
本文介绍了导致Slack在2020年5月12日崩溃的问题的技术细节。有关响应该事件的更多信息,请参阅Ryan Katkov 的年表,“双手放在遥控器上”。
2020年5月12日,Slack经历了很长时间以来的首次重大崩溃。不久,我们发布了该事件的摘要,但这是一个非常有趣的故事,因此,我们希望更详细地介绍技术细节。
用户注意到了太平洋时间下午4:45的停机时间,但故事实际上是在上午8:30左右开始的。数据库可靠性工程团队收到有关部分基础架构负载显着增加的警告。同时,流量小组收到警告,我们未发出一些API请求。
数据库负载增加是由新配置的部署引起的,这导致了长期的性能错误。很快发现并回滚了更改-这是一个功能进行逐步部署的标志,因此该问题得以快速解决。该事件对客户影响不大,但仅持续了三分钟,在这段短暂的早晨故障中,大多数用户仍然能够成功发送消息。
该事件的后果之一是我们的主要Web应用程序层的显着扩展。我们的首席执行官Stuart Butterfield撰写了有关隔离和自我隔离对Slack使用情况的一些影响的文章。由于大流行,我们在Web应用程序级别启动的实例明显多于今年2月。我们在工作程序加载时迅速扩展,就像这里发生的那样-但是工作程序等待了更长的时间才能完成一些数据库查询,这导致了更高的负载。在事件发生期间,我们将实例数量增加了75%,从而使我们迄今为止运行的Web应用程序主机数量最多。
在接下来的8个小时里,一切似乎都运行正常-直到突然出现大量的HTTP 503错误。我们启动了一个新的事件响应渠道,值班的Web应用程序工程师手动增加了Web应用程序的数量,以此作为最初的缓解措施。奇怪的是,它根本没有帮助。我们很快注意到,某些Web应用程序实例的负载很重,而其余的则不是。许多研究已经开始研究Web应用程序的性能和负载平衡。几分钟后,我们确定了问题所在。
第4层负载平衡器的背后是一组HAProxy实例,用于将请求分发到Web应用程序层。我们使用Consul进行服务发现,并使用consul模板呈现HAProxy应该将请求路由到的健康Web应用程序后端列表。
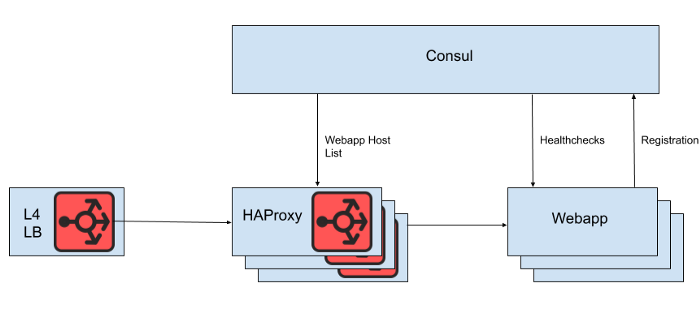
图。 1. Slack负载平衡体系结构的高级视图
但是,我们不直接从HAProxy配置文件中呈现Web应用程序主机列表,因为在这种情况下更新列表需要重新启动HAProxy。 HAProxy重新启动过程涉及创建一个全新的过程,同时保留旧的过程,直到完成对当前请求的处理为止。频繁重启会导致太多的HAProxy进程运行并降低性能。此限制与自动缩放Web应用程序层的目标相冲突,该目标是使新实例尽快投入生产。因此,我们正在使用 HAProxy Runtime API管理HAProxy服务器的状态,而无需每次Web层服务器进出时都重新启动。值得注意的是,HAProxy可以与Consul DNS接口集成,但这会增加DNS TTL带来的延迟,限制Consul标签的使用,并且管理非常大的DNS响应通常会导致痛苦的边缘情况和错误。

图。 2.如何在单个Slack HAProxy服务器上管理一组Web应用程序后端
在我们的HAProxy状态下,我们为 HAProxy服务器定义模板。实际上,这些是Web应用程序后端可以占用的“插槽”。当新的Web应用程序的一个实例推出或旧的Web应用程序的实例开始失败时,将更新Consul服务目录。 Consul模板会打印出主机列表的新版本,并且在Slack中开发的单独的haproxy-server-state-management程序将读取该主机列表,并使用HAProxy Runtime API来更新HAProxy状态。
