。
为什么我要为此担心
数据以数据结构的形式存储在内存中,例如对象,列表,数组等。但是,如果要通过网络或文件发送数据,则需要将它们编码为Baytov序列。内存中以字节顺序表示的形式称为编码,逆变换-dekodirovaniem。最终,由应用程序处理或存储在内存中的数据图可能会演变,可能会向starye添加或删除新字段。 使用过的编码必须具有逆向(新的代码必须能够读取数据写入旧的码), 兼容性(旧的代码必须具有支持的能力读取数据编写新的代码)。
在
本文中,我们将讨论各种编码格式,找出为什么二进制编码比JSON,XML更好,以及二进制编码方法支持更改方案
dannyh。
类型格式编码
有两种类型的编码格式:
- 文字格式
- 二进制格式
文字格式
文本格式在某种程度上chelovekochitaemy。常见格式的示例包括JSON,CSV和XML。文本格式易于使用和理解,但是存在某些问题:
- . , XML CSV . JSON , , . . , , 2^53 Twitter, 64- . JSON, API Twitter, ID — JSON- – - , JavaScript- .
- CSV , .
- 文本格式比二进制编码占用更多的空间。例如,原因之一是JSON和XML是无模式的,因此必须包含字段名称。
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}删除所有空格后,此示例的JSON编码占用82个字节。
二进制编码
对于仅在内部使用的数据分析,可以选择更精简或更快速的格式。尽管JSON不如XML冗长,但与二进制格式相比,它们两者仍然占用大量空间。在本文中,我们将讨论三种不同的二进制编码格式:
