
机器学习是越来越多地从手设计的车型转移到使用工具如自动优化管道H20,TPOT,并自动sklearn。这些库以及诸如随机搜索之类的技术旨在通过为数据集找到最佳模型而无需任何人工干预,从而简化模型选择和调整机器学习的各个部分。但是,对象开发(可以说是机器学习管道中更有价值的方面)几乎仍然是人类的。
设计特征(特征工程)(也称为特征创建)是根据现有数据创建新特征以训练机器学习模型的过程。这一步可能比实际使用的模型更重要,因为机器学习算法仅从我们提供的数据中学习,并且绝对有必要创建与任务相关的功能(请参见出色的文章“少量有用的东西”)关于机器学习的知识”)。
通常,功能开发是基于领域知识,直觉和数据操作的冗长的手动过程。这个过程可能非常繁琐,并且最终特征将受到人类主观性和时间的限制。自动化功能设计旨在帮助数据科学家从数据集中自动创建许多候选对象,从中可以选择最佳对象并将其用于训练。
在本文中,我们将看一个通过Python featuretools库使用自动功能开发的示例。... 我们将使用样本数据集来显示基础知识(使用真实数据注意将来的帖子)。GitHub上提供了本文的完整代码。
功能开发基础
特征开发意味着从现有数据创建其他特征,这些数据通常分布在多个相关表中。功能开发需要从数据中提取相关信息,并将其放入单个表中,然后可用于训练机器学习模型。
创建特征的过程非常耗时,因为创建每个新特征通常要花费几个步骤,尤其是在使用来自多个表的信息时。我们可以将要素创建操作分为两类:转换和聚合。让我们看一些示例,以了解这些概念的实际作用。
转型作用于单个表(用Python来讲,表只是Pandas
DataFrame),从一个或多个现有列创建新功能。例如,如果我们下面有客户表,
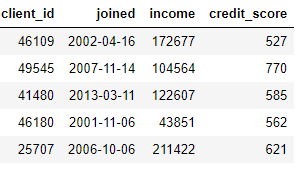
我们可以通过从列中查找月份
joined或从列中取自然对数来创建要素income。这两个都是转换,因为它们仅使用一个表中的信息。
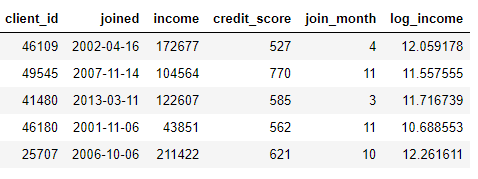
另一方面,汇总是在表之间执行的,并使用一对多关系对案例进行分组,然后计算统计信息。例如,如果我们有另一个表包含有关客户贷款的信息,其中每个客户可以拥有几笔贷款,我们可以计算统计数据,例如每个客户的平均,最大和最小贷款值。
此过程包括按客户对贷款表进行分组,计算汇总,然后将接收到的数据与客户数据进行组合。这就是我们可以使用Pandas语言在Python中实现的方法。
import pandas as pd
# Group loans by client id and calculate mean, max, min of loans
stats = loans.groupby('client_id')['loan_amount'].agg(['mean', 'max', 'min'])
stats.columns = ['mean_loan_amount', 'max_loan_amount', 'min_loan_amount']
# Merge with the clients dataframe
stats = clients.merge(stats, left_on = 'client_id', right_index=True, how = 'left')
stats.head(10)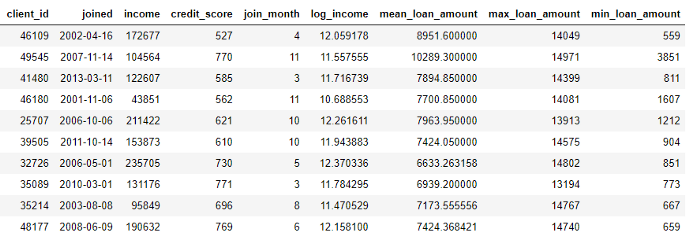
这些操作本身并不复杂,但是如果我们有数十个表中分散的数百个变量,则无法手动完成此过程。理想情况下,我们需要一种能够在多个表之间自动执行转换和聚合并将结果数据合并到一个表中的解决方案。尽管Pandas是一个很好的资源,但仍有许多我们想手动进行的数据处理!(有关手动设计功能的更多信息,请参见出色的《Python数据科学手册》。)
功能工具
幸运的是,featuretools正是我们正在寻找的解决方案。这个开源的Python库自动从一组相关表中生成许多特征。 Featuretools基于一种称为“ 深度特征综合 ”的技术,听起来比实际要令人印象深刻(名称来源于组合多个特征,而不是因为它使用了深度学习!)。
