Ab Initio具有许多经典和不同寻常的转换,可以使用其自己的PDL进行扩展。对于小型企业而言,这种功能强大的工具可能是多余的,并且其大多数功能可能昂贵且不必要。但是,如果您的规模接近Sberbank的规模,那么Ab Initio对您可能会很有趣。
它可以帮助企业在全球范围内积累知识并开发生态系统,而开发人员-可以在ETL中提升其技能,在Shell中积累知识,提供掌握PDL语言的能力,提供加载过程的可视化画面,由于功能部件丰富而简化了开发过程。
在这篇文章中,我将讨论Ab Initio的功能,并提供其与Hive和GreenPlum的比较特性。
- MDW GreenPlum
- Ab Initio Hive GreenPlum
- Ab Initio GreenPlum Near Real Time
该产品的功能非常广泛,需要大量时间来学习。但是,凭借适当的工作技能和正确的性能设置,数据处理结果令人印象深刻。为开发人员使用Ab Initio可以给他带来有趣的体验。这是ETL开发的新思路,它是一种可视环境和一种脚本语言在下载开发之间的混合体。
商业发展了其生态系统,该工具比以往任何时候都更方便使用。在Ab Initio的帮助下,您可以积累有关当前业务的知识,并使用这些知识来扩展旧业务和开新业务。可以从可视开发环境Informatica BDM和非可视环境-Apache Spark中调用Ab Initio的替代方案。
从头开始的描述
与其他ETL工具一样,Ab Initio是一组产品。

Ab Initio GDE(图形开发环境)是供开发人员使用的环境,他在其中设置数据转换并将其与箭头形式的数据流连接。在这种情况下,这样的一组转换称为图形:

功能组件的输入和输出连接是端口,并且包含在转换内计算的字段。通过流以箭头的形式按流的顺序连接的几个图形称为计划。
有数百个功能组件,这很多。他们中的许多人都是高度专业的。 Ab Initio具有比其他ETL工具更大的经典转换范围。例如,Join具有多个输出。除了连接数据集的结果外,您还可以通过无法连接的键获得输入数据集的输出记录。您还可以获取转换操作的拒绝,错误和日志,这些操作可以与文本文件在同一列中读取并由其他转换处理:

例如,您可以以表格的形式实现数据接收器并在同一列中读取数据。
有原始的转换。例如,扫描转换具有与分析功能相同的功能。有一些具有不解释名称的转换:创建数据,读取Excel,规范化,在组中排序,运行程序,运行SQL,与DB联接等。图形可以使用运行时参数,包括从操作系统或向操作系统传输参数。 ...将具有现成参数集的文件传递给图形的文件称为参数集(psets)。
不出所料,Ab Initio GDE有自己的存储库,称为EME(企业元环境)。开发人员可以使用本地版本的代码,并可以将其开发签入中央存储库。
在执行图形期间或执行图形之后,可以单击连接转换的任何流,并查看在这些转换之间传递的数据:

还可以单击任何流,并查看跟踪详细信息-转换工作的并行度,行数和字节数。加载并行:

可以将图形的执行分为多个阶段,并标记应首先执行一些转换(在阶段0中),然后在第一阶段中执行,然后在第二阶段中进行,依此类推。
对于每个转换,您可以选择所谓的布局(将在其中执行):不使用并行或并行线程,可以设置其数量。同时,可以将Ab Initio在转换工作期间创建的临时文件放置在服务器文件系统和HDFS中。
在每个转换中,都可以基于默认模板,以PDL语言创建自己的脚本,有点像shell。
借助PDL语言,您可以扩展转换的功能,尤其是可以根据运行时参数动态地(在运行时)生成任意代码片段。
另外,Ab Initio通过外壳与OS进行了完善的集成。具体来说,Sberbank使用linux ksh。您可以与shell交换变量并将其用作图形参数。您可以从外壳调用Ab Initio图的执行并管理Ab Initio。
除了Ab Initio GDE,交货还包括许多其他产品。有一个Co>操作系统,声称它是操作系统。在“控制”>“中心”中,您可以计划和监视下载流。有一些产品可以进行比Ab Initio GDE所允许的更原始的开发。
描述MDW框架并为GreenPlum定制它
供应商与其产品一起提供产品MDW(元数据驱动的仓库),它是一种图形配置器,旨在帮助完成填充数据仓库或数据仓库的典型任务。
