
当然,NSPK并不是一家初创公司,但是在公司成立的头几年,这种气氛在公司中盛行,而这是非常有趣的几年。我的名字叫Dmitry Kornyakov,十多年来,我一直在支持具有高可用性要求的Linux基础架构。他于2016年1月加入NSPK团队,不幸的是,他没有看到公司成立的开始,而是进入了一个巨大的变革阶段。
一般而言,我们可以说我们的团队为公司提供了2种产品。首先是基础设施。邮件应该发送,DNS应该可以使用,并且域控制器应允许您使用不应该掉落的服务器。公司的IT领域巨大!这些是业务和任务关键型系统,某些系统的可用性要求为99,999。第二种产品是物理和虚拟服务器本身。需要对现有部门进行监视,并定期从许多部门向客户提供新部门。在本文中,我想重点介绍如何开发负责服务器生命周期的基础结构。
路径
的起点在路径的起点,我们的技术堆栈如下所示:
OS CentOS 7
域控制器FreeIPA
自动化-Ansible(+塔式),Cobbler
所有这些都位于3个域中,分布在多个数据中心中。在一个数据中心-办公系统和测试站点中,在其他PROD中。
在某些时候,创建服务器如下所示:
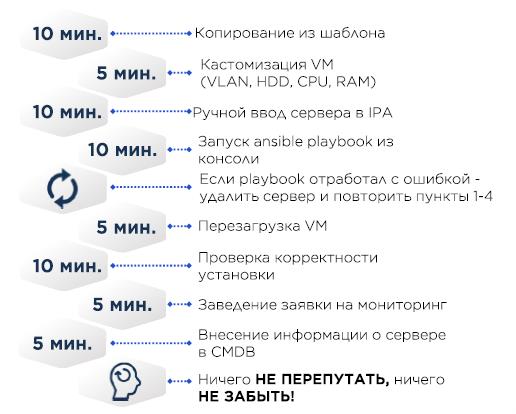
在VM CentOS最小模板和所需的最小模板(例如正确的/etc/resolv.conf)中,其余部分通过Ansible来提供。
CMDB-Excel。
如果服务器是物理服务器,则使用Cobbler在OS上安装操作系统,而不是复制虚拟机-将目标服务器的MAC地址添加到Cobbler配置中,服务器通过DHCP接收IP地址,然后注入OS。
最初,我们甚至尝试在Cobbler中进行某种配置管理。但是随着时间的流逝,这开始给配置的可移植性带来问题,该可移植性既可以移植到其他数据中心,也可以移植到用于准备VM的Ansible代码。
那时,我们中的许多人都将Ansible视为Bash的便捷扩展,并且没有对使用sed壳的结构有所了解。一般而言。这最终导致以下事实:如果由于某种原因该剧本无法在服务器上运行,则删除服务器,修复剧本并重新运行会更容易。实际上,没有脚本版本控制,也没有配置可移植性。
例如,我们想在所有服务器上更改一些配置:
- 我们更改逻辑段/数据中心中现有服务器上的配置。有时不是一夜之间-可用性要求和大量定律不允许一次应用所有更改。而且某些更改可能具有破坏性,需要重新启动任何操作-从服务到操作系统本身。
- 固定在Ansible中
- 修理鞋匠
- 对每个逻辑段/数据中心重复N次
为了使所有更改顺利进行,必须考虑许多因素,并且不断发生更改。
- 重构Ansible代码,配置文件
- 改变内部最佳实践
- 分析事件/事故后的变化
- 不断变化的内部和外部安全标准。例如,PCI DSS每年都会根据新要求进行更新
基础架构的增长和路径的开始
服务器/逻辑域/数据中心的数量在增加,随之而来的是配置错误的数量。在某个时候,我们向三个方向发展了配置管理:
- 自动化。尽可能避免重复操作中的人为因素。
- . , . . – , .
- configuration management.
仍然需要添加一些工具。
我们选择GitLab CE作为我们的代码存储库,尤其是内置CI / CD模块。
秘密保管库-Hashicorp Vault,包括用于出色的API。
测试配置和角色-Molecule + Testinfra。如果连接到有毒的促分裂原,测试的运行速度会更快。同时,我们开始编写自己的CMDB和用于自动部署的协调器(在Cobbler上方的图片中),但这是一个完全不同的故事,我的同事和这些系统的主要开发人员将在以后讲述。
我们的选择:
分子+ Testinfra
Ansible +塔+ AWX服务器
世界+ DITNET(内部)
皮匠
Gitlab + GitLab亚军
Hashicorp库

谈到角色扮演。刚开始时它是一个人,经过几次重构后,共有17个重构,我强烈建议将整体结构分解为幂等角色,然后可以单独运行这些角色,还可以添加标签。我们按功能划分了角色-网络,日志记录,程序包,硬件,分子等。通常,我们遵循以下策略。我不坚持这是唯一的事实,但这对我们有用。
- 从“黄金映像”复制服务器是邪恶的!
主要缺点是您不确切知道映像现在处于什么状态,并且所有更改都将应用于所有虚拟化场中的所有映像。 - 至少使用默认配置文件,并与其他部门就您负责的核心系统文件达成一致,例如:
- /etc/sysctl.conf , /etc/sysctl.d/. , .
- override systemd .
- , sed
- :
- ! Ansible-lint, yaml-lint, etc
- ! bashsible.
- Ansible molecule .
- , ( 100) 70000 . .

我们的实现
因此,烦人的角色已经准备好,由linters进行了模板化和检查。甚至到处都有git。但是,将代码可靠地交付给不同段的问题仍然存在。我们决定与脚本同步。看起来像这样:

更改到达后,启动CI,创建测试服务器,滚动角色,并使用分子进行测试。如果一切正常,代码将转到生产分支。但是我们不会将新代码应用于计算机中的现有服务器。这是一种塞子,对于我们的系统的高可用性是必需的。当基础架构变得庞大时,大量的定律就会起作用-即使您确定更改无害,也可能导致可悲的后果。
还有许多用于创建服务器的选项。我们最终选择了自定义python脚本。对于CI ansible:
- name: create1.yml - Create a VM from a template
vmware_guest:
hostname: "{{datacenter}}".domain.ru
username: "{{ username_vc }}"
password: "{{ password_vc }}"
validate_certs: no
cluster: "{{cluster}}"
datacenter: "{{datacenter}}"
name: "{{ name }}"
state: poweredon
folder: "/{{folder}}"
template: "{{template}}"
customization:
hostname: "{{ name }}"
domain: domain.ru
dns_servers:
- "{{ ipa1_dns }}"
- "{{ ipa2_dns }}"
networks:
- name: "{{ network }}"
type: static
ip: "{{ip}}"
netmask: "{{netmask}}"
gateway: "{{gateway}}"
wake_on_lan: True
start_connected: True
allow_guest_control: True
wait_for_ip_address: yes
disk:
- size_gb: 1
type: thin
datastore: "{{datastore}}"
- size_gb: 20
type: thin
datastore: "{{datastore}}"这就是我们所要达到的,系统继续存在和发展。
- 17个用于配置服务器的角色。每个角色都旨在解决单独的逻辑任务(记录,审核,用户授权,监视等)。
- 角色测试。分子+ TestInfra。
- 自己的开发:CMDB + Orchestrator。
- 服务器创建时间约为30分钟,自动完成,几乎与任务队列无关。
- 在所有细分市场中,基础架构的状态/名称相同-剧本,存储库,虚拟化元素。
- 每天检查服务器状态,并生成与标准差异的报告。
我希望我的故事对那些刚开始的人有用。您正在使用什么自动化堆栈?