
美好的一天。我们的名字叫Tatiana Voronova和Elvira Dyaminova,我们在2M中心从事数据分析。特别是,我们训练神经网络模型来检测图像中的物体:人,专用设备,动物。
在每个项目的开始,公司与客户就可接受的识别质量进行协商。这种质量水平不仅必须在项目交付时得到保证,而且还必须在系统的进一步运行期间保持。事实证明,有必要不断监视和培训系统。我想减少此过程的成本并摆脱常规程序,从而腾出时间来从事新项目。
自动再培训不是一个唯一的主意,许多公司都有类似的内部管道工具。在本文中,我们想分享我们的经验,并表明,要成为一家成功实施此类实践的大公司根本没有必要。
我们的项目之一是排队的人数。由于客户是一家拥有大量分支机构的大公司,因此某些时段的人员会按计划聚集,即定期检测到大量对象(人头)。因此,我们决定针对此任务开始实施自动再培训。
这就是我们的计划。除划线员的工作外,所有项目均以自动模式执行:
- 每月一次,将自动选择上周的所有相机图像。
- xls- sharepoint, - : « ».
- ( ) – xml- ( ), – .
- « ». xls- ( – , – ). «». , , .
, : (, ) , , (, - ). -. - xls- «» > 0. , ( ). , . , , « ». , . , . , , .
- «» 0, – - .
- , , , , . , .
最后,这个过程对我们有很大帮助。当许多头突然被“掩盖”时,我们跟踪了II型错误的增加,及时用一种新型的头丰富了训练数据集并重新训练了当前模型。另外,这次旅行可以让您考虑到季节性。我们会根据当前情况不断调整数据集:人们经常戴帽子,或者相反,几乎每个人都没有帽子就可以进入学校。秋天,戴头巾的人数增加。系统变得更加灵活,并对情况做出反应。
例如,在下面的图像中-分支之一(在冬季),其框架未出现在训练数据集中:
如果我们计算该帧的度量标准(TP = 25,FN = 3,FP = 0),那么事实证明召回率为89%,精度为100%,准确性和完整性之间的谐波平均值约为94。 2%(关于下面的指标)。一个新房间的结果不错。
我们的训练数据集同时包含大写字母和大写字母,因此模型并没有引起混淆,但是随着蒙版模式的出现,它开始出现错误。在大多数情况下,当头部清晰可见时,就不会出现问题。但是,如果一个人离摄像机很远,则在一定角度下,该模型将停止检测头部(左图是旧模型工作的结果)。多亏了半自动标记,我们得以修复此类情况并及时重新训练模型(正确的图像是新模型的结果)。

Lady close:

在测试模型时,我们选择了不参与训练的框架(一个具有不同人数,不同角度和不同大小的框架的数据集),以评估模型的质量,我们使用了召回率和精度。
回想一下 -完整性显示了我们正确预测的真正属于肯定类别的对象的比例。
精度 -精度表明我们正确预测了被识别为阳性类别的对象的比例。
当客户需要一个数字,精度和完整性的组合时,我们提供谐波均值或F量度。了解有关指标的更多信息。
经过一个周期,我们得到了以下结果:
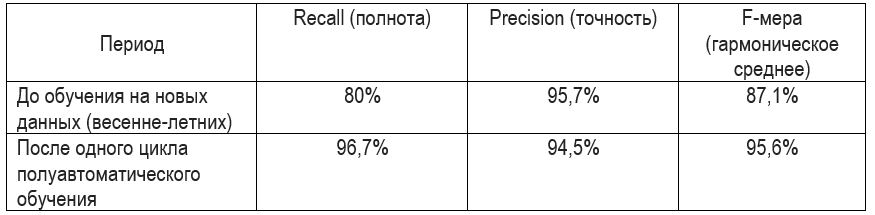
进行任何更改之前80%的完整性是由于在系统中添加了大量新部门,因此出现了新视图。此外,季节已经改变;在此之前,训练数据集中出现了“秋冬人”。
在第一个周期之后,完整性变为96.7%。与第一篇文章相比,其完整性达到了90%。这种变化是由于以下事实造成的:现在各部门的人数有所减少,彼此之间的重叠开始减少了很多(笨重的羽绒服已经用完了),帽子种类也有所减少。
例如,之前的人数与下图中的人数大致相同。

现在就是这样。

总结一下,让我们列举一下自动化的优势:
- 标记过程的部分自动化。
- ( ).
- ( ).
- . .
- . , .
缺点是标记设计者的人为因素-他可能对标记没有足够的责任,因此标记重叠或使用黄金集会导致标记-具有预定答案(仅用于控制标记质量)的任务是必需的。在许多更复杂的任务中,分析人员必须亲自检查标记-在此类任务中,自动模式将不起作用。
一般而言,自动再培训的实践已被证明是可行的。这种自动化可以被认为是允许在系统的进一步操作期间将识别质量维持在良好水平的附加机制。
文章作者:Tatiana Voronova(特沃罗诺娃),Elvira Dyaminova(埃尔维拉)