有关沉没成本的认知扭曲(沉没成本谬误)是人们成为受害者的许多有害认知偏见之一。这是指我们倾向于继续投入时间的趋势和资源用于失败的事业,因为我们已经花了太多时间淹没了-淹死了。成本低廉的谬误适用于比我们应有的工作更长的时间,即使在很显然无法正常工作的情况下,也要忙于一个项目,是的,是的,继续使用无聊的,过时的绘图库-matplotlib-更高效,互动和更具吸引力的替代方案。
在过去的几个月中,我意识到使用matplotlib的唯一原因是因为花了数百个小时来学习复杂的语法。这些复杂性导致数小时的挫败感在StackOverflow上弄清楚如何格式化日期或添加第二个Y轴... 幸运的是,这是使用Python绘制图形的绝佳时机,在探索了各种选择之后,在易用性,文档和功能方面,显然是赢家。在本文中,我们将深入研究各种情节,学习如何在更短的时间内创建更好的图表(通常只需一行代码)。
GitHub上提供了本文的 所有代码。所有图形都是交互式的,可以在NBViewer上查看。
剧情概述
用于Python的plotly 软件包-一个基于plotly.js构建的开源软件库,该库又基于d3.js构建。我们将使用包装上称为Puffs的袖扣的包装来设计与Pandas DataFrame.So,我们的堆栈袖扣> plotly> plotly.js> d3.js-这意味着我们将以令人难以置信的交互式图形功能d3获得Python编程的效率。
(Plotly本身是一家图形公司带有几种开源产品和工具。Python库是免费使用的,我们可以离线创建无限量的图表,最多可以在线创建25个图表以与世界共享。)本文中的
所有工作都是在Jupyter Notebook中完成的,并具有可绘制+袖扣的功能离线。安装plotly和袖扣后,
pip install cufflinks plotly 导入以下内容以在Jupiter中运行:
# Standard plotly imports
import plotly.plotly as py
