我们提请您注意Crowdstrike公司有趣的研究成果的译文。该材料致力于在数据科学领域(与恶意软件分析有关)中使用Rust语言,并展示了Rust即使在使用NumPy和SciPy时也可以在该领域竞争,更不用说纯Python了。

享受阅读!
Python是最流行的数据科学编程语言之一,这是有充分理由的。Python软件包索引(PyPI)具有大量令人印象深刻的数据科学库,例如NumPy,SciPy,自然语言工具包,Pandas和Matplotlib。凭借大量可用的高质量分析库和广泛的开发人员社区,Python是许多数据科学家的不二之选。
出于性能原因,这些库中的许多都在C和C ++中实现,但提供了外部函数接口(FFI)或Python绑定,因此可以从Python调用函数。这些较低级别的语言实现旨在缓解一些Python最明显的缺点,特别是在执行时间和内存消耗方面。如果可以限制执行时间和内存消耗,那么可伸缩性将大大简化,这对于降低成本至关重要。如果我们可以编写解决数据科学问题的高性能代码,那么将此类代码与Python集成将是一个显着的优势。
在数据 科学和恶意软件分析的交叉点工作时不仅需要快速执行,而且还需要有效利用共享资源进行扩展。扩展是大数据中的关键问题之一,例如有效地跨多个平台处理数百万个可执行文件。为了在现代处理器上获得良好的性能,需要并行性,通常使用多线程来实现。但是它还需要提高代码执行效率和内存消耗。解决此类问题时,可能难以平衡本地系统的资源,并且更难于正确实现多线程系统。 C和C ++的本质是不提供线程安全性。是的,有特定于外部平台的库,但是确保线程安全显然是开发人员的职责。
解析恶意软件本质上是危险的。恶意软件通常会以意想不到的方式操纵文件格式的数据结构,从而破坏了分析实用程序。在Python中等待我们的一个相对常见的陷阱是缺乏良好的类型安全性。 Python会
None在期望的地方慷慨地接受值bytearray,但会陷入混乱,只能通过在代码中加入check来避免None。这种“鸭式打字”的假设通常会导致崩溃。
但是有Rust。Rust在许多方面都被定位为解决上述所有潜在问题的理想解决方案:运行时和内存消耗与C和C ++相当,并且提供了广泛的类型安全性。Rust还提供了其他便利设施,例如强大的内存安全保证和没有运行时开销。由于没有这种开销,因此可以更轻松地将Rust代码与其他语言(尤其是Python)的代码集成在一起。在本文中,我们将快速浏览Rust,以了解它是否值得与其大肆宣传。
数据科学样本申请
数据科学是一个非常广泛的学科领域,具有许多应用方面,因此不可能在一篇文章中讨论所有这些方面。数据科学的一个简单任务是计算字节序列的信息熵。对于在比特计算熵的一般公式给出在维基百科:
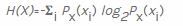
为了计算熵的随机变量
X,我们首先计算多少次每个可能的字节值时发生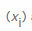 ,然后遇到的计算遇到特定值的概率的元素的总数量除以数
,然后遇到的计算遇到特定值的概率的元素的总数量除以数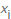 分别
分别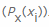 。然后,我们根据特定值xi发生的概率的加权总和以及所谓的自身信息来计算负值
。然后,我们根据特定值xi发生的概率的加权总和以及所谓的自身信息来计算负值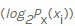 ... 由于我们以位为单位计算熵,因此在这里使用它
... 由于我们以位为单位计算熵,因此在这里使用它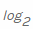 (请注意基数为2)。
(请注意基数为2)。
让我们尝试一下Rust,看看它与纯Python相比如何处理熵计算,以及上面提到的一些流行的Python库。这是Rust潜在数据科学性能的简化估算;这个实验不是对Python或它包含的优秀库的批评。在这些示例中,我们将从Rust代码生成自己的C库,然后可以从Python导入。所有测试均在Ubuntu 18.04上运行。
纯Python
让我们从一个简单的纯Python函数(c
entropy.py)开始,该函数bytearray仅使用标准库中的math模块来计算熵。此功能尚未优化,因此让我们将其作为修改和性能测量的起点。
import math
def compute_entropy_pure_python(data):
"""Compute entropy on bytearray `data`."""
