
在这里,您可以找到6月份用英语发布的材料清单。它们都是在没有过多学术性的情况下编写的,其中包含代码示例以及指向非空存储库的链接。提到的大多数技术都是公共领域的,不需要重型硬件进行测试。
图片GPT
Open AI决定,由于在文本上训练的变形模型可以生成连贯的完整句子,因此,如果在像素序列上训练模型,则可以生成增强的图像。 Open AI演示了高质量的采样和准确的图像分类如何使生成的模型与无监督学习环境中的最佳卷积模型竞争。

面部去像素器
一个月前,我们有机会使用该工具,它使用机器学习模型将人像转化为美丽的像素艺术。这很有趣,但是很难想象这种技术的广泛使用。但是产生相反效果的工具立即引起了公众的兴趣。理论上,借助面部去像素器,可以通过室外监控摄像头的视频记录来确定人的身份。

DeepFaceDrawing
如果处理像素图像还不够,并且您需要使用原始素描中的人物肖像来构图,那么为此已经出现了基于DNN的工具。根据创作者的构想,只需要一般轮廓,而无需专业草图-然后,模型本身将还原人的脸部,从而与草图重合。该系统是使用Jittor框架创建的,正如创建者所承诺的那样,Pytorch的源代码将很快添加到项目存储库中。
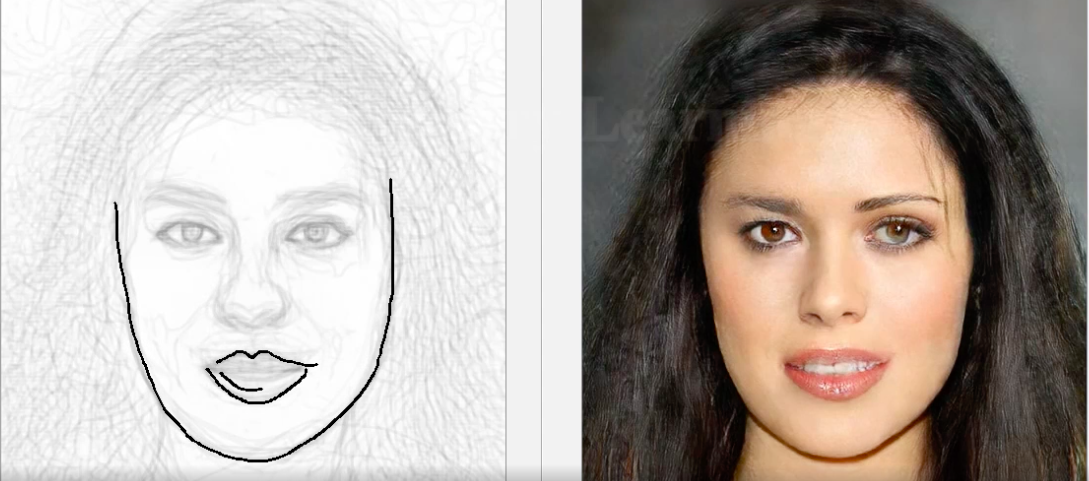
高清
面部重建后,身体其余部分又如何呢?由于DNN的发展,可以基于二维照片对人物进行3D建模。主要限制是由于这样一个事实,即准确的预测需要分析更广泛的上下文并以高分辨率获取源数据。该模型的分层体系结构和端到端学习功能将有助于解决此问题。在第一级上,为了节省资源,以低分辨率分析整个图像。然后形成上下文,并且在更详细的级别上,模型通过分析高分辨率图像来评估几何形状。