import plotly.graph_objs as go
from plotly.offline import iplot, init_notebook_mode
# Using plotly + cufflinks in offline mode
import cufflinks
cufflinks.go_offline(connected=True)
init_notebook_mode(connected=True)单变量分布:直方图和箱形图
单变量图-一维是开始分析的标准方法,直方图是用于绘制分布图的过渡图(尽管存在一些问题)。在这里,使用我的平均文章统计信息(您可以在此处查看如何获得自己的统计信息,或使用mine),让我们对文章拍手数量进行交互式直方图处理(
df这是标准的Pandas数据框):
df['claps'].iplot(kind='hist', xTitle='claps',
yTitle='count', title='Claps Distribution')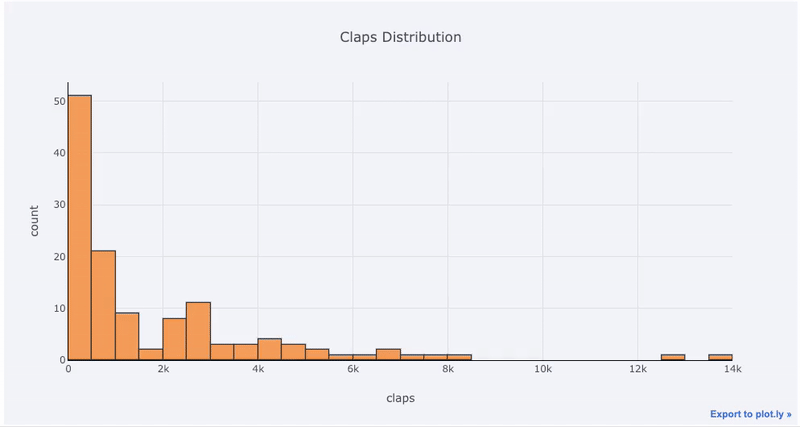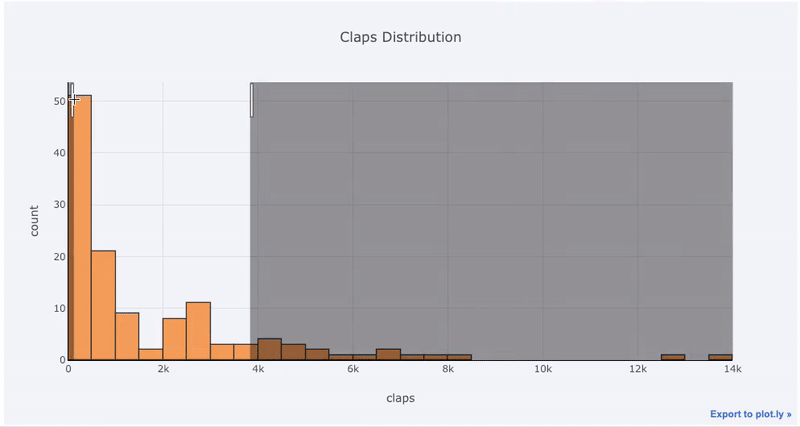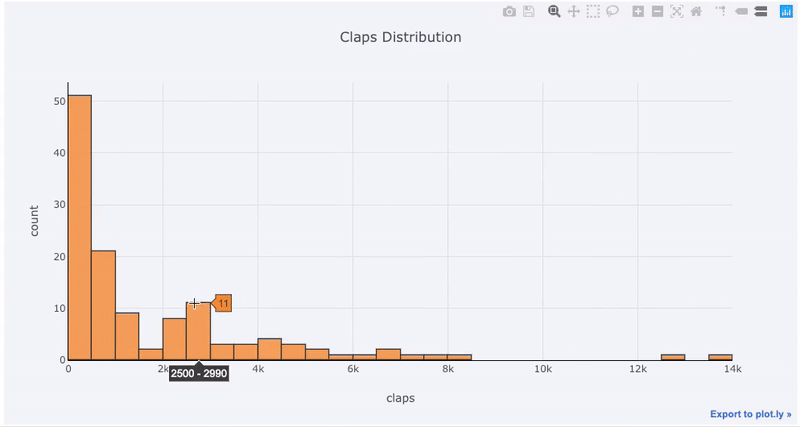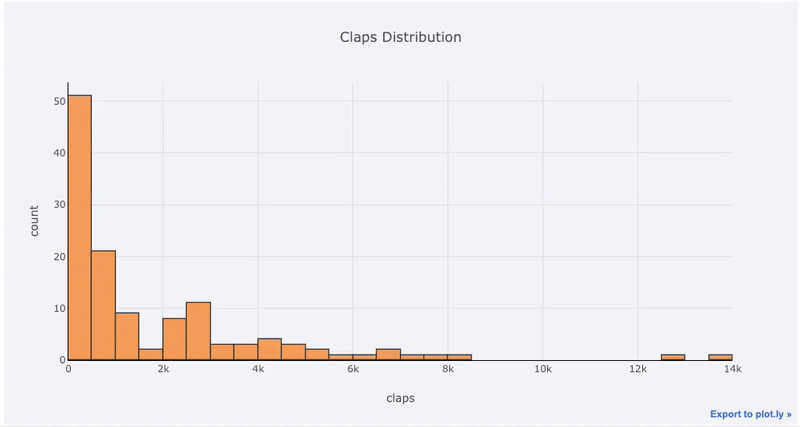
对于那些习惯于此的人
matplotlib,我们要做的就是再添加一个字母(iplot而不是plot),我们将获得一个更加美观和互动的图表!我们可以单击数据以获取更多信息,放大图的各个部分,并在稍后看到,选择不同的类别。
如果我们想绘制叠加的直方图,就很简单:
df[['time_started', 'time_published']].iplot(
kind='hist',
histnorm='percent',
