介绍
卷积神经网络(CNN)RetinaNet的体系结构由4个主要部分组成,每个部分都有其自己的用途:
a)骨干-用于从输入图像中提取特征的主要(基本)网络。网络的这一部分是可变的,并且可以包括分类神经网络,例如ResNet,VGG,EfficientNet等。
b)特征金字塔网(FPN)-以金字塔形式构建的卷积神经网络,用于结合网络上下两层的特征图的优点,前者具有高分辨率,但语义,泛化能力低;相反,后者;
c)分类子网-一个子网,它从FPN中提取有关对象类别的信息,从而解决了分类问题;
d)回归子网-一个子网,它从FPN中提取有关图像中对象坐标的信息,从而解决了回归问题。
在图。图1显示了以ResNet神经网络为骨干的RetinaNet的体系结构。
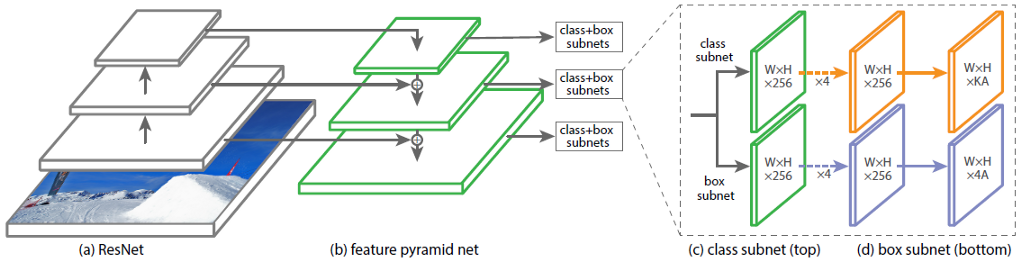
图1-具有ResNet主干的RetinaNet架构
让我们详细分析图2中所示的每个RetinaNet部件。1。
骨干网是RetinaNet网络的一部分
考虑到RetinaNet体系结构中接受图像作为输入并突出显示重要特征的部分是可变的,并且将从该部分提取的信息将在下一阶段进行处理,因此选择合适的骨干网络以获得最佳结果非常重要。
CNN优化的最新研究已导致分类模型的开发,该模型在ImageNet数据集上具有最高的准确率,并且性能提高了10倍,其性能优于以前开发的所有体系结构。这些网络被命名为EfficientNet-B(0-7)。新网络系列的指标如图1所示。2.