- 节约
- 协议缓冲区
- 阿夫罗
它们都使用模式提供了有效的数据序列化,并具有生成代码的工具,并支持使用不同的编程语言。它们都支持架构演进,同时提供向后和向前兼容性。
节俭和协议缓冲区
Thrift由Facebook开发,Protocol Buffers由Google开发。在这两种情况下,都需要一个模式来对数据进行编码。Thrift使用自己的接口定义语言(IDL)定义架构。
struct Person {
1: string userName,
2: optional i64 favouriteNumber,
3: list<string> interests
}
协议缓冲区的等效方案:
message Person {
required string user_name = 1;
optional int64 favourite_number = 2;
repeated string interests = 3;
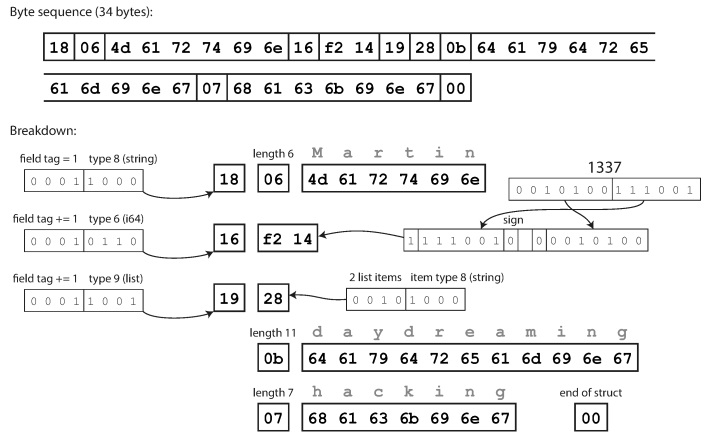
}如您所见,每个字段都有一个数据类型和标签号(1、2和3)。 Thrift具有两种不同的二进制编码格式:BinaryProtocol和CompactProtocol。二进制格式很简单,如下所示,它需要59个字节才能对上面的数据进行编码。
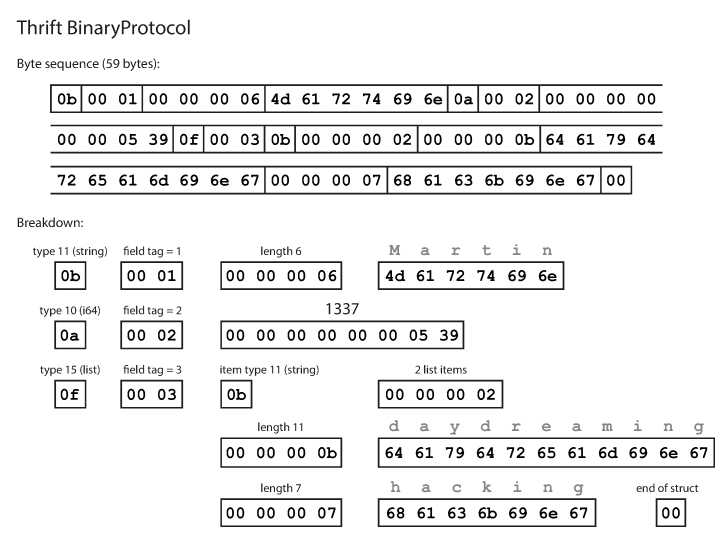
使用Thrift二进制协议进行编码
紧凑协议在语义上等效于二进制,但是将相同的信息打包为34个字节。通过将字段类型和标签号打包到一个字节中可以节省成本。
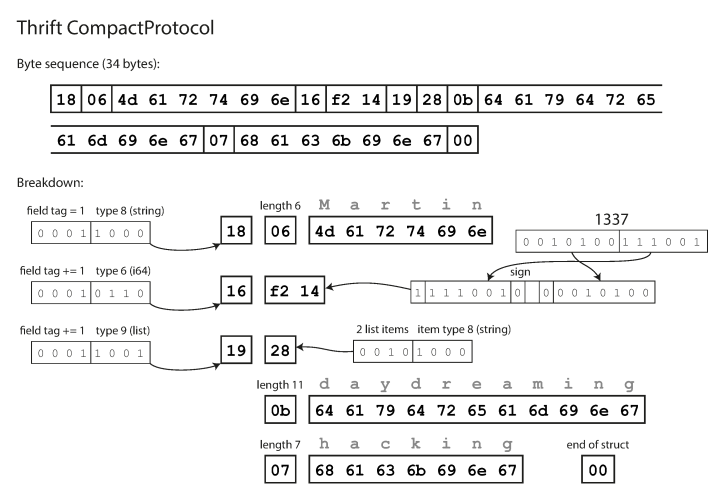