barmode='overlay',
xTitle='Time of Day',
yTitle='(%) of Articles',
title='Time Started and Time Published')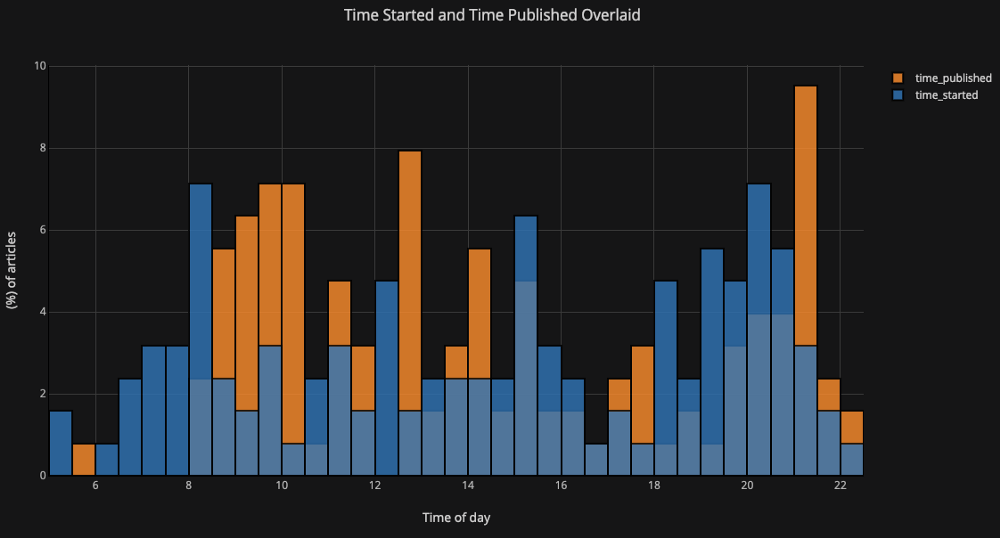
稍加操作
Pandas,我们就可以制作一个小图:
# Resample to monthly frequency and plot
df2 = df[['view','reads','published_date']].\
set_index('published_date').\
resample('M').mean()
df2.iplot(kind='bar', xTitle='Date', yTitle='Average',
title='Monthly Average Views and Reads')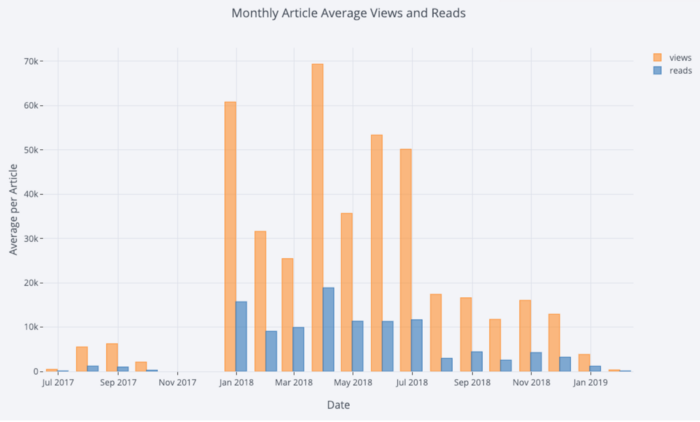
如我们所见,我们可以将Pandas的功能与Plots +袖扣结合起来。要对发布的粉丝分布进行箱线图
pivot绘制,我们使用,然后绘制:
df.pivot(columns='publication', values='fans').iplot(
kind='box',
yTitle='fans',
title='Fans Distribution by Publication')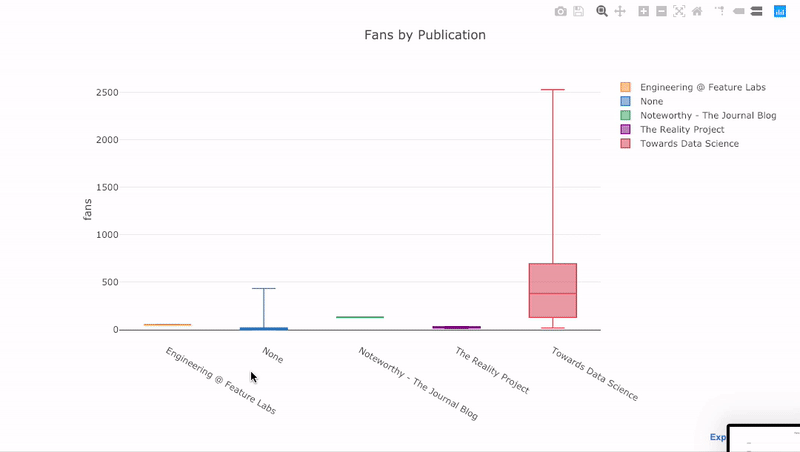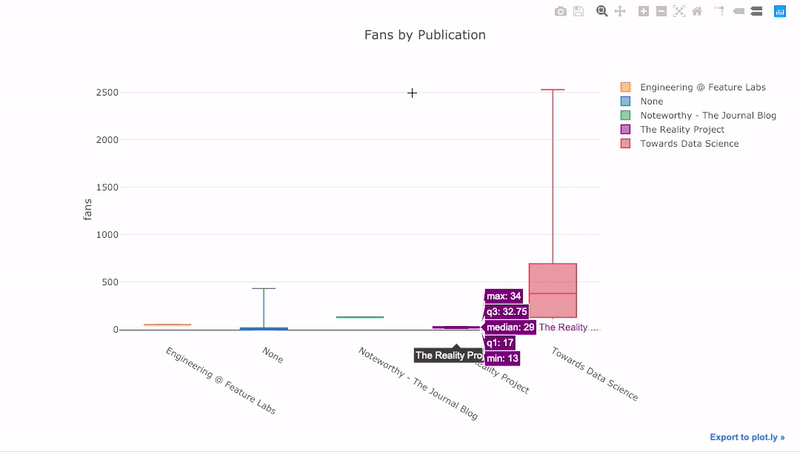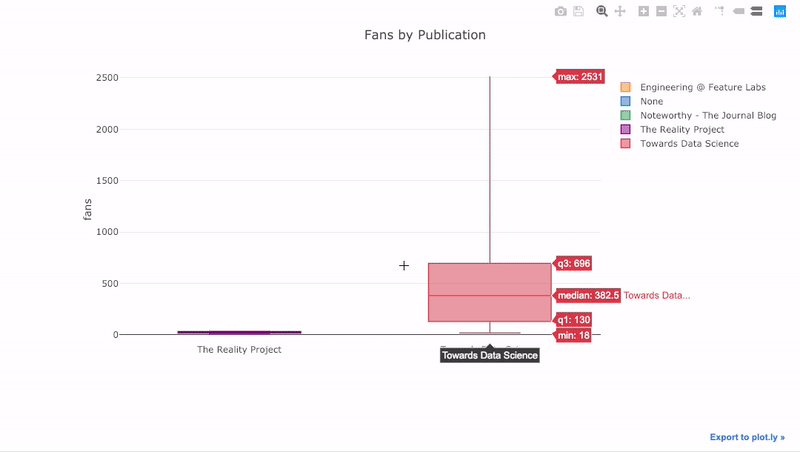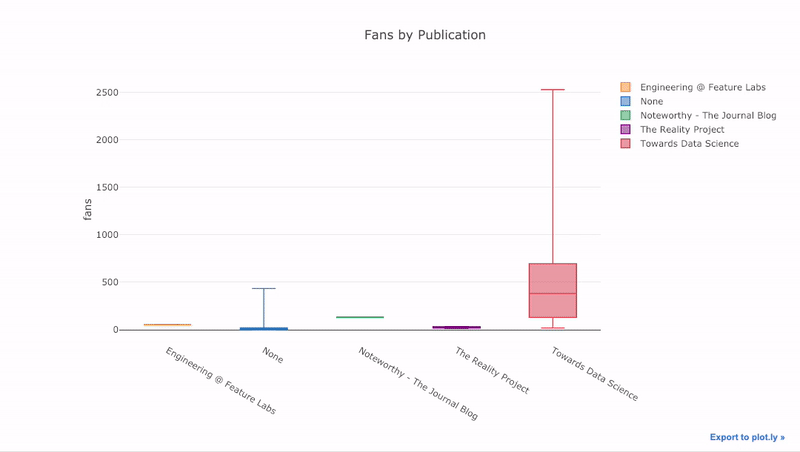
交互的好处是,我们可以根据需要浏览和托管数据。箱式木筏中有很多信息,如果看不到数字,我们将错过大多数!