深度特征综合结合了多种转换和聚合操作(称为特征原语)(在FeatureTools词典中)以根据分布在许多表格中的数据创建要素。像机器学习中的大多数想法一样,它是基于简单概念的复杂方法。通过一次研究一个构建基块,我们可以很好地理解这一强大的技术。
首先,让我们看一下示例中的数据。我们已经从上面的数据集中看到了一些东西,完整的表集看起来像这样:
clients:有关信用协会中客户的基本信息。每个客户端在此数据框中只有一行
loans:向客户贷款。在此数据框中,每个信用仅具有其自己的行,但是客户可以具有多个信用。
payments: 贷款支付。每笔付款只有一行,但每笔贷款将有多笔付款。
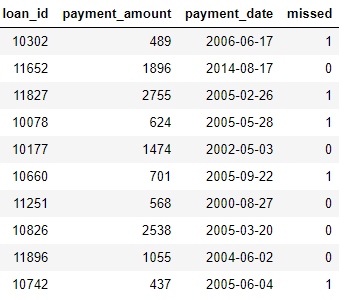
如果我们有一个机器学习任务,例如预测客户是否会偿还未来的贷款,则我们希望将所有客户信息合并到一个表中。这些表是链接的(通过
client_id和变量loan_id),我们可以使用一系列转换和聚合来手动完成该过程。但是,我们很快就会看到,我们可以改用Featuretools来自动执行该过程。
实体和实体集(实体和实体集)
特征工具的前两个概念是实体和实体集。实体只是一张桌子(或者
DataFrame如果您认为是熊猫)。EntitySet是表及其之间关系的集合。想象一下,实体集只是另一个具有自己的方法和属性的Python数据结构。
我们可以使用以下功能在Featuretools中创建一组空实体:
import featuretools as ft
# Create new entityset
es = ft.EntitySet(id = 'clients')现在我们需要添加实体。每个实体必须具有索引,该索引是包含所有唯一元素的列。也就是说,索引中的每个值必须在表中仅出现一次。数据帧中的索引
clients是client_id因为每个客户端在该数据帧中只有一行。我们使用以下语法将具有现有索引的实体添加到实体集:
# Create an entity from the client dataframe
# This dataframe already has an index and a time index
es = es.entity_from_dataframe(entity_id = 'clients', dataframe = clients,
index = 'client_id', time_index = 'joined')数据框
loans还具有唯一索引loan_id,并且将其添加到实体集的语法与相同clients。但是,支付数据框没有唯一的索引。当我们将此实体添加到实体集中时,我们需要传递一个参数make_index = True并指定索引名称。此外,虽然featuretools会自动推断实体中每个列的数据类型,但我们可以通过将列类型的字典传递给parameter来覆盖它variable_types。
# Create an entity from the payments dataframe
# This does not yet have a unique index
es = es.entity_from_dataframe(entity_id = 'payments',
dataframe = payments,
variable_types = {'missed': ft.variable_types.Categorical},
make_index = True,
index = 'payment_id',
time_index = 'payment_date')对于此数据框,尽管它
missed是整数,但它不是数字变量,因为它只能接受2个离散值,因此我们告诉Featuretools将其视为分类变量。将数据帧添加到实体集之后,我们检查其中的任何一个:
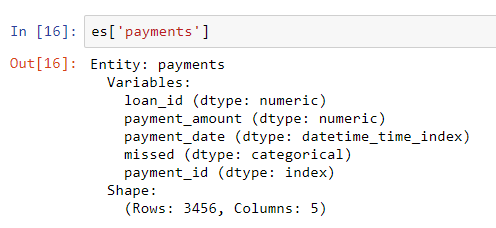
使用指定的修订版可以正确推断出列类型。接下来,我们需要指示实体集中的表如何关联。
表之间的关系
表示两个表之间关系的最好方法是使用父子类比。一对多关系:每个父母可以有多个孩子。在表区域中,父表的每个父表都有一行,但是子表可以有多行对应于同一父表的多个子表。
例如,在我们的数据集中,
