常不及内部寄存器快。因此,对高速缓存存储器的访问速度介于对内部寄存器和主存储器的访问速度之间。一些处理器可能具有分层的缓存,但这对于理解Java内存模型如何与硬件内存交互并不重要。重要的是要知道处理器可以具有一定级别的缓存。
计算机还包含一个主存储器(RAM)区域。所有处理器都可以访问主内存。主内存区域通常比处理器的缓存大得多。
通常,当处理器需要访问主内存时,它会将其一部分读入其高速缓存。它还可以从缓存中读取一些数据到其内部寄存器中,然后对其执行操作。当CPU需要将结果写回主存储器时,它将数据从其内部寄存器刷新到高速缓存,并在某些时候刷新到主存储器。
当处理器需要在缓存中存储其他内容时,存储在缓存中的数据通常会刷新回主内存。缓存可以清除其内存并同时向其中写入新数据。处理器不必在每次更新时都读取/写入完整的缓存。通常,缓存在称为“缓存行”的小内存块中更新。可以将一个或多个高速缓存行读入高速缓存存储器,并且可以将一个或多个高速缓存行刷新回主存储器。
结合Java内存模型和硬件内存体系结构
如前所述,Java内存模型和内存硬件体系结构是不同的。硬件体系结构不区分线程堆栈和堆。在硬件上,线程堆栈和堆位于主内存中。堆栈和线程堆的某些部分有时可能会出现在CPU的缓存和内部寄存器中。如图所示:

将对象和变量存储在计算机内存的不同区域中时,可能会出现某些问题。主要有两个:
•线程对共享变量所做更改的可见性。
•读取,检查和写入共享变量时的竞争条件。
这两个问题将在以下各节中进行说明。
共享对象可见性
如果两个或多个线程共享一个对象而没有适当的易失性声明或同步,则一个线程对共享对象所做的更改可能对其他线程不可见。
想象一下,共享对象最初存储在主存储器中。在CPU上运行的线程将共享对象读入同一CPU的缓存中。他在那里修改了对象。在将CPU缓存刷新到主存储器之前,共享对象的修改版本对其他CPU上运行的线程不可见。这样,每个线程都可以获得自己的共享库副本,每个副本将位于单独的CPU缓存中。
下图说明了这种情况的示意图。一个线程在左CPU上运行,将共享库复制到其缓存中并更改变量的值
count由2乘以2。此更改对于在正确的CPU上运行的其他线程不可见,因为的更新count尚未刷新回主内存。

为了解决此问题,可以
volatile在声明变量时使用。它可以确保给定的变量直接从主存储器中读取,并且始终在更新时始终写回到主存储器中。
比赛条件
如果两个或多个线程共享同一个对象,并且一个以上的线程更新了该共享对象中的变量,则可能发生竞争状态。
想象一下,线程A正在将
count共享对象变量读入其处理器的缓存中。还可以想象线程B在做相同的事情,但是在不同处理器的缓存中。现在,线程A将变量的值加1 count,而线程B执行相同的操作。现在,它var1已增加了两次,分别是每个处理器的缓存中的+1。
如果按顺序执行这些增量,则变量
count将加倍并写回到主存储器 + 2。
但是,这两个增量在没有适当同步的情况下同时执行。无论哪个线程(A或B)将其更新版本写入
count主内存,尽管有两个增量,但新值仅比原始值大1。
此图说明了上述竞争条件问题的发生:

要解决此问题,可以使用同步的Java块... 同步块可确保在任何给定时间只有一个线程可以输入代码的给定关键部分。同步块还确保从主内存中读取在同步块中访问的所有变量,并且当线程退出同步块时,所有更新的变量都将刷新回主存储器,而不管变量是否声明为
volatile。 ...