counts = [0] * 256
entropy = 0.0
length = len(data)
for byte in data:
counts[byte] += 1
for count in counts:
if count != 0:
probability = float(count) / length
entropy -= probability * math.log(probability, 2)
return entropy
带有NumPy和SciPy的Python
毫不奇怪,SciPy提供了一个计算熵的函数。但是首先,我们将使用
unique()NumPy中的函数来计算字节频率。将SciPy熵函数的性能与其他实现进行比较有点不公平,因为SciPy实现具有用于计算相对熵(Kullback-Leibler距离)的其他功能。同样,我们将做一个(希望不是太慢)测试驱动器,以查看从Python导入的已编译Rust库的性能。我们将坚持使用脚本中包含的SciPy实现entropy.py。
import numpy as np
from scipy.stats import entropy as scipy_entropy
def compute_entropy_scipy_numpy(data):
""" bytearray `data` SciPy NumPy."""
counts = np.bincount(bytearray(data), minlength=256)
return scipy_entropy(counts, base=2)带有Rust的Python
接下来,与以前的实现相比,我们将更加稳健地探索Rust实现。让我们从用Cargo生成的默认库包开始。以下各节说明我们如何修改Rust软件包。
cargo new --lib rust_entropy
Cargo.toml我们从
Cargo.toml定义货物包装并指定库名称的强制性清单文件开始 rust_entropy_lib。我们使用来自crates.io的Rust包注册表中的公共cpython容器(v0.4.1)。对于本文,我们使用的是Rust的v1.42.0,这是撰写本文时可用的最新稳定版本。
[package] name = "rust-entropy"
version = "0.1.0"
authors = ["Nobody <nobody@nowhere.com>"] edition = "2018"
[lib] name = "rust_entropy_lib"
crate-type = ["dylib"]
[dependencies.cpython] version = "0.4.1"
features = ["extension-module"]库
Rust库的实现非常简单。与纯Python实现一样,我们为每个可能的字节值初始化counts数组,然后遍历数据以填充counts。要完成此操作,请计算并返回概率的负总和乘以
概率。
use cpython::{py_fn, py_module_initializer, PyResult, Python};
///
fn compute_entropy_pure_rust(data: &[u8]) -> f64 {
let mut counts = [0; 256];
let mut entropy = 0_f64;
let length = data.len() as f64;
// collect byte counts
for &byte in data.iter() {
counts[usize::from(byte)] += 1;
}
//
for &count in counts.iter() {
if count != 0 {
let probability = f64::from(count) / length;
entropy -= probability * probability.log2();
}
}
entropy
}
我们剩下的
lib.rs就是一种从Python调用纯Rust函数的机制。我们在lib.rsCPython调整的(compute_entropy_cpython())函数中包含了一个称为“纯” Rust函数的函数(compute_entropy_pure_rust())。这样,我们仅受益于维护单个纯Rust实现并提供CPython友好的包装器。
/// Rust CPython
fn compute_entropy_cpython(_: Python, data: &[u8]) -> PyResult<f64> {
let _gil = Python::acquire_gil();
let entropy = compute_entropy_pure_rust(data);
Ok(entropy)
}
// Python Rust CPython
py_module_initializer!(
librust_entropy_lib,
initlibrust_entropy_lib,
PyInit_rust_entropy_lib,
|py, m | {
m.add(py, "__doc__", "Entropy module implemented in Rust")?;
m.add(
py,
"compute_entropy_cpython",
py_fn!(py, compute_entropy_cpython(data: &[u8])
)
)?;
Ok(())
}
);从Python调用Rust代码
最后,我们从Python(再次从
entropy.py)调用Rust实现。为此,我们首先导入从Rust编译的自己的动态系统库。然后,我们只需调用我们先前py_module_initializer!在Rust代码中使用宏初始化Python模块时指定的库函数。在这一阶段,我们只有一个Python(entropy.py)模块,其中包括用于调用熵计算的所有实现的函数。
import rust_entropy_lib
def compute_entropy_rust_from_python(data):
"" bytearray `data` Rust."""