clients框架是框架的父级loans。每个客户只有一行clients,但可以有多行loans。同样loans是父母payments因为每笔贷款将分多次付款。父母通过一个公共变量链接到他们的孩子。进行聚合时,我们将子表按照父变量分组,并计算每个父表的子项的统计信息。
要在featuretools中形式化关系,我们只需要指定一个将两个表链接在一起的变量即可。
clients并且该表loans与变量 client_id,和 loans和payments-借助关联 loan_id。创建关系并将其添加到实体集的语法如下所示:
# Relationship between clients and previous loans
r_client_previous = ft.Relationship(es['clients']['client_id'],
es['loans']['client_id'])
# Add the relationship to the entity set
es = es.add_relationship(r_client_previous)
# Relationship between previous loans and previous payments
r_payments = ft.Relationship(es['loans']['loan_id'],
es['payments']['loan_id'])
# Add the relationship to the entity set
es = es.add_relationship(r_payments)
es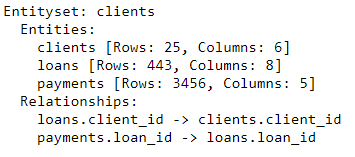
现在,实体集包含三个实体(表)和将这些实体联系在一起的关系。添加实体并形式化关系后,我们的实体集就完成了,我们准备创建特征。
特征原语
在我们完全进入特质的深入综合之前,我们需要了解特质的原始知识。我们已经知道它们是什么,但是我们只是用不同的名字来称呼它们!这些只是我们用来形成新功能的基本操作:
- 汇总:对父子关系(一对多)执行的操作,按父级分组并计算子项的统计信息。一个示例是对表
loans进行分组,client_id并确定每个客户的最大贷款额。 - 转换:从一张表到一列或多列的操作。例如,同一表中两列之间的差异或一列的绝对值。
使用这些原语(本身或作为多个原语)在Featuretools中创建新功能。以下列出了featuretools中的一些原语(我们也可以定义自定义原语):
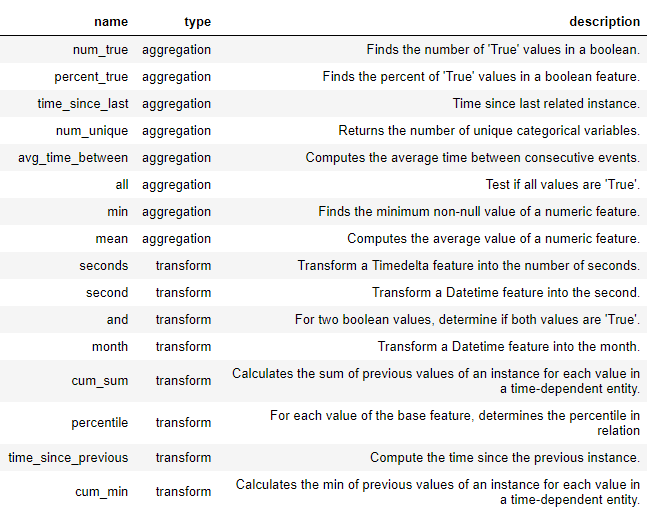
这些原语可以单独使用或组合使用来创建特征。要使用指定的原语创建特征,我们使用一个函数
ft.dfs(代表深度特征综合)。我们传递了一组实体target_entity,这是一个表,我们要向其中添加选定的特征 trans_primitives(变换)和agg_primitives(集合):
# Create new features using specified primitives
features, feature_names = ft.dfs(entityset = es, target_entity = 'clients',
agg_primitives = ['mean', 'max', 'percent_true', 'last'],
trans_primitives = ['years', 'month', 'subtract', 'divide'])结果是每个客户端都有新功能的数据框(因为我们已经创建了客户端
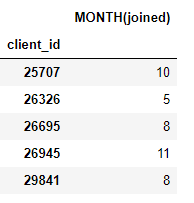
target_entity)。例如,每个客户都有一个月加入,这是一个转换原语:
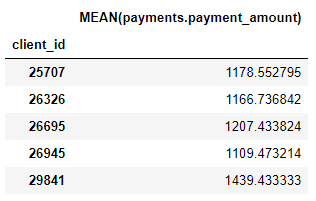
我们还有许多汇总原语,例如每个客户的平均付款金额:
即使我们只指定了一些原语,featuretools通过组合和堆叠这些原语也创建了许多新功能。
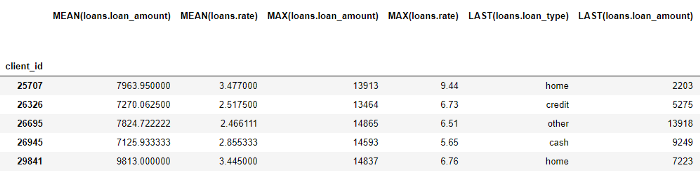
完整的数据框包含793列新功能!