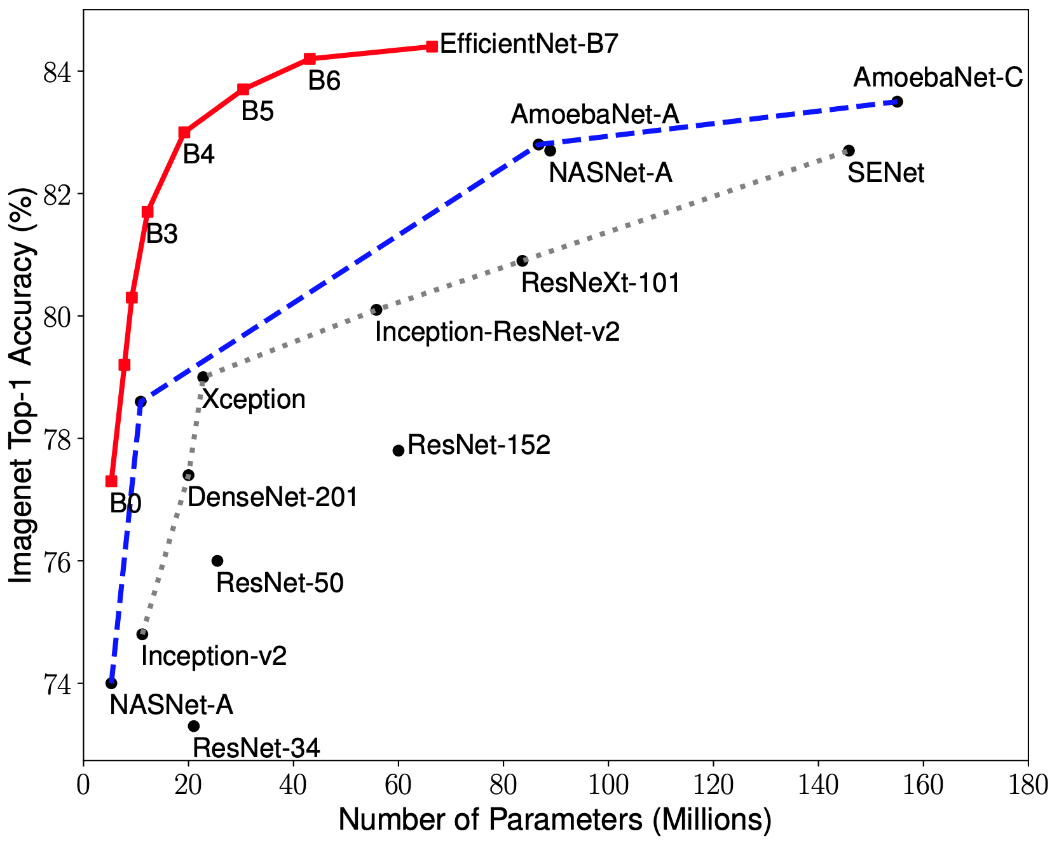
图2-各种体系结构中最高准确性指标对网络权重数量的依赖关系图
标志金字塔
特征金字塔网络包括三个主要部分:自下而上的路径,自上而下的路径和横向连接。
上行路径是一种分层的“金字塔”,即在我们的情况下一系列递减的卷积层序列,即一个骨干网。卷积网络的上层具有更多的语义含义,但分辨率较低,而下层则相反(图3)。自下而上的路径在特征提取中存在一个漏洞-例如,由于背景中一个小而重要的对象的噪声导致丢失了有关某个对象的重要信息,这是因为到网络末端该信息已被高度压缩和泛化。
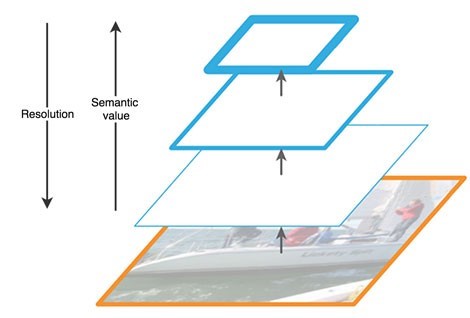
图3-神经网络不同级别的特征图特征
下降路径也是“金字塔”。该金字塔的上层特征图的大小与金字塔的自下而上的上层特征图的大小相同,并通过最近的邻近法(图4)向下加倍。
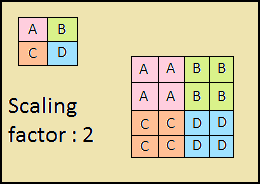
图4-通过最近邻居方法提高图像分辨率
因此,在自顶向下的网络中,上覆层的每个特征图都会增加到基础图的大小。此外,FPN中存在侧连接,这意味着将金字塔的相应的自底向上和自顶向下的图层的特征贴图逐个元素添加,并且自下而上的贴图折叠为1 * 1。该过程在图1中示意性地示出。 5.