使用Thrift紧凑
协议缓冲区进行编码以类似于Thrift的紧凑协议的方式对数据进行编码,并且在编码后,相同数据为33字节。
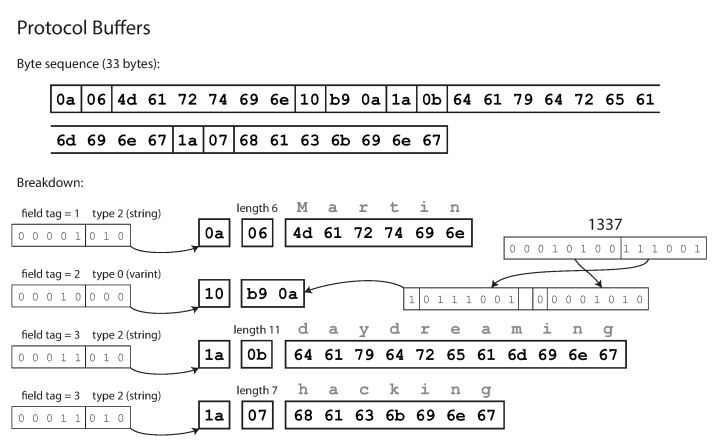
使用协议缓冲区编码
标签号支持节俭和协议缓冲区中模式的演变。如果旧代码尝试读取用新模式编写的数据,它将简单地忽略具有新标签号的字段。同样,新代码可以通过将缺失标签编号的值标记为null来读取以旧方案编写的数据。
阿夫罗
Avro与协议缓冲区和节流协议不同。Avro还使用架构定义数据。可以使用Avro IDL(人类可读格式)定义架构:
record Person {
string userName;
union { null, long } favouriteNumber;
array<string> interests;
}
或JSON(一种更具机器可读性的格式):
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favouriteNumber", "type": ["null", "long"]},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}
请注意,这些字段没有标签编号。用Avro编码的相同数据仅占用32个字节。
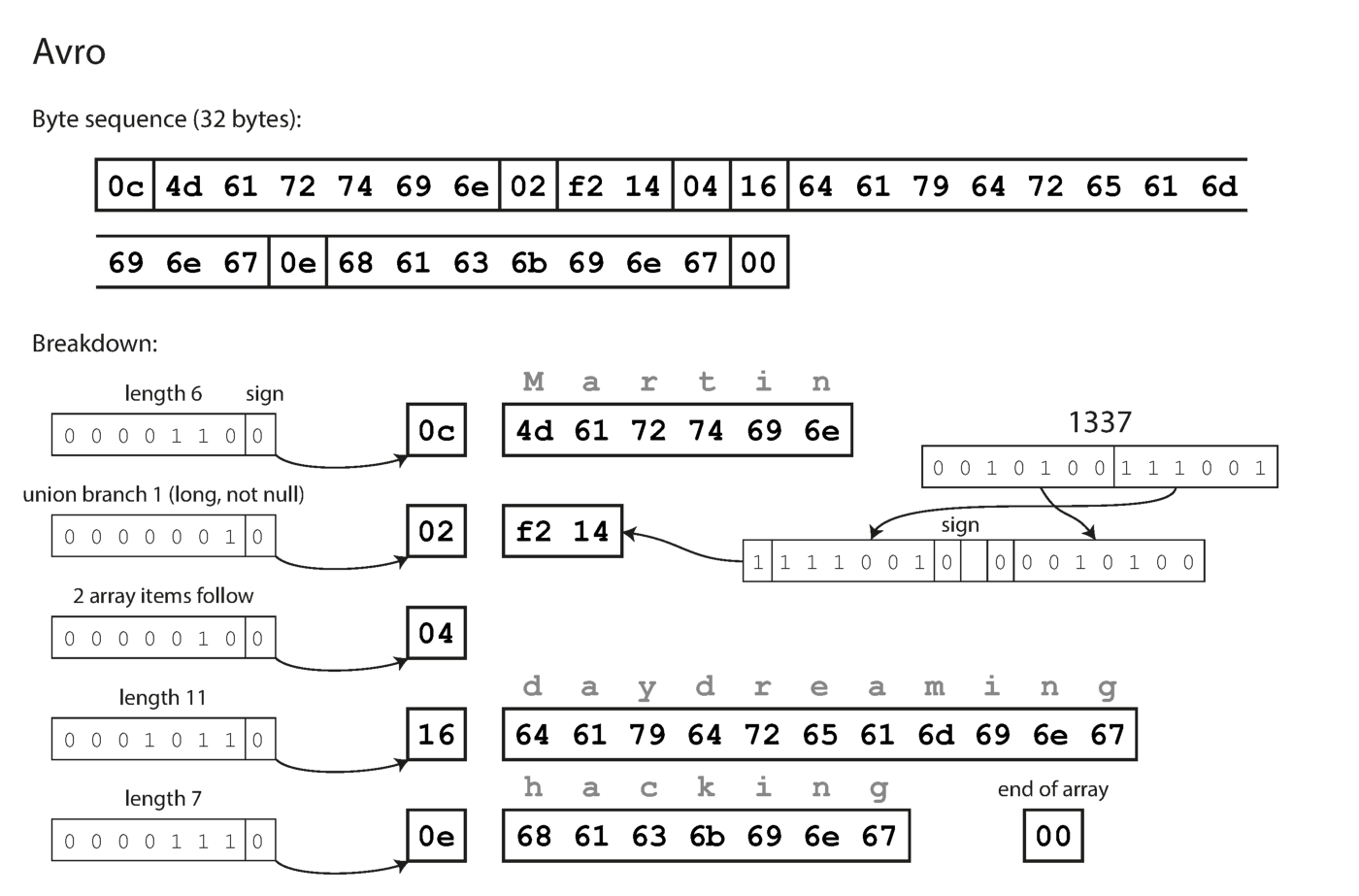
用Avro编码。