散点图
散点图是大多数分析的核心。这使我们可以看到变量随时间的演变,或者两个(或多个)变量之间的关系。
时间序列
许多真实数据都有时间元素。幸运的是,plotly +袖扣的设计考虑了时间序列的可视化。让我们对TDS文章中的数据进行框架分析,看看趋势如何变化。
Create a dataframe of Towards Data Science Articles
tds = df[df['publication'] == 'Towards Data Science'].\
set_index('published_date')
# Plot read time as a time series
tds[['claps', 'fans', 'title']].iplot(
y='claps', mode='lines+markers', secondary_y = 'fans',
secondary_y_title='Fans', xTitle='Date', yTitle='Claps',
text='title', title='Fans and Claps over Time')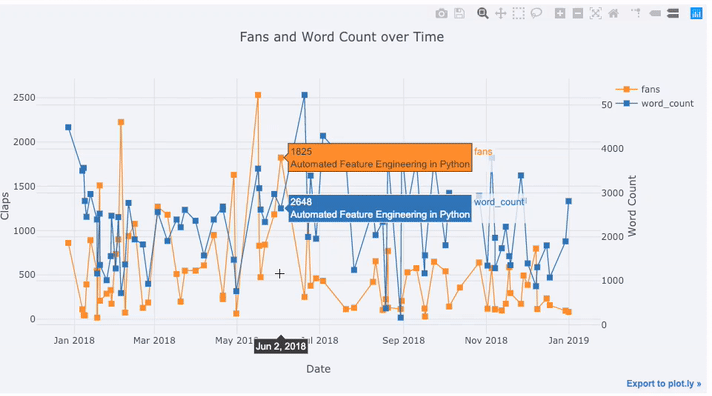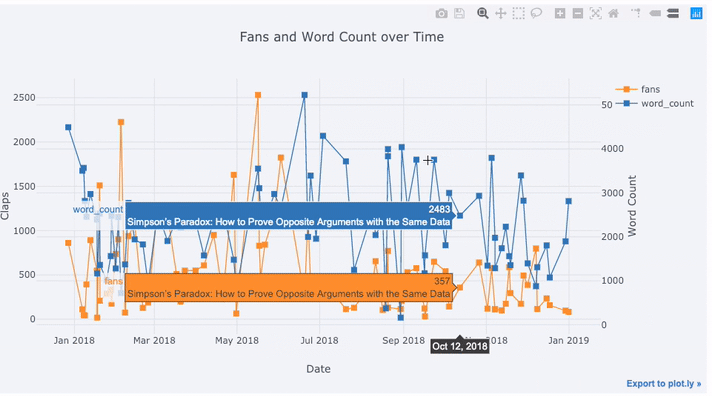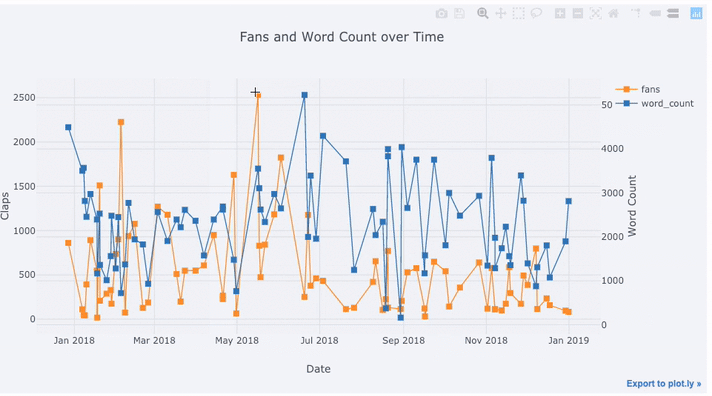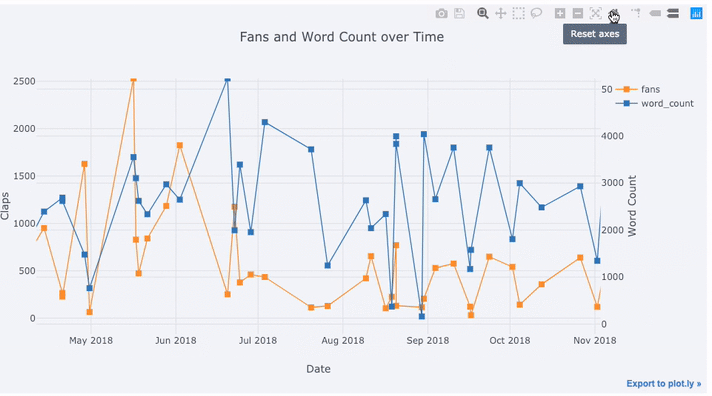
我们在这里看到很多不同的东西:
- 自动在x轴上获取格式正确的时间序列
- 添加辅助y轴,因为我们的变量具有不同的范围
- 在悬停时显示文章标题
有关更多信息,我们还可以轻松添加文本注释:
tds_monthly_totals.iplot(
mode='lines+markers+text',
text=text,