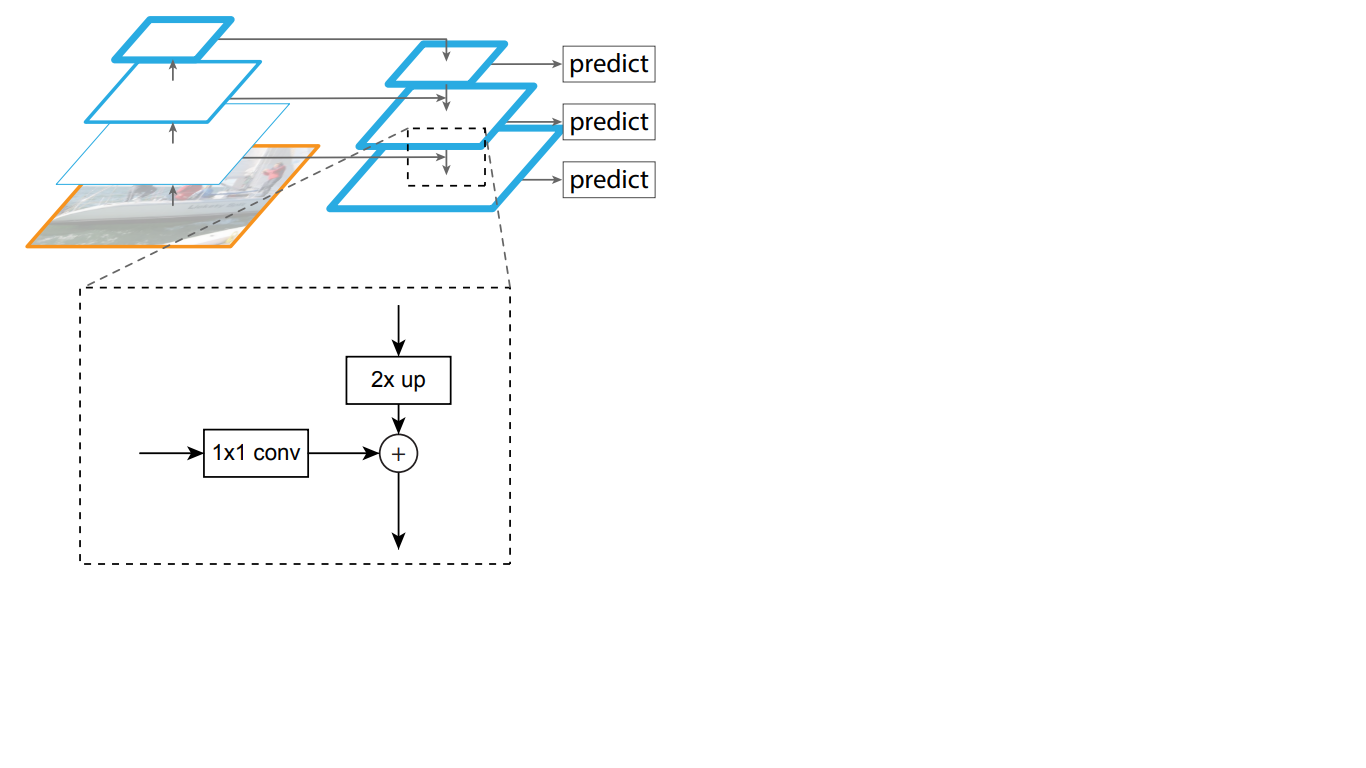
图5-标志金字塔的结构
横向连接解决了在穿过各层的过程中重要信号衰减的问题,将在第一个金字塔末端接收到的语义上重要的信息与在其前面获得的更详细的信息进行了组合。
此外,由两个子网处理自顶向下金字塔中的每个结果层。
分类和回归子网
RetinaNet架构的第三部分是两个子网:分类和回归(图6)。这些子网中的每一个都在输出处形成有关对象类别及其在图像上位置的响应。让我们考虑它们各自的工作原理。
图6-RetinaNet子网
在最后一层之前,所考虑的块(子网)的原理不同。它们每个都由4层卷积网络组成。该图层中形成256个特征图。在第五层上,特征图的数量发生变化:回归子网具有4个* A特征图,分类子网具有K * A个特征图,其中A是锚点框架的数量(下一小节中锚点框架的详细说明),K是对象类别的数量。
在最后的第六层中,每个特征图都转换为一组向量。输出处的回归模型为每个锚点框都有一个4个值的向量,表示地面真相框相对于锚点框的偏移量。分类模型在每个锚帧的输出处都有一个长度为K的单热点矢量,其中值为1的索引对应于神经网络分配给对象的类编号。
锚框架
在上一节中,使用了锚框架一词。锚定框是神经网络-检测器的超参数,网络是相对于网络运行的预定义边界矩形。
假设网络在输出处具有3 * 3特征图。在RetinaNet中,每个单元都有9个锚框,每个锚框的大小和纵横比都不同(图7)。在训练期间,锚帧与每个目标帧匹配。如果其IoU值为0.5,则将锚帧指定为目标,如果该值小于0.4,则将其视为背景,在其他情况下,将忽略锚帧进行训练。分类网络是相对于分配的任务(对象类别或背景)进行训练的,回归网络是相对于锚定框架的坐标进行的训练(重要的是要注意,误差是相对于锚定框架而不是目标框架计算的)。