它包含自定义(特定于项目的)元数据解析器和开箱即用的代码生成器。
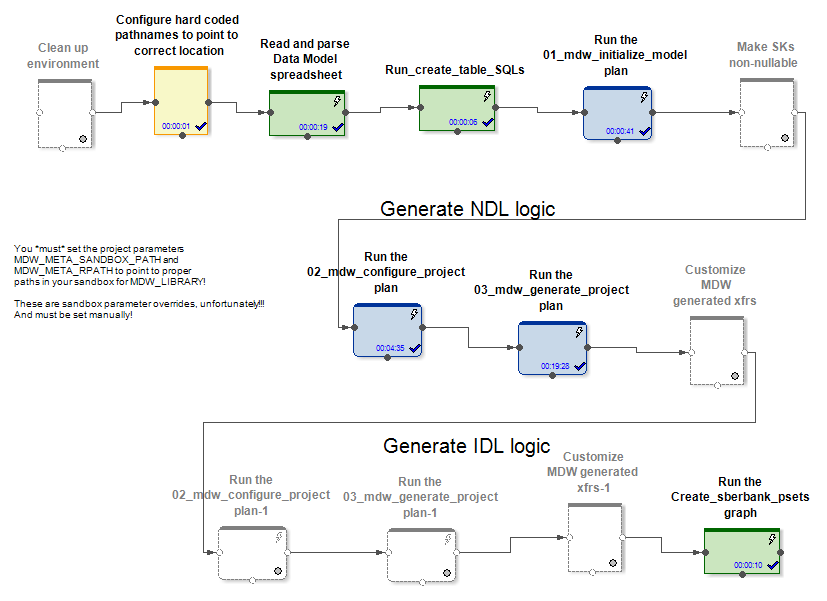
在入口处,MDW会接收数据模型,用于建立数据库连接(Oracle,Teradata或Hive)的配置文件以及其他一些设置。例如,特定于项目的部分将模型部署到数据库。在将数据加载到模型表中时,产品的带框部分为它们生成图形和配置文件。这将为初始化和增量更新实体的几种工作模式创建图形(和pset)。
在Hive和RDBMS情况下,将生成不同的初始化和增量数据刷新图。
对于Hive,传入的增量数据由Ab Initio Join连接到更新之前表中的数据。 MDW中的数据加载器(在Hive和RDBMS中)不仅从增量中插入新数据,而且还关闭了接收其增量的主键的数据有效期。另外,您必须重写数据的未更改部分。但是必须这样做,因为Hive没有删除或更新操作。
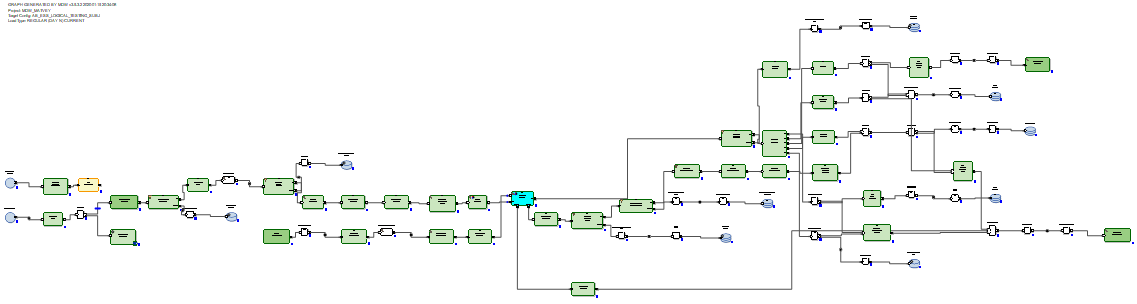
对于RDBMS,由于RDBMS具有真正的更新功能,因此增量数据更新图看起来更为理想。
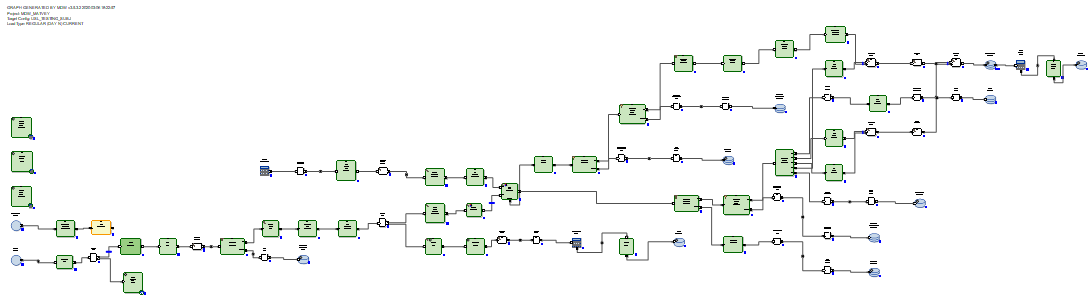
收到的增量将被加载到数据库的登台表中。之后,将增量连接到更新之前表中的数据。这是通过生成的SQL查询通过SQL来完成的。然后,使用delete + insert SQL命令,将来自增量的新数据插入到目标表中,并根据接收到增量的主键关闭数据的相关时间段。
无需重写不变的数据。
因此,我们得出的结论是,在Hive的情况下,MDW应该去重写整个表,因为Hive没有更新功能。没有什么比没有发明更新时完全重写数据更好的了。相反,对于RDBMS,产品的创建者认为有必要使用SQL委托表的连接和更新。
对于Sberbank的一个项目,我们创建了GreenPlum数据库加载器的新可重用实现。这是根据MDW为Teradata生成的版本完成的。最佳和最接近的是Teradata,而不是Oracle。也是MPP系统。事实证明,工作方式以及Teradata和GreenPlum的语法相似。
以下是不同RDBMS之间MDW的关键差异示例。在GreenPlum中,与Teradata不同,在创建表时,您需要编写一个子句
distributed byTeradata写道
delete <table> all,并在GreenePlum中编写
delete from <table>Oracle为优化而写
delete from t where rowid in (< t >),Teradata和GreenPlum编写
delete from t where exists (select * from delta where delta.pk=t.pk)我们还注意到,要使Ab Initio与GreenPlum一起使用,就需要在Ab Initio群集的所有节点上安装GreenPlum客户端。这是因为我们已经从集群中的所有节点同时连接到GreenPlum。并且为了使从GreenPlum的读取是并行的,并且每个并行的Ab Initio线程从GreenPlum读取其自己的数据部分,有必要将Ab Initio理解的构造放在SQL查询的“ where”部分中
where ABLOCAL()并通过指定从转换数据库读取的参数来确定此构造的值
ablocal_expr=«string_concat("mod(t.", string_filter_out("{$TABLE_KEY}","{}"), ",", (decimal(3))(number_of_partitions()),")=", (decimal(3))(this_partition()))»编译成类似
mod(sk,10)=3,即 您必须告诉GreenPlum每个分区一个明确的过滤器。对于其他数据库(Teradata,Oracle),Ab Initio可以自动执行此并行化。
Ab Initio与Hive和GreenPlum合作的比较性能特征
在Sberbank进行了一项实验,比较了MDW生成的图表相对于Hive和GreenPlum的性能。作为实验的一部分,在Hive的情况下,与Ab Initio在同一群集中有5个节点,在GreenPlum的情况下,在单独的群集中有4个节点。那些。Hive比GreenPlum具有一些硬件优势。