从上述字节序列可以看出,无法识别字段(为此在Thrift和Protocol Buffers标签中使用了数字),也无法确定字段的数据类型。价值观简单地放在一起。这是否意味着在解码过程中对电路的任何更改都会产生不正确的数据? Avro的关键思想是,用于写入和读取的架构不必相同,但必须兼容。解码数据时,Avro库通过查看两个电路并将数据从记录器电路转换到读取器电路来解决此问题。
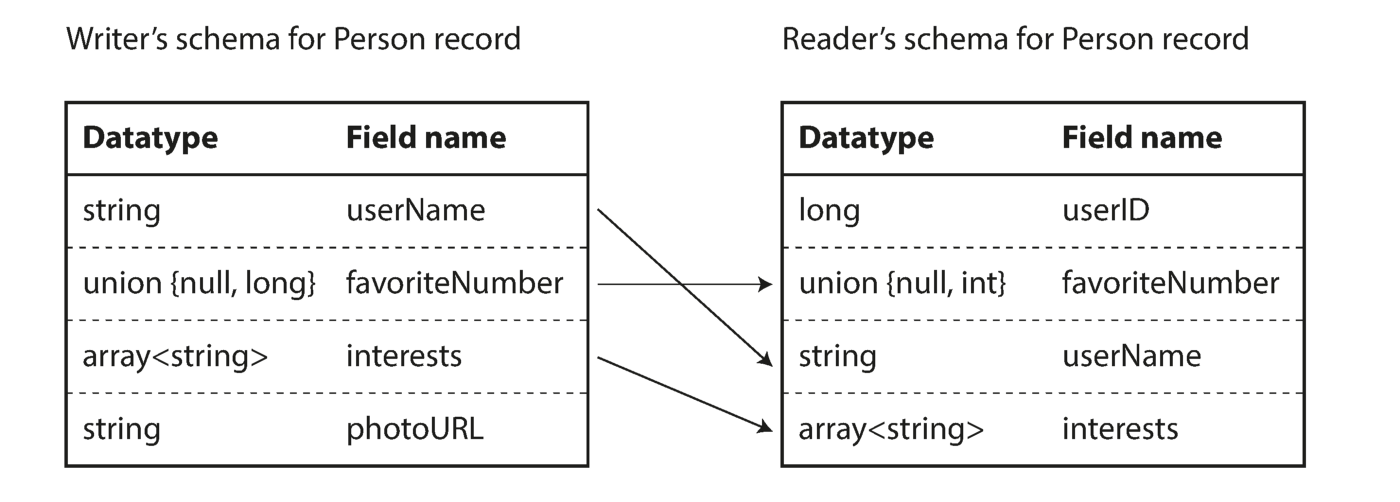
消除读取器和写入器电路之间的差异
您可能正在考虑读取器如何学习写入器电路。这全都与编码使用场景有关。
- 当传输大文件或数据时,记录器可能会将电路包含在文件的开头一次。
- 在具有单独记录的数据库中,每一行都可以使用自己的架构来编写。最简单的解决方案是在每个条目的开头都包含一个版本号,并保留一个模式列表。
- 为了通过网络发送记录,建立连接后,读取器和写入器可以就模式达成一致。
使用Avro格式的主要优点之一是支持动态生成的架构。由于未生成编号标签,因此可以使用版本控制系统来存储使用不同方案编码的不同条目。
结论
在本文中,我们研究了文本和二进制编码格式,讨论了相同的数据如何用JSON编码占用82个字节,用Thrift和Protocol Buffer编码占用33个字节,而使用Avro编码仅占用32个字节。在后端服务之间通过网络传输数据时,二进制格式相对于JSON具有几个明显的优势。
资源资源
要了解有关编码和设计数据密集型应用程序的更多信息,我强烈建议阅读Martin Kleppman的《设计数据密集型应用程序》。

通过完成SkillFactory付费在线课程,了解如何从头开始或成为技能和薪资水平升级的热门职业的详细信息:
- 机器学习课程(12周)
- 从头开始培训数据科学专业(12个月)
- 具备任何入门水平的分析专业(9个月)
- 用于Web开发的Python(9个月)