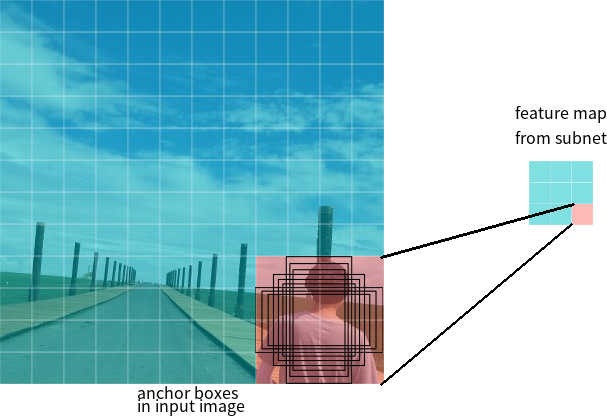
图7-要素图的一个像元的锚框,大小为3 * 3
损失函数
RetinaNet损失是复合的,它们由两个值组成:回归或定位误差(在下面表示为Lloc)和分类误差(在下面表示为Lcls)。一般损失函数可以写成:
其中λ是控制两个损耗之间平衡的超参数。
让我们更详细地考虑每种损失的计算。
如前所述,每个目标帧都分配有一个锚点。让我们将这些对表示为(Ai,Gi)i = 1,... N,其中A表示锚点,G是目标帧,N是匹配对的数量。
对于每个锚点,回归网络预测4个数字,可以将其表示为Pi =(Pix,Piy,Piw,Pih)。前两对代表锚点Ai和目标框架Gi的中心坐标之间的预测差异,后两对代表其宽度和高度之间的预测差异。因此,对于每个目标帧,将Ti计算为锚点和目标帧之间的差:
其中smoothL1(x)由以下公式定义:
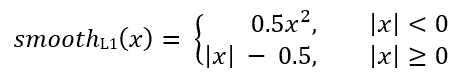
RetinaNet分类问题损失是使用焦点损失函数计算的。
其中K是类别数,yi是类别的目标值,p是预测第i个类别的概率,γ是聚焦参数,α是偏置系数。此功能是高级的交叉熵功能。区别在于添加了参数γ∈(0,+∞),解决了类不平衡的问题。在训练期间,分类器处理的大多数对象都是背景,这是一个单独的类。因此,当神经网络学习比其他对象更好地确定背景时,可能会出现问题。添加新参数可以通过减少易于分类的对象的误差值来解决此问题。焦点和交叉熵函数的图形如图8所示。
