先决条件
在分页的文本中搜索短语的任务被简化为计算每个页面的相关系数,然后按系数的降序对列表进行排序。
在按照基本方法进行计算的过程中,对每个页面进行逐个符号的分析,这是进行优化的可能性。

在计算系数时,将分析搜索字符串和数据的匹配字符组,而只能在单词内形成组。另一方面,考虑到过高估计“长”字的重要性(在第2部分中)的问题,作为一种可能的解决方案,提出了“ 将搜索短语的相关性计算为其中独立包含的单词的相关性的平均值 ”。使用索引将产生与该特定方法等效的结果。
指数
索引的概念并不新颖,其含义如下-由于重复了文本中的单词,因此可以减少计算量。为此,将在其中进行搜索的文本必须首先生成索引。在最简单的情况下,索引是文本中所有单词的表,除单词外,还包含有关它们出现在其上的页面的数据。索引表的片段基于L.N.图中显示了托尔斯泰的《战争与和平》(总共包含约5万个单词)。

直接在处理请求的过程中,首先将搜索字符串分解为单词。此外,对于搜索字符串中的每个单词,与索引中的每个单词都计算相关性。计算结果累积在包含“搜索字符串词”,“索引词”,“相关因子”,“页码”列的初步结果表。该表仅包含索引的那些行,即单词已超过指定阈值的相关系数。即,具有匹配词的索引的每一行都会在初步结果表中生成与该词出现在其上的文本页数相等的行。以下是搜索短语“ Anna Pavlovna Sherer's晚间” 的初步结果表的一部分。

然后将初步结果表按列数,页码,搜索字符串词,因子进行排序(下降)。

通过遍历排序表的行,对于每个页面和搜索字符串的每个单词,可以识别出该页面中最相关的单词-由于上述排序,这是每个组合页码-搜索字符串单词的第一个单词。其余的行将合并丢弃。
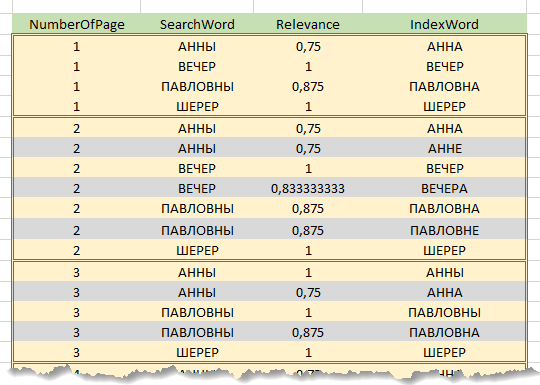
因此,对于初步结果表中包括的每一页文本,对于搜索字符串中的每个单词,将找到该页面中最相关的单词以及相应的系数。在页面上找到的单词系数之和,即搜索栏中单词的数量,将得出该页面的相关系数。

例如,在上图中,搜索是通过行“ Anna Pavlovna Sherer的晚上”执行的(不考虑介词“ y”),以灰色突出显示的行在旁路过程中被丢弃。第1页的相关系数将是(0.75 + 1 + 0.875 + 1)/ 4 = 0.906,第2页-0.906,第3-0.75。
好处
如果不考虑在索引花费帐户时,其结果被重用,并考虑到计算,评估其在转载的总金额部分1,数据串的长度的倍数:
 ;
;
我们可以说使用索引获得的收益将是比率的倍数:
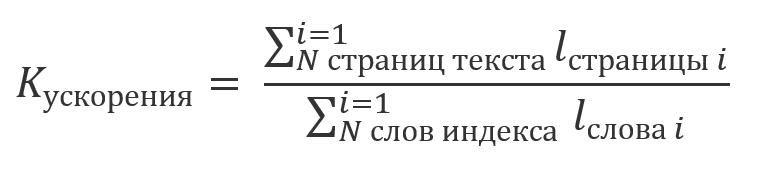
例如,在演示摊位textradar.ru上,小说“战争与和平”的文本分为1488页,每页2000个字符。由52156个元素组成的索引词中的符号总数为434060。也就是说,从索引中获得的收益约为7:

由于使用索引获得的结果与使用前述方法之一获得的结果等同,而没有索引,因此可以共同处理文本的索引和未索引部分的搜索结果。由于索引是一个相对昂贵的操作,并且通常按计划执行,因此有可能对部分文本进行了索引,而某些文本尚未被索引。在这种情况下,节省的计算量将是索引文本在其总大小中所占份额的倍数:
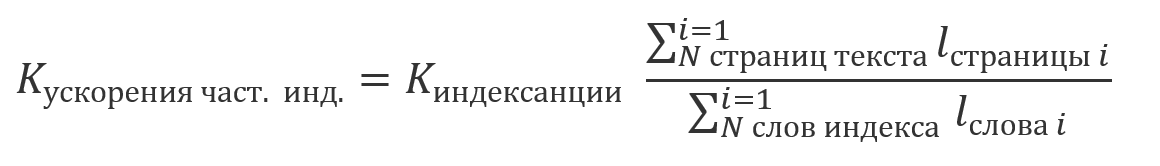
除了提高搜索速度外,使用索引还提供了许多其他可能性。例如,使用从索引获得的统计信息,您可以提高稀有词的重要性,并突出显示在其中经常发现搜索词的重要词的文本页面。您还可以使用同义词扩展索引表。
这结束了致力于TextRadar描述的出版物发行周期。谢谢大家的关注和宝贵的意见,这些意见和建议使我们比原定计划更进一步。
在网站textradar.ru上部署的演示台上可以看到应用上述方法的结果。可以在此处找到实现(C#ASP.NET MVC)。