尽管Python和R等语言在数据科学中变得越来越流行,但C和C ++可能是有效解决数据科学问题的强大选择。在本文中,我们将使用C99和C ++ 11编写与Anscombe四重奏配合使用的程序,我将在下面讨论。
我在关于Python和GNU Octave的文章中写了我不断学习语言的动机,值得一读。所有程序都用于命令行,而不是图形用户界面(GUI)。完整的示例可在polyglot_fit存储库中找到。
编程挑战
您将在本系列中编写的程序:
- 从CSV文件读取数据
- 用直线内插数据(即f(x)= m⋅x + q)。
- 将结果写入图像文件
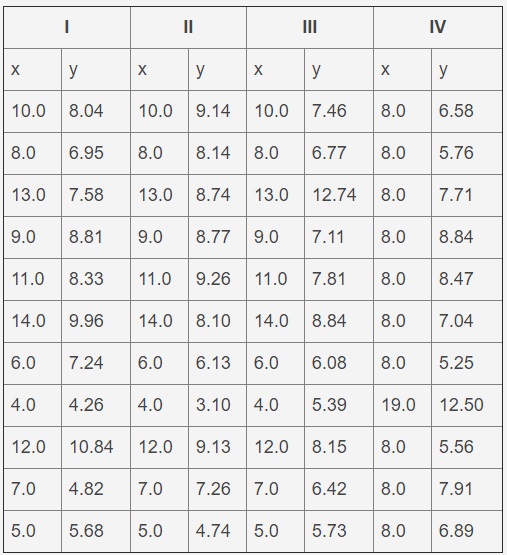
这是许多数据科学家面临的共同挑战。数据示例是下表中所示的第一组Anscombe四重奏。这是一组人工构建的数据,当拟合为一条直线时可以提供相同的结果,但是它们的图形非常不同。数据文件是一个文本文件,带有用于分隔列和形成标题的几行的选项卡。此问题将仅使用第一组(即前两列)。
安斯科姆四重奏
C解决方案
C是一种通用编程语言,它是当今使用最广泛的语言之一(根据TIOBE索引,RedMonk编程语言排名,编程语言受欢迎程度索引和GitHub研究)。它是一种古老的语言(它创建于1973年左右),并且已经用它编写了许多成功的程序(例如Linux内核和Git)。由于该语言用于直接内存管理,因此也尽可能接近计算机的内部工作原理。它是一种编译语言,因此源代码必须由编译器转换成机器代码。他的标准库小巧轻便,因此开发了其他库来提供缺少的功能。
这是我最常用于数字粉碎的语言,主要是因为它的性能。我发现使用它非常繁琐,因为它需要大量样板代码,但是在各种环境中都得到了很好的支持。C99标准是最新版本,增加了一些漂亮的功能,并且受到编译器的良好支持。
我将介绍用C和C ++进行编程的先决条件,以便初学者和有经验的用户都可以使用这些语言。
安装
C99开发需要编译器。我通常使用Clang,但是另一个成熟的开源编译器GCC可以。为了拟合数据,我决定使用GNU科学库。对于绘图,我找不到任何合理的库,因此该程序依赖于外部程序:Gnuplot。该示例还使用动态数据结构来存储数据,该结构在Berkeley Software Distribution(BSD)中定义。
在Fedora上的安装非常简单:
sudo dnf install clang gnuplot gsl gsl-devel代码注释
在C99中,通过在行首添加//来格式化注释,其余行将被解释器丢弃。/ *和* /之间的任何内容也将被丢弃。
// .
/* */所需的库
图书馆包括两部分:
- 包含功能说明的头文件
- 包含函数定义的源文件
头文件包含在源代码中,并且库的源代码链接到可执行文件。因此,此示例需要头文件:
// -
#include <stdio.h>
//
#include <stdlib.h>
//
#include <string.h>
// "" BSD
#include <sys/queue.h>
// GSL
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>主功能
在C语言中,程序必须位于名为main()的特殊函数内:
int main(void) {
...