我们查看了两对图,它们执行与Hive和GreenPlum中的数据更新相同的任务。启动了由MDW配置器生成的图形:
- 初始化加载+将随机生成的数据增量加载到Hive表中
- 初始化加载+将随机生成的数据增量加载到同一GreenPlum表中
在这两种情况下(Hive和GreenPlum)都在同一Ab Initio群集上的10个并行线程中启动下载。Ab Initio保存了中间数据,以便在HDFS中进行计算(就Ab Initio而言,使用了使用HDFS的MFS布局)。在这两种情况下,一行随机生成的数据都占用200个字节。
结果是这样的:
Hive:
| 在Hive中初始化加载 | |||
| 插入行 | 6,000,000 | 60,000,000 | 600,000,000 |
| 初始化
加载的持续时间(以秒为单位) |
41 | 203 | 1601 |
| Hive中的增量加载 | |||
|
实验开始时目标表中的行数 |
6,000,000 | 60,000,000 | 600,000,000 |
|
实验期间应用于目标表的增量行数 |
6,000,000 | 6,000,000 | 6,000,000 |
| 增量
下载持续时间(以秒为单位) |
88 | 299 | 2541 |
GreenPlum:
| GreenPlum | |||
| 6 000 000 | 60 000 000 | 600 000 000 | |
|
|
72 | 360 | 3 631 |
| GreenPlum | |||
| ,
|
6 000 000 | 60 000 000 | 600 000 000 |
| ,
|
6 000 000 | 6 000 000 | 6 000 000 |
|
|
159 | 199 | 321 |
我们看到,在Hive和GreenPlum中初始化下载的速度线性地取决于数据量,并且由于硬件更好的原因,Hive的速度比GreenPlum快一些。
Hive中的增量加载还线性地取决于目标表中先前加载的数据量,并且随着量的增加而变慢。这是由于需要完全覆盖目标表。这意味着对Hive进行小的更改并不是一个好用例。
GreenPlum中的增量加载很少取决于目标表中以前加载的数据量,而且速度非常快。这要归功于SQL Joins和GreenPlum体系结构,该体系结构允许删除操作。
因此,GreenPlum使用delete + insert方法注入增量,而Hive没有删除或更新操作,因此整个数据阵列被迫在增量更新期间重写整个数据阵列。最具指示性的是以粗体突出显示的单元格的比较,因为它对应于资源密集型下载操作的最常见变体。我们看到GreenPlum在这项测试中胜过Hive八次。
从头开始与GreenPlum几乎实时
在此实验中,我们将测试Ab Initio能够近乎实时地使用随机生成的数据块更新GreenPlum表的功能。考虑表GreenPlum dev42_1_db_usl.TESTING_SUBJ_org_finval,我们将使用该表。
我们将使用三个Ab Initio图形进行处理:
1)Create_test_data.mp图形-使用HDFS中的数据为文件创建文件,该文件包含10个并行流中的6,000,000行。数据是随机的,其结构被组织为可插入到我们的表中
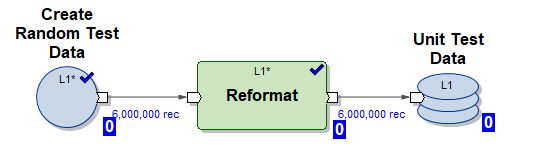

2)图mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset-生成的MDW图,用于初始化将数据插入到10个并行线程中的表中(使用了由图(1)生成的测试数据)

3)图mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset-生成的MDW图,用于使用图生成的一部分新传入数据(增量)在10个并行线程中增量更新表(1)

在NRT模式下运行以下脚本:
- 产生6,000,000条测试线
- 初始化加载,将6,000,000条测试行插入到空表中
- 重复5次增量下载
- 产生6,000,000条测试线
- 在表中增量插入6,000,000条测试行(在这种情况下,旧数据将标有到期时间valid_to_ts,并且将插入具有相同主键的最新数据)