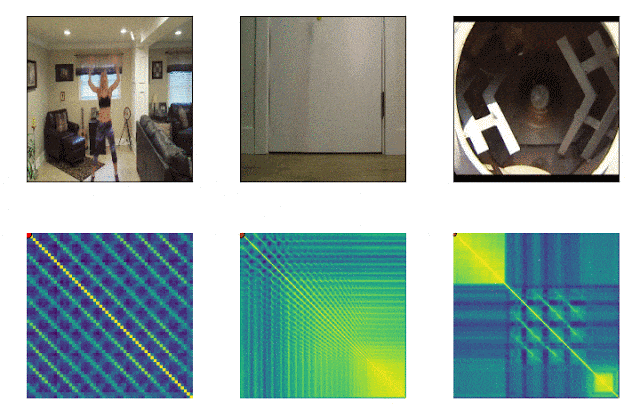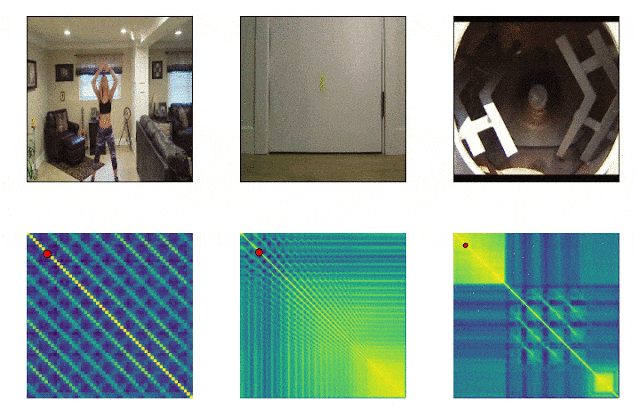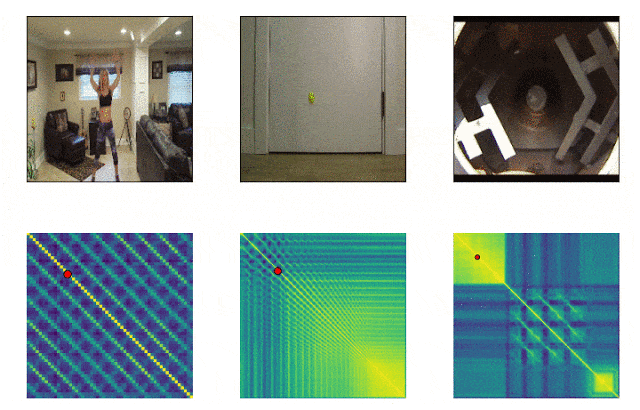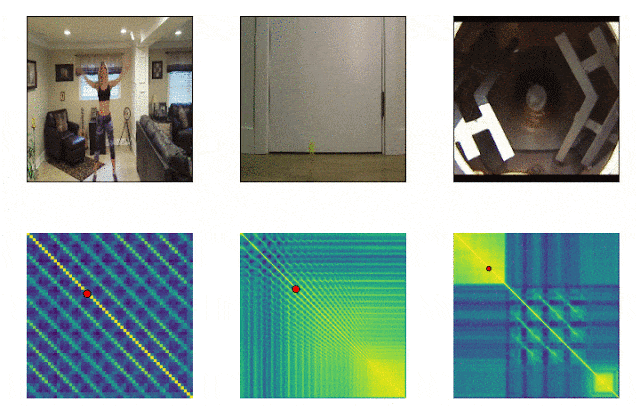
RepNet
我们周围的许多事物都由不同频率的周期组成。通常,为了理解现象的本质,有必要分析有关其反复出现的信息。考虑到视频拍摄的可能性,修复重复不再困难,问题在于计数重复。由于相机抖动或物体的阻碍,以及放大和缩小时比例和形状的急剧差异,通常不适合逐帧比较帧中像素密度的方法。由Google开发的模型现在可以解决此问题。它标识视频中的重复动作,包括训练中未使用的动作。结果,模型返回有关视频中识别的重复动作频率的数据。 Colab 已经可用。
SPICE模型
以前,您必须依靠复杂的信号处理算法来确定音高。最大的挑战是将研究中的声音与背景噪声或随附乐器的声音分开。现在可以为此任务使用预训练的模型,该模型可以检测高频和低频。该模型可在Web和移动设备上使用。
社交距离探测器
创建一个程序的情况,您可以使用该程序来跟踪人们是否观察到社交距离。作者详细讲述了他如何选择一个预先训练的模型,如何应付识别人的任务,以及如何使用OpenCV将图像转换为正交投影以计算人与人之间的距离。您还可以熟悉项目的源代码。

识别典型文件
如今,最常见的模板文档有成千上万的变体,例如收据,发票和支票。现有的自动化系统被设计为可以使用非常有限的模板类型。 Google建议为此使用机器学习。本文讨论了模型的体系结构以及所获得数据的结果。该工具将很快成为Document AI服务的一部分。
如何为非接触式零售的机器学习算法的开发和部署创建可扩展的管道
以色列初创公司Trigo分享了将机器学习和计算机视觉用于即取即走零售的经验。该公司是系统的供应商,该系统允许商店在无需收银机的情况下运营。作者讲述了他们面临的任务,并解释了为什么选择PyTorch作为机器学习的框架,以及选择Allegro AI Trains作为基础设施的原因以及如何建立开发流程。
就这样,谢谢您的关注!