y='word_count',
opacity=0.8,
xTitle='Date',
yTitle='Word Count',
title='Total Word Count by Month')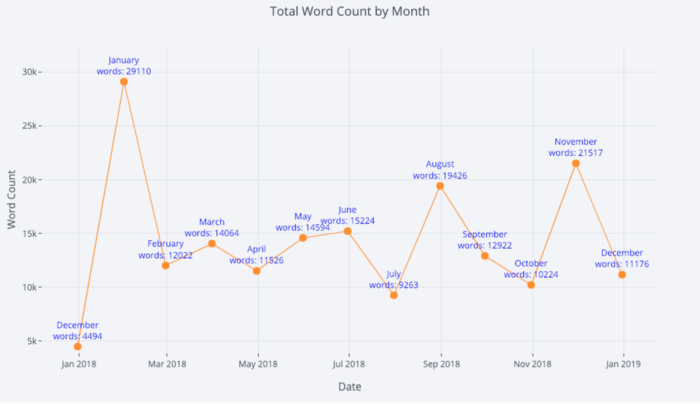
对于用第三个分类变量着色的二变量散点图,我们使用:
df.iplot(
x='read_time',
y='read_ratio',
# Specify the category
categories='publication',
xTitle='Read Time',
yTitle='Reading Percent',
title='Reading Percent vs Read Ratio by Publication')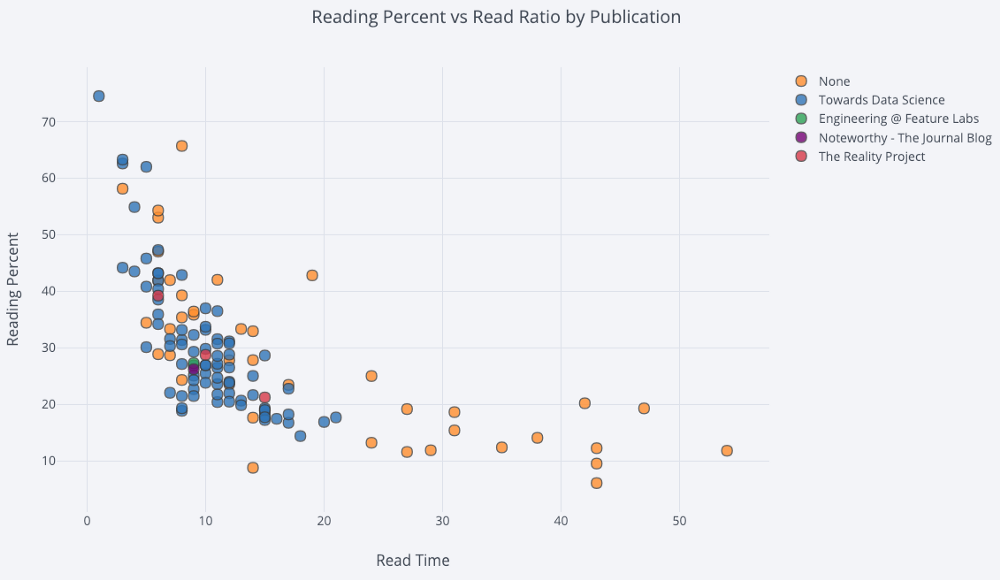
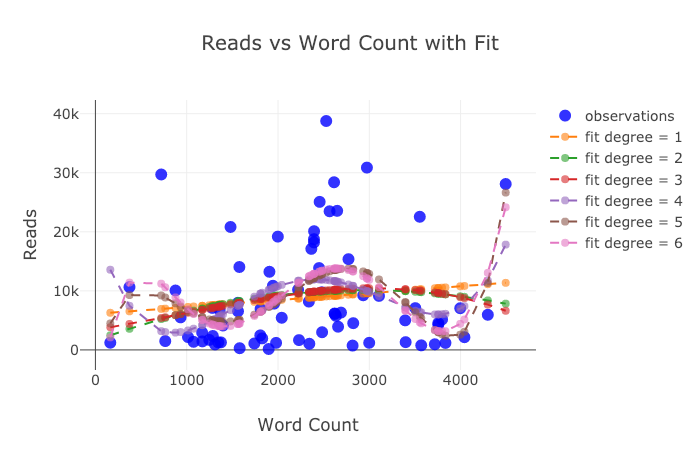
让我们使用指定为plotly布局的对数轴使事情复杂化(请参阅Plotly文档以获取布局规范),并指定数值变量的气泡大小:
tds.iplot(
x='word_count',
y='reads',
size='read_ratio',
text=text,
mode='markers',
# Log xaxis
layout=dict(
xaxis=dict(type='log', title='Word Count'),
yaxis=dict(title='Reads'),
title='Reads vs Log Word Count Sized by Read Ratio'))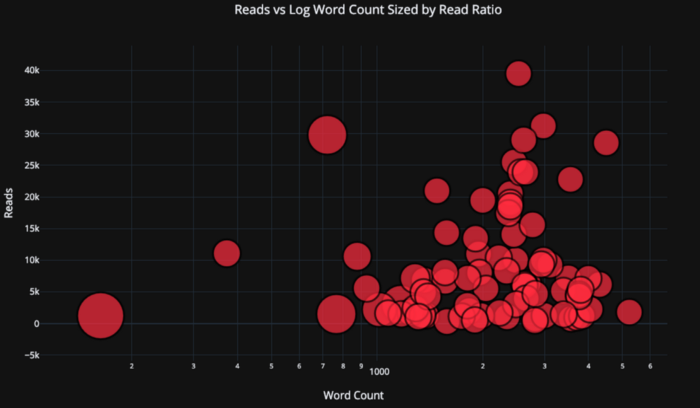
通过一点点工作(有关详细信息,请参见NoteBook),我们甚至可以在一个图形上放置四个变量(不推荐使用)!