这样的场景模拟了某个业务系统的实际操作模式-相当一部分新数据实时出现并立即注入GreenPlum。
现在让我们看一下脚本的日志:
在2020-06-04 11:49:11启动Create_test_data.input.pset在2020-06-04 11:49:37
完成Create_test_data.input.pset在
mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset在2020年6月4日11时49分三十七秒
,在2020年6月4日十一点50分42秒完成mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset
开始Create_test_data.input.pset在2020年6月4日十一点50分42秒
完成在2020-06-04 11:51:06
创建Create_test_data.input.pset在2020-06-04 11:51:06 启动mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:53:41
Start Create_test_data.input.pset at 2020-06-04 11:53:41
Finish Create_test_data.input.pset at 2020-06-04 11:54:04
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:54:04
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:56:51
Start Create_test_data.input.pset at 2020-06-04 11:56:51
Finish Create_test_data.input.pset at 2020-06-04 11:57:14
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:57:14
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:59:55
在2020-06-04 11:59:55启动Create_test_data.input.pset在2020-06-04 12:00:23
完成Create_test_data.input.pset在2020-06-04
启动mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset 12:00:23
在2020-06-04 12:03:23 完成mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset在2020-06-04 12:03:23
在2020-06-04 12:03:23
完成Create_test_data.input.pset 2020-06-04 12:03:49
在2020-06-04 12:03:49 开始mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset在2020-06-04:12处
完成mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset :46
图片如下:
| 图形 | 开始时间 | 结束时间 | 长度 |
|---|---|---|---|
| Create_test_data.input.pset | 06/04/2020 11:49:11 | 06/04/2020 11:49:37 | 00:00:26 |
| mdw_load.day_one.current。
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:49:37 | 06/04/2020 11:50:42 | 00:01:05 |
| Create_test_data.input.pset | 06/04/2020 11:50:42 | 06/04/2020 11:51:06 | 00:00:24 |
| mdw_load.regular.current。