}在这里,您会注意到与上一教程中讨论过的Python有所不同,因为对于Python,它将执行在源文件中找到的任何代码。
定义变量
在C语言中,变量必须在使用前声明,并且必须与类型关联。每当您要使用变量时,都必须决定要在其中存储哪些数据。您还可以指示是否要将变量用作常量值,这不是必需的,但是编译器可以从此信息中受益。存储库中fitting_C99.c程序中的示例:
const char *input_file_name = "anscombe.csv";
const char *delimiter = "\t";
const unsigned int skip_header = 3;
const unsigned int column_x = 0;
const unsigned int column_y = 1;
const char *output_file_name = "fit_C99.csv";
const unsigned int N = 100;C语言中的数组不是动态数组,因为它们的长度必须预先确定(即,在编译之前):
int data_array[1024];由于您通常不知道文件中有多少个数据点,因此请使用单链列表。它是可以无限增长的动态数据结构。幸运的是,BSD 提供了单链接列表。这是一个示例定义:
struct data_point {
double x;
double y;
SLIST_ENTRY(data_point) entries;
};
SLIST_HEAD(data_list, data_point) head = SLIST_HEAD_INITIALIZER(head);
SLIST_INIT(&head);此示例定义了一个列表data_point,该列表由同时包含x和y值的结构化值组成。语法非常复杂,但是很直观,并且详细说明太冗长。
打印
要打印到终端,可以使用printf()函数,该函数的作用类似于Octave中的printf()函数(在第一篇文章中介绍):
printf("#### C99 ####\n");printf()函数不会自动在打印行的末尾添加换行符,因此您需要自己添加换行符。第一个参数是一个字符串,它可以包含有关可以传递给函数的其他参数格式的信息,例如:
printf("Slope: %f\n", slope);读取数据
现在到了棘手的部分。...有几个用于在C中解析CSV文件的库,但是事实证明,没有一个库足够稳定或流行,因此不能在Fedora软件包存储库中使用。我没有为本教程添加依赖项,而是决定自己编写此部分。再说一遍,太过冗长的细节,所以我只解释一下总体思路。为了简洁起见,将忽略源代码中的某些行,但是您可以在存储库中找到完整的示例。
首先打开输入文件:
FILE* input_file = fopen(input_file_name, "r");然后逐行读取文件,直到发生错误或文件结束:
while (!ferror(input_file) && !feof(input_file)) {
size_t buffer_size = 0;
char *buffer = NULL;
getline(&buffer, &buffer_size, input_file);
...
}getline() 函数是POSIX.1-2008标准的一个很好的新增功能。它可以读取文件中的整行,并负责分配必要的内存。然后使用strtok()函数将每一行拆分为令牌。查看令牌,选择所需的列:
char *token = strtok(buffer, delimiter);
while (token != NULL)
{
double value;
sscanf(token, "%lf", &value);
if (column == column_x) {
x = value;
} else if (column == column_y) {
y = value;
}
column += 1;
token = strtok(NULL, delimiter);
}最后,选择x和y值,将新点添加到列表中:
struct data_point *datum = malloc(sizeof(struct data_point));
datum->x = x;
datum->y = y;
SLIST_INSERT_HEAD(&head, datum, entries);malloc() 函数为新点动态分配(保留)一定数量的永久内存。
拟合数据
GSL的 线性插值函数gsl_fit_linear()接受常规数组作为输入。因此,由于您无法事先知道创建的数组的大小,因此必须为它们手动分配内存:
const size_t entries_number = row - skip_header - 1;
double *x = malloc(sizeof(double) * entries_number);
double *y = malloc(sizeof(double) * entries_number);然后遍历列表以将相关数据存储在数组中:
SLIST_FOREACH(datum, &head, entries) {
const double current_x = datum->x;
const double current_y = datum->y;
x[i] = current_x;
y[i] = current_y;
i += 1;
}现在您已完成列表的整理,整理订单。总是释放手动分配的内存,以防止内存泄漏。内存泄漏是严重的,严重的,然后是严重的。每当不释放内存时,花园侏儒都会迷失自己的头:
while (!SLIST_EMPTY(&head)) {
struct data_point *datum = SLIST_FIRST(&head);
SLIST_REMOVE_HEAD(&head, entries);
free(datum);
}最后,最后(!),您可以拟合数据:
gsl_fit_linear(x, 1, y, 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x, 1, y, 1, entries_number);
printf("Slope: %f\n", slope);
printf("Intercept: %f\n", intercept);
printf("Correlation coefficient: %f\n", r_value);绘制图形
要生成图形,必须使用外部程序。因此,将拟合函数保留在外部文件中:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
fprintf(output_file, "%f\t%f\n", current_x, current_y);