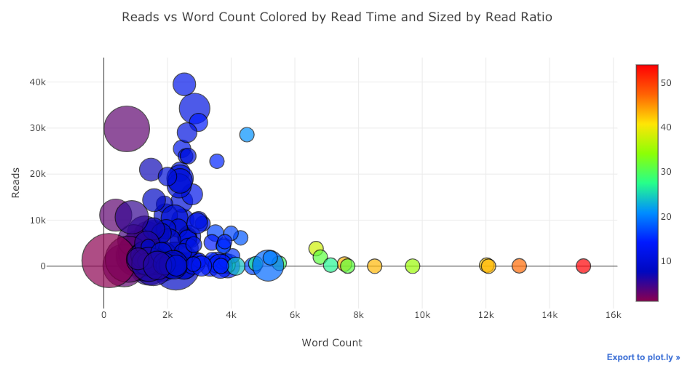
和以前一样,我们可以将Pandas与Plotly +袖扣结合使用,以获得有用的图形
df.pivot_table(
values='views', index='published_date',
columns='publication').cumsum().iplot(
mode='markers+lines',
size=8,
symbol=[1, 2, 3, 4, 5],
layout=dict(
xaxis=dict(title='Date'),
yaxis=dict(type='log', title='Total Views'),
title='Total Views over Time by Publication'))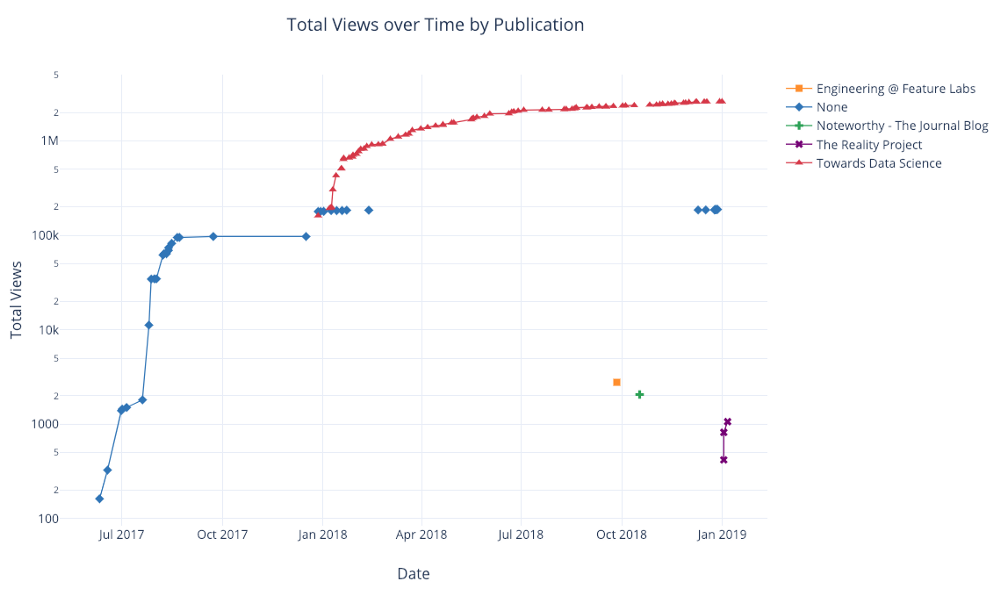
有关功能的更多示例,请参阅笔记本或文档。我们可以使用一行代码并且仍然进行所有交互,将文本注释,参考线和最佳拟合线添加到我们的图中。
高级图表
现在,我们继续介绍一些您可能不会经常使用的图形,但是它们会给人留下深刻的印象。我们将使用plotly fig_factory在一行中甚至完成这些令人难以置信的操作。
散射矩阵
当我们要探索许多变量之间的关系时,分散矩阵(也称为splom)是一个不错的选择:
import plotly.figure_factory as ff
figure = ff.create_scatterplotmatrix(
df[['claps', 'publication', 'views',
'read_ratio','word_count']],