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:51:06 | 06/04/2020 11:53:41 | 00:02:35 |
| Create_test_data.input.pset | 06/04/2020 11:53:41 | 06/04/2020 11:54:04 | 00:00:23 |
| mdw_load.regular.current。
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:54:04 | 06/04/2020 11:56:51 | 00:02:47 |
| Create_test_data.input.pset | 06/04/2020 11:56:51 | 06/04/2020 11:57:14 | 00:00:23 |
| mdw_load.regular.current。
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:57:14 | 06/04/2020 11:59:55 | 00:02:41 |
| Create_test_data.input.pset | 06/04/2020 11:59:55 | 06/04/2020 12:00:23 | 00:00:28 |
| mdw_load.regular.current。
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 12:00:23 | 2020/06/04下午12:03:23 | 00:03:00 |
| Create_test_data.input.pset | 2020/06/04下午12:03:23 | 06/04/2020 12:03:49 PM | 00:00:26 |
| mdw_load.regular.current。
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 12:03:49 PM | 06/06/2020 12:06:46 PM | 00:02:57 |
我们看到3分钟内处理了6,000,000条增量线,这是非常快的。
事实证明,目标表中的数据分布如下:
select valid_from_ts, valid_to_ts, count(1), min(sk), max(sk) from dev42_1_db_usl.TESTING_SUBJ_org_finval group by valid_from_ts, valid_to_ts order by 1,2;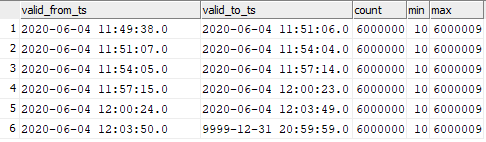
您可以看到插入的数据与图形启动时刻的对应关系。
这意味着您可以以很高的频率开始将数据增量加载到Ab Initio中的GreenPlum中,并观察到将这些数据高速插入GreenPlum中的速度。当然,不可能每秒启动一次,因为Ab Initio和任何ETL工具一样,在启动时会花费一些时间来“摆动”。
结论
现在,Ab Initio在Sberbank中用于构建统一语义数据层(ESS)。该项目涉及构建各种银行业务实体状态的单一版本。信息来自各种来源,其副本在Hadoop上准备。根据业务需求,准备数据模型并描述数据转换。 Ab Initio将信息上载到ECC,并且加载的数据不仅是业务本身的兴趣所在,而且还可以用作构建数据集市的源。同时,该产品的功能允许您将各种系统(Hive,Greenplum,Teradata,Oracle)用作接收器,从而可以轻松地为业务准备所需的各种格式的数据。
Ab Initio的功能广泛,例如,包含的MDW框架使开箱即用地构建技术和业务历史数据成为可能。对于开发人员而言,Ab Initio使得“不重新发明轮子”成为可能,但可以使用许多可用的功能组件,实际上,这些功能组件是处理数据时所需的库。
作者是Sberbank专业社区SberProfi DWH / BigData的专家。专业社区SberProfi DWH / BigData负责Hadoop生态系统,Teradata,Oracle DB,GreenPlum以及BI工具Qlik,SAP BO,Tableau等领域的能力发展。