我们在单独的AWS可用区中运行M个并发HAProxy实例池和Web应用程序池。 HAProxy为每个AZ中的Web应用程序后端配置了N个“插槽”,从而提供了总共N * M个可以定向到所有AZ的后端。几个月前,这个数字已绰绰有余-我们从未推出过与我们的Web应用程序层那么多实例相近的产品。但是,在早上发生数据库事件后,我们启动了N * M个Web应用程序实例。如果您将HAProxy插槽视为一个巨大的椅子游戏,那么其中一些webapp实例将没有空间。这不是问题-我们拥有足够的服务能力。
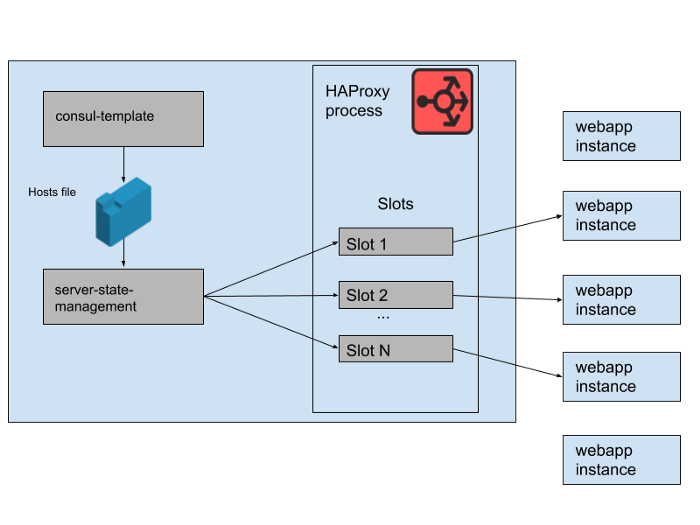
图。 3. HAProxy进程中的“插槽”,其中一些冗余Web应用程序实例未接收到流量
但是,白天存在问题。程序中存在一个错误,该错误将领事模板生成的主机列表与HAProxy服务器的状态同步。该程序始终尝试为新的Webapp实例找到一个插槽,然后再释放由旧的Webapp实例占用的不再可用的插槽。该程序开始抛出错误并提早退出,因为它找不到任何空插槽,这意味着正在运行的HAProxy实例未更新其状态。随着一天的过去,webapp自动扩展组不断壮大,并且HAProxy状态的后端列表变得越来越陈旧。
在下午4:45,大多数HAProxy实例只能将请求发送到早上可用的一组后端,而这组旧的Webapp后端现在已是少数。我们会定期提供新的HAProxy实例,因此有一些新的HAProxy实例配置正确,但是大多数实例的使用时间都超过了8个小时,因此后端处于完整且过时的状态。最终,服务崩溃了。这是在美国工作日结束时发生的,因为那是我们在流量减少时开始扩展Web应用程序层的时候。自动缩放首先会关闭旧的Webapp实例,这意味着在HAProxy的服务器状态下没有足够的实例来满足需求。
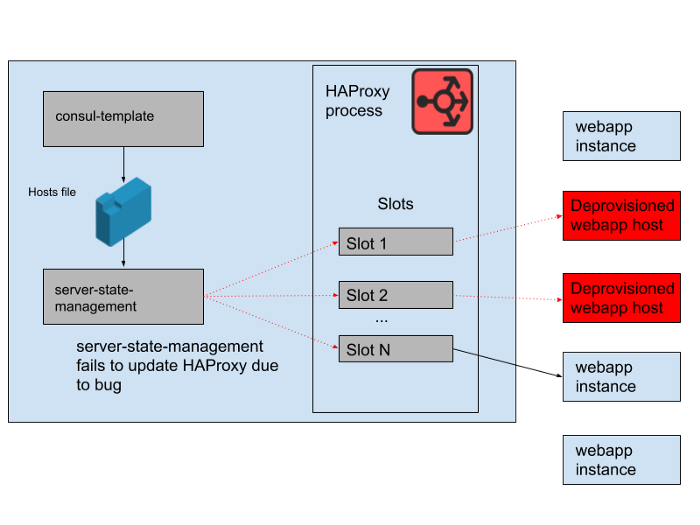
图。 4. HAProxy的状态随时间变化,并且插槽主要针对远程主机,
一旦我们找出了故障的原因,就可以通过平稳地重新启动HAProxy队列来快速解决。之后,我们立即提出一个问题:为什么监控没有解决这个问题。我们为这种特定情况提供了一个警报系统,但不幸的是,该系统未能按预期工作。没有注意到监视失败,部分原因是该系统已“正常运行”了很长时间并且不需要任何更改。该应用程序所属的更广泛的HAProxy部署也是相对静态的。随着变化的速度变慢,与监视和警报基础架构进行交互的工程师数量将减少。
我们没有对这个HAProxy堆栈进行太多修改,因为我们正在逐步将所有负载平衡转移到Envoy(我们最近将Websocket流量移到了它)。 HAProxy多年来一直运行良好且可靠,但是在此事件中仍存在一些操作问题。我们将自己的Envoy与xDS控制平面的集成(用于端点发现)替换用于管理HAProxy服务器状态的复杂管道。 HAProxy的最新版本(从2.0版开始)也解决了许多这些操作问题。尽管如此,我们已经将Envoy与内部服务网格信任了一段时间,因此我们也努力将负载平衡转移给它。我们对Envoy + xDS的大规模初始测试看起来很有希望,并且这种迁移将在将来提高性能和可用性。新的负载平衡和服务发现体系结构可以避免导致此故障的问题。
我们努力保持Slack的可访问性和可靠性,但是在这种情况下,我们失败了。对于我们的用户而言,Slack是必不可少的工具,这就是为什么我们努力从每个事件中学习,无论客户是否注意到它。对于由此造成的不便,我们深表歉意。我们承诺将利用这些知识来改善我们的系统和流程。