diag='histogram',
index='publication')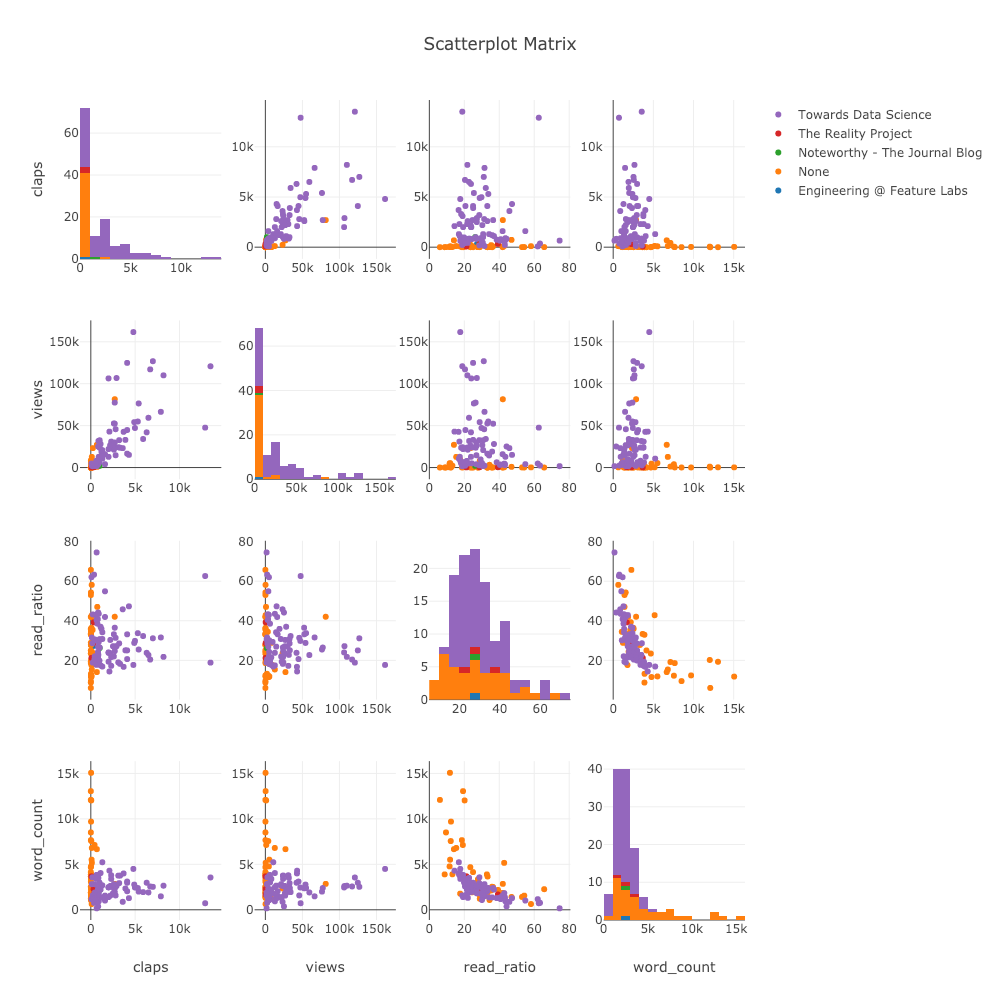
即使这张图是完全互动的,也使我们能够探索数据。
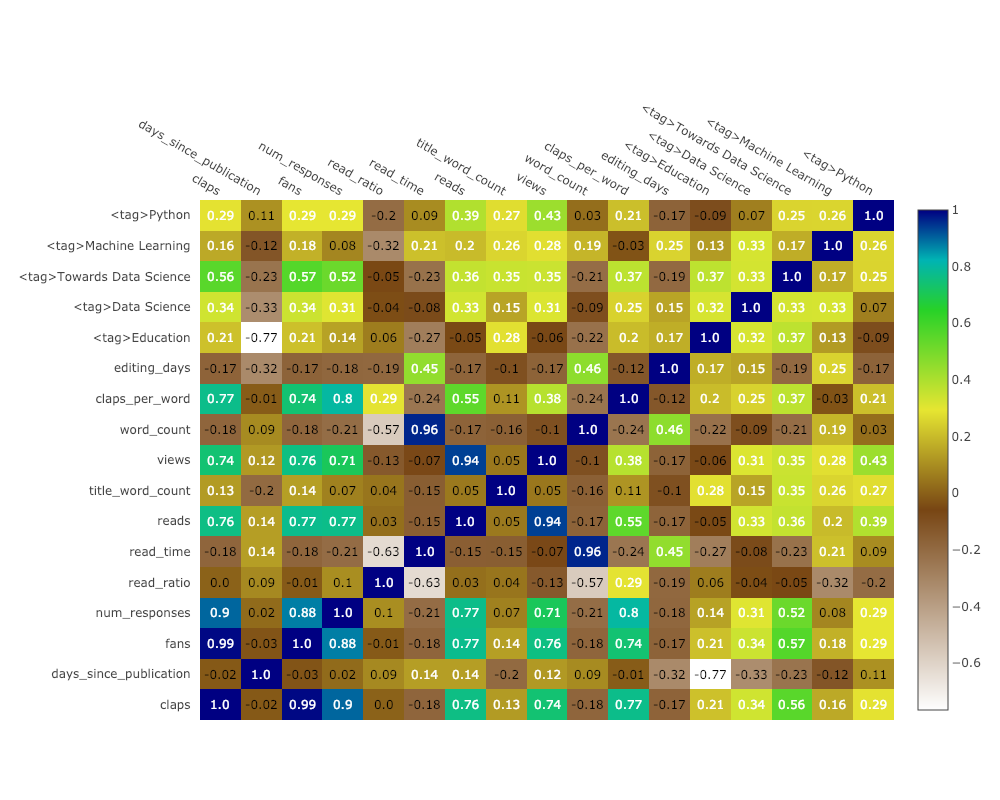
相关热图
为了可视化数值变量之间的相关性,我们计算相关性,然后制作带注释的热图:
corrs = df.corr()
figure = ff.create_annotated_heatmap(
z=corrs.values,
x=list(corrs.columns),
y=list(corrs.index),
annotation_text=corrs.round(2).values,
showscale=True)
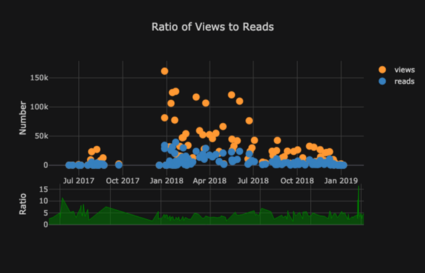
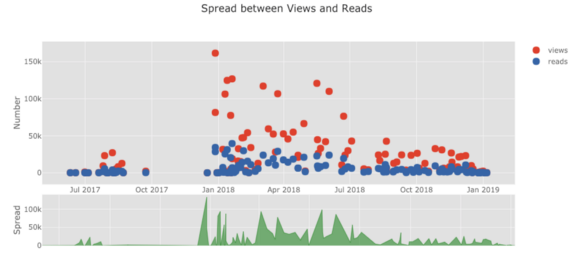
图的列表会不断出现。袖扣还具有几个主题,我们可以使用它们来获得完全不同的外观和感觉。例如,在下面的“空间”主题中有一个比率图,在“ ggplot”中有一个展布图:
我们还获得了3D图(表面图和气泡图):
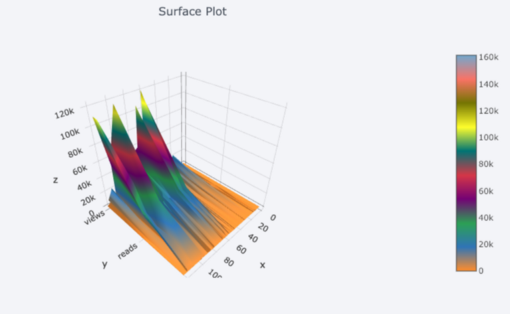
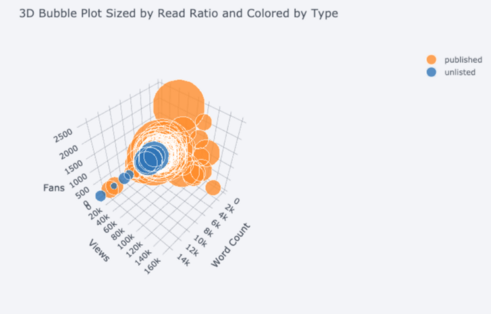
对于那些想要的人,您甚至可以制作饼图:
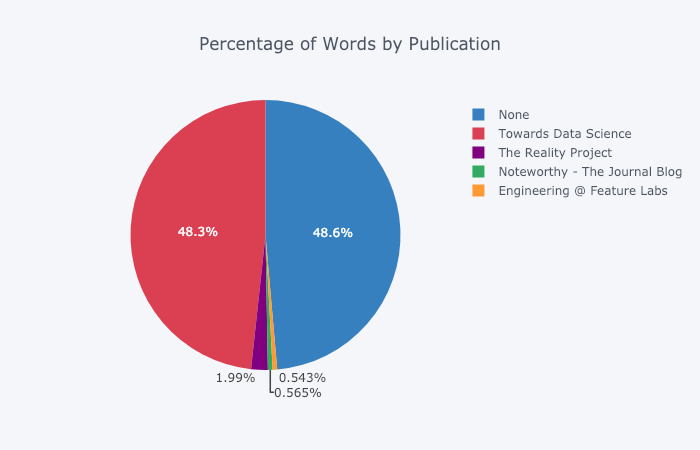
在Plotly Chart Studio中进行编辑