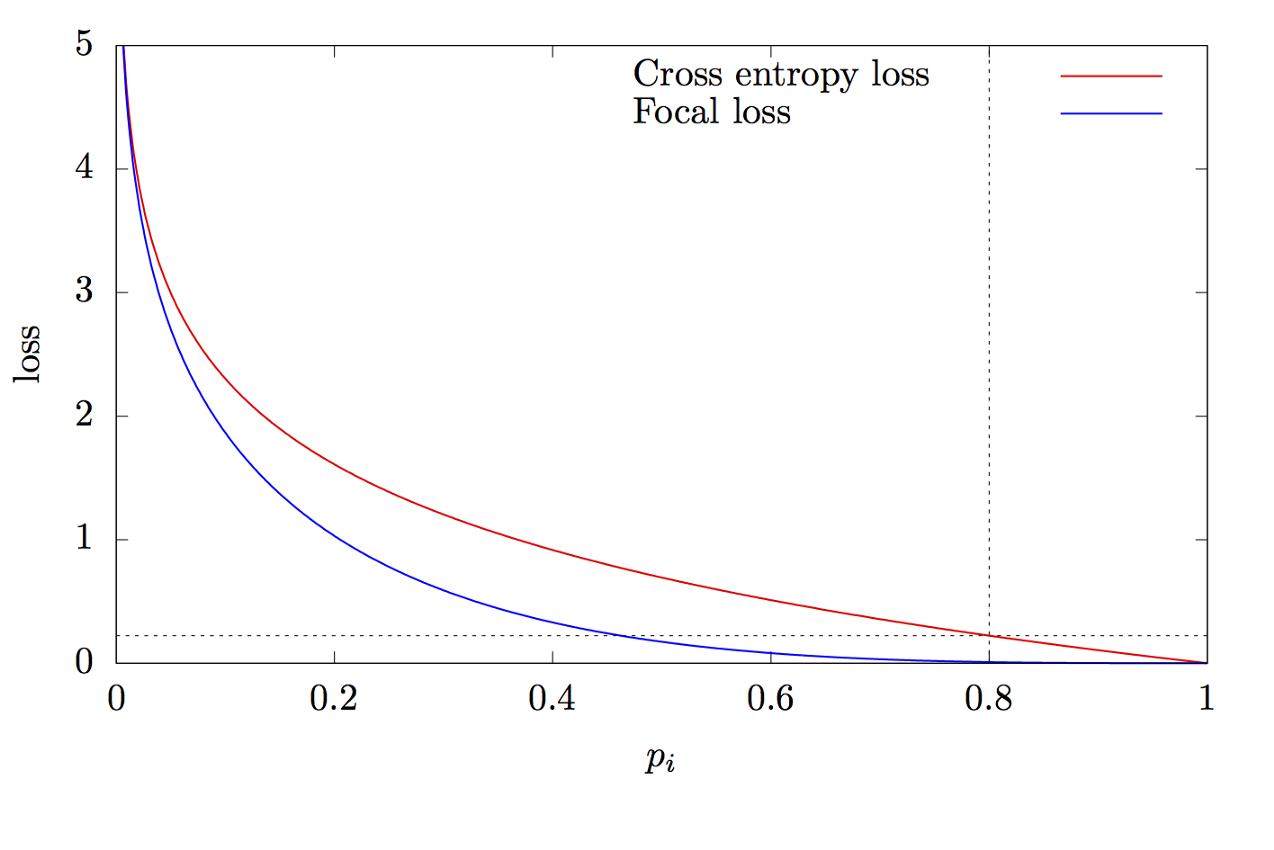
图8-焦点和交叉熵函数图
感谢您阅读本文!
来源清单:
- Tan M., Le Q. V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. 2019. URL: arxiv.org/abs/1905.11946
- Zeng N. RetinaNet Explained and Demystified [ ]. 2018 URL: blog.zenggyu.com/en/post/2018-12-05/retinanet-explained-and-demystified
- Review: RetinaNet — Focal Loss (Object Detection) [ ]. 2019 URL: towardsdatascience.com/review-retinanet-focal-loss-object-detection-38fba6afabe4
- Tsung-Yi Lin Focal Loss for Dense Object Detection. 2017. URL: arxiv.org/abs/1708.02002
- The intuition behind RetinaNet [ ]. 2018 URL: medium.com/@14prakash/the-intuition-behind-retinanet-eb636755607d