}Gnuplot绘图命令如下所示:
plot 'fit_C99.csv' using 1:2 with lines title 'Fit', 'anscombe.csv' using 1:2 with points pointtype 7 title 'Data'结果
在运行程序之前,您需要编译它:
clang -std=c99 -I/usr/include/ fitting_C99.c -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_C99该命令告诉编译器使用C99标准,读取fitting_C99.c文件,加载gsl和gslcblas库,并将结果保存到fit_C99。命令行上的结果输出:
#### C99 ####
: 0.500091
: 3.000091
: 0.816421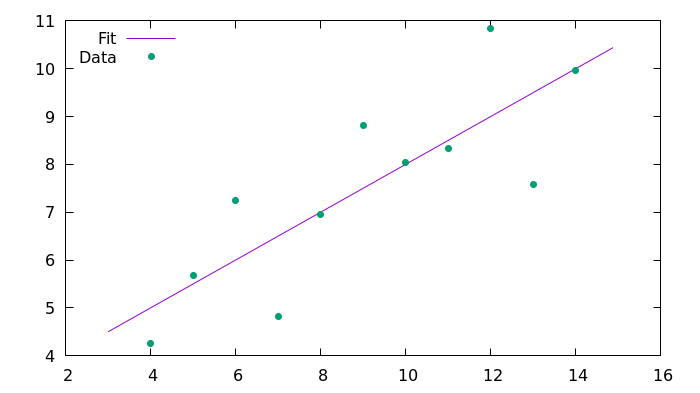
这是使用Gnuplot生成的结果图像。
C ++ 11解决方案
C ++是一种通用编程语言,它也是当今使用最广泛的语言之一。它被创建为C语言的后继者(1983年),重点是面向对象的编程(OOP)。 C ++通常被认为是C的超集,因此C程序必须使用C ++编译器进行编译。并非总是如此,因为在某些极端情况下,它们的行为有所不同。以我的经验,C ++比C需要更少的样板代码,但是如果您要设计对象,其语法会更复杂。 C ++ 11标准是最新的修订版,它添加了一些或多或少受编译器支持的漂亮功能。
由于C ++几乎与C兼容,因此我将仅关注两者之间的差异。如果我在本部分中未描述任何部分,则意味着它与C中的相同。
安装
C ++的依赖关系与示例C相同。在Fedora上,运行以下命令:
sudo dnf install clang gnuplot gsl gsl-devel所需的库
这些库的工作方式与C语言相同,但是include指令略有不同:
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
extern "C" {
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>
}由于GSL库是用C编写的,因此需要告知编译器此功能。
定义变量
C ++比C支持更多的数据类型(类),例如,字符串类型,它具有比C语言更多的功能。相应地更新变量定义:
const std::string input_file_name("anscombe.csv");对于字符串之类的结构化对象,您可以定义变量而无需使用=符号。
打印
您可以使用printf()函数,但使用cout更为常见。使用<<操作符来指定要使用cout打印的字符串(或对象):
std::cout << "#### C++11 ####" << std::endl;
...
std::cout << " : " << slope << std::endl;
std::cout << ": " << intercept << std::endl;
std::cout << " : " << r_value << std::endl;读取数据
电路与以前相同。将打开文件并逐行读取文件,但语法不同:
std::ifstream input_file(input_file_name);
while (input_file.good()) {
std::string line;
getline(input_file, line);
...
}字符串标记是通过与C99示例中相同的功能检索的。使用两个向量而不是标准C数组。向量是C ++ 标准库中C数组的扩展,用于动态管理内存而无需调用malloc():
std::vector<double> x;
std::vector<double> y;
// x y
x.emplace_back(value);
y.emplace_back(value);拟合数据
要使数据适合C ++,您不必担心列表,因为可以保证向量具有顺序内存。您可以直接将指向矢量缓冲区的指针传递给拟合函数:
gsl_fit_linear(x.data(), 1, y.data(), 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x.data(), 1, y.data(), 1, entries_number);
std::cout << " : " << slope << std::endl;
std::cout << ": " << intercept << std::endl;
std::cout << " : " << r_value << std::endl;绘制图形
绘制与以前相同。写入文件:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
output_file << current_x << "\t" << current_y << std::endl;
}
output_file.close();然后使用Gnuplot绘制图形。
结果
在运行程序之前,必须使用类似的命令对其进行编译:
clang++ -std=c++11 -I/usr/include/ fitting_Cpp11.cpp -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_Cpp11命令行上的结果输出:
#### C++11 ####
: 0.500091
: 3.00009
: 0.816421这是用Gnuplot生成的结果图像。
结论
本文提供了在C99和C ++ 11中进行数据拟合和绘图的示例。由于C ++在很大程度上与C兼容,因此本文使用相似之处来编写第二个示例。在某些方面,C ++更易于使用,因为它部分减轻了显式内存管理的负担,但其语法更复杂,因为它引入了为OOP编写类的能力。但是,您也可以使用OOP技术用C编写代码,因为OOP是一种编程风格,因此可以用任何语言来使用。在C中有一些很棒的OOP示例,例如GObject和Jansson库。
我更喜欢使用C99处理数字,因为它的语法更简单,支持范围更广。直到最近,C ++ 11尚未得到广泛支持,我尝试避免使用早期版本中的粗糙之处。对于更复杂的软件,C ++可能是一个不错的选择。
您是否正在使用C或C ++进行数据科学?在评论中分享您的经验。

通过完成SkillFactory付费在线课程,了解如何从头开始或成为技能和薪资水平升级的热门职业的详细信息:
- 机器学习课程(12周)
- 从头开始培训数据科学专业(12个月)
- 具备任何入门水平的分析专业(9个月)
- 用于Web开发的Python(9个月)