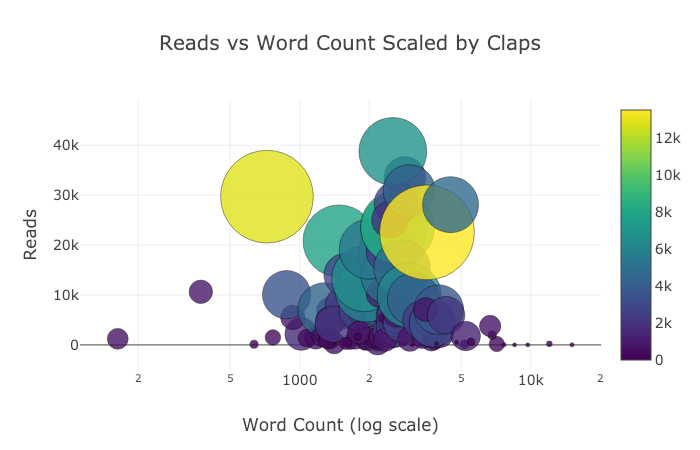
当您在NoteBook Jupiter中制作这些图形时,您会在“导出到plot.ly”图形的右下角看到一个小链接,如果单击此链接,将转到Chart Studio,您可以在其中调整图形以进行最终演示。您可以添加注释,指定颜色,并通常清除所有内容以生成一个精美的图形。然后,您可以在Internet上发布日程安排,以便任何人都可以通过参考找到它。
以下是我在Chart Studio中调整过的两个图形:
尽管这里已经说了什么,但我们仍然没有探索该库的所有功能!我建议您同时查看绘图文档和袖扣文档,以获取更多令人难以置信的绘图。
结论
被低估的误解中最糟糕的部分是,您只会意识到退出后浪费了多少时间。幸运的是,既然我犯了一个错误的事实,那就是与matploblib呆在一起时间太长了,您不必这样做!
当我们考虑绘图库时,我们需要做几件事:
- 一线图快速探索
- 交互式数据替换/探索
- 根据需要挖掘细节的能力
- 易于设置以进行最终演示
目前,在Python中完成所有这些操作的最佳选择是精心设计。通过Plotly,我们可以快速进行可视化,并通过交互性帮助我们更好地理解我们的数据。另外,让我们面对现实吧,图表必须是数据科学中最出色的部分之一!在其他图书馆中,密谋已经变成了一项繁琐的任务,但是在密谋中,有再次造就伟大人物的乐趣!

通过参加SkillFactory的付费在线课程,了解如何从头开始或获得技能和薪资水平提高的详细信息:
- 从头开始培训数据科学专业(12个月)
- 具备任何入门水平的分析专业(9个月)
- 机器学习课程(12周)
- «Python -» (9 )
- DevOps (12 )
- - (8 )