标志的深度合成
现在,我们掌握了深入的功能综合(dfs)的所有知识。实际上,我们已经在上一个函数调用中执行了dfs!深层特征只是由多个原语组合而成的特征,而dfs是创建这些特征的进程的名称。深度特征的深度是创建特征所需的基本体数量。
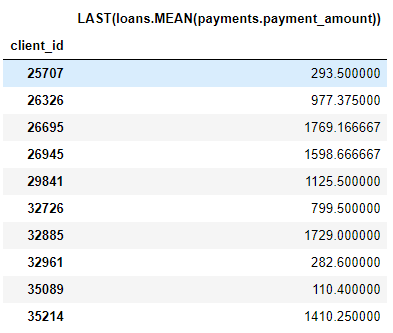
例如,列
MEAN (payment.payment_amount)是深度为1的深层功能,因为它是使用单个聚合创建的。深度为2的元素是this LAST(loans(MEAN(payment.payment_amount))。这是通过组合两个聚合来完成的:MEAN之上的LAST(最新)。这代表每个客户的最新贷款的平均付款额。
我们可以将功能组合到所需的任何深度,但实际上,我从来没有超出深度2。此后,功能难以解释,但我敦促任何有兴趣尝试“深入”的人。
我们不需要手动指定原语,而是可以让Featuretools为我们自动选择要素。为此,我们使用相同的函数调用
ft.dfs,但是我们不传递任何原语:
# Perform deep feature synthesis without specifying primitives
features, feature_names = ft.dfs(entityset=es, target_entity='clients',
max_depth = 2)
features.head()
Featuretools为我们创建了许多新功能。尽管此过程会自动创建新的特征,但它不会取代数据科学家,因为我们仍然必须弄清楚如何处理所有这些特征。例如,如果我们的目标是预测客户是否会偿还贷款,我们可能会寻找与特定结果最相关的迹象。此外,如果我们了解主题领域,则可以使用它来选择特征的特定图元或用于候选特征的深度合成。
下一步
自动化功能设计解决了一个问题,但又创建了另一个问题:功能过多。尽管很难说出哪些特征在拟合模型之前很重要,但很可能并非所有特征都与我们要训练模型的任务有关。此外,太多的功能会降低模型性能,因为有用性较低的功能会挤出那些更重要的功能。
属性过多的问题被称为尺寸诅咒。随着模型中特征数量(数据维度)的增加,研究特征与目标之间的对应关系变得更加困难。实际上,模型正常运行所需的数据量为要素的数量呈指数增长。
维数的诅咒与特征缩减(也称为特征选择)结合在一起:去除不必要特征的过程。这可以采用多种形式:主成分分析(PCA),SelectKBest,使用模型中的特征值或使用深度神经网络进行自动编码。但是,功能降低是另一篇文章的单独主题。至此,我们知道可以使用FeatureTools轻松地从许多表创建许多特征!
输出量
像机器学习中的许多主题一样,具有功能工具的自动功能设计是基于简单思想的复杂概念。使用实体,实体和关系集的概念,功能部件工具可以执行深度功能部件综合以创建新功能部件。特征的深度综合又结合了原语(通过表之间的一对多关系进行操作的聚合以及转换,应用于一个表中一个或多个列的函数)以从多个表中创建新特征。

通过参加SkillFactory的付费在线课程,了解如何从头开始或获得技能和薪资水平提高的详细信息:
- 机器学习课程(12周)
- Data Science (12 )
- (9 )
- «Python -» (9 )
- DevOps (12 )
- - (8 )