return rust_entropy_lib.compute_entropy_cpython(data)我们正在使用Cargo在Ubuntu 18.04上构建上述Rust库软件包。(此链接对于OS X用户可能很方便)。
cargo build --release完成组装后,我们重命名结果库并将其复制到我们的Python模块所在的目录中,以便可以从脚本中导入它。使用Cargo创建的库名为
librust_entropy_lib.so,但是您需要将其重命名为,rust_entropy_lib.so以便能够成功导入作为这些测试的一部分。
绩效检查:结果
我们使用pytest断点测量了每个函数实现的性能,计算了超过一百万个随机字节的熵。所有实现均显示在同一数据上。基准(也包含在entropy.py中)如下所示。
# ### ###
# w/ NumPy
NUM = 1000000
VAL = np.random.randint(0, 256, size=(NUM, ), dtype=np.uint8)
def test_pure_python(benchmark):
""" Python."""
benchmark(compute_entropy_pure_python, VAL)
def test_python_scipy_numpy(benchmark):
""" Python SciPy."""
benchmark(compute_entropy_scipy_numpy, VAL)
def test_rust(benchmark):
""" Rust, Python."""
benchmark(compute_entropy_rust_from_python, VAL)最后,我们为计算熵所需的每种方法制作单独的简单驱动程序脚本。接下来是用于测试纯Python实现的代表性驱动程序脚本。该文件包含
testdata.bin1,000,000个随机字节,用于测试所有方法。每种方法都会重复计算100次,以更轻松地捕获内存使用情况数据。
import entropy
with open('testdata.bin', 'rb') as f:
DATA = f.read()
for _ in range(100):
entropy.compute_entropy_pure_python(DATA)SciPy / NumPy和Rust的实现均显示出良好的性能,轻松地将未经优化的纯Python实现击败了100倍以上。 Rust版本的性能仅比SciPy / NumPy版本好一点,但结果证实了我们的期望:纯Python比编译语言要慢得多,并且用Rust编写的扩展可以相当成功地与C语言竞争(即使在这样的情况下也能击败它们)。微测试)。
还有其他提高生产率的方法。我们可以使用模块
ctypes或cffi。您可以添加类型提示,并使用Cython生成可以从Python导入的库。所有这些选项都需要考虑特定于解决方案的权衡。

我们还使用GNU应用程序测量了每个功能实现的内存使用情况
time(不要与内置的shell命令混淆time)。特别是,我们测量了最大居民集大小。
在纯Python和Rust实现中,此部分的最大大小非常相似,而SciPy / NumPy实现在此基准测试中会消耗更多的内存。据推测这是由于导入期间将其他功能加载到了内存中。即便如此,从Python调用Rust代码似乎也不会带来显着的内存开销。

结果
从Python调用Rust时获得的性能给我们留下了深刻的印象。在坦率的简短评估中,Rust实现能够与SciPy和NumPy包中的基础C实现在性能上竞争。 Rust对于高效的大规模处理似乎非常有用。
Rust不仅表现出出色的执行时间,而且表现出色。应该注意的是,这些测试中的内存开销也很小。这些运行时和内存使用特征对于可伸缩性目的似乎是理想的。 SciPy和NumPy C FFI实现的性能绝对可以媲美,但是使用Rust,我们可以获得C和C ++无法提供的其他优势。内存安全和线程安全保证是非常诱人的好处。
尽管C提供了与Rust相当的运行时,但是C本身并不提供线程安全。有一些外部库为C提供此功能,但是开发人员有责任确保正确使用它们。由于拥有所有权模型,Rust监视线程安全性问题,例如在编译时的竞争-标准库提供了一系列并发机制,包括管道,锁和引用计数的智能指针。
我们不主张将SciPy或NumPy移植到Rust,因为这些Python库已经过很好的优化,并得到了出色的开发人员社区的支持。另一方面,我们强烈建议将高性能库中未提供的代码从纯Python移植到Rust。在用于安全性分析的数据科学应用程序的上下文中,Rust看起来是Python的竞争替代品,因为它具有速度和安全性保证。