作为概述,我们采用了CHI: 10年来的计算机系统人为因素会议的会议记录,在NLP和社交网络分析的帮助下,我们研究了学科交叉的主题和领域。

在俄罗斯,重点特别放在UX设计的应用问题上。帮助HCI在国外发展的许多事件并未在我们国家发生:没有出现iSchools,许多参与工程心理学相关方面的专家离开了科学等等。结果,该行业重新出现,从应用问题和研究开始。结果之一甚至在现在就已经可见-这是俄罗斯人机交互在主要会议上的代表极低。
但是在俄罗斯以外,HCI的发展方式截然不同,专注于各种主题和领域。在硕士课程上“ 信息系统与人机交互“在圣彼得堡HSE,我们与学生,同事,欧洲大学类似专业的毕业生,帮助开发该程序的合作伙伴进行讨论,其中涉及人机交互领域。这些讨论表明了每个专家对自己的领域有不完整的了解的方向的异质性。
我们不时听到有关该方向与机器学习和数据分析之间的关系(以及它是否完全连接)的问题。为了回答这些问题,我们转向了CHI会议上提出的最新研究。
首先,我们将告诉您在xAI和iML(可解释性人工智能和可解释性机器学习)等领域发生了什么 从界面和用户的角度,以及在HCI中他们如何研究数据科学家工作的认知方面,我们将举例说明近年来在各个领域中有趣的工作。
xAI和iML
机器学习技术正在得到大力发展,并且-更重要的是从所讨论的领域的角度出发-积极地在自动化决策中实施。因此,研究人员越来越多地讨论以下问题:非机器学习用户如何与使用类似算法的系统交互?交互的重要问题之一:如何使用户信任模型所做的决策?因此,每年解释型机器学习(可解释性机器学习-iML)和可解释的人工智能(eXplainable人工智能-XAI)的话题变得越来越热门。
同时,如果在诸如NeurIPS,ICML,IJCAI,KDD之类的会议上讨论iML和XAI的算法和方法,CHI将关注与设计功能和使用这些系统的经验有关的几个主题。例如,在CHI-2020上,有几个部分同时专门讨论了该主题,包括“ AI / ML和透视黑匣子”和“应对AI:不是agAIn!”。但是,即使在出现单独的部分之前,也有很多这样的作品。我们在其中确定了四个领域。
解决应用问题的解释系统的设计
第一个方向是在各种应用问题(医学,社会等)中基于可解释性算法的系统设计。此类工作出现在非常不同的领域。例如,在CHI-2020 CheXplain上工作:使医师能够探索和理解以数据为驱动力,基于AI的医学影像分析 描述了一种可以帮助医生检查和解释胸部X光检查结果的系统。她提供了其他文字和视觉说明,以及具有相同和相反结果的图片(支持和冲突的示例)。如果系统预测在X射线上可见疾病,它将显示两个示例。第一个支持性例子是另一名已确认相同疾病的患者的肺部快照。第二个相互矛盾的例子是没有疾病的快照,即健康人的肺部快照。主要思想是减少明显的错误,并减少简单情况下的外部咨询次数,以加快诊断速度。
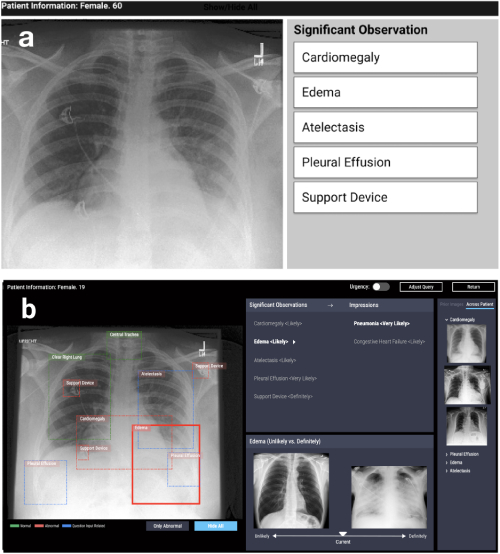
CheXpert:自动区域选择和示例(不太可能与肯定)
开发用于研究机器学习模型的系统
第二个方向是开发有助于交互式比较或组合几种方法和算法的系统。例如,在席尔瓦(Silva)的工作中:在CHI-2020上使用因果关系交互式评估机器学习公平性,提出了一种系统,该系统可以在用户数据上构建多个机器学习模型,并提供其后续分析的可能性。分析包括在变量之间建立因果图,并计算多个指标,这些指标不仅可以评估模型的准确性,还可以评估模型的公平性(统计奇偶性差异,机会均等性差异,平均几率差异,差异影响,Theil指数),这有助于发现偏差在预测中。

Silva:变量之间的关系图+用于比较公平性指标的图+每组中有影响力的变量的颜色突出显示
模型可解释性的一般问题
第三个领域是关于模型可解释性问题的方法的讨论。最常见的是评论,对方法的批评和未解决的问题:例如,“可解释性”是什么意思。在这里,我想指出CHI-2018 可解释,负责和可理解系统的趋势和轨迹的回顾:HCI研究议程,作者在其中审查了289篇有关人工智能解释的主要论文,并引用了12412篇出版物。通过网络分析和案例建模,他们确定了四个关键研究领域:1)智能和环境(I&A)系统; 2)可解释的AI:公平,负责和透明(FAT)算法和可解释性机器学习(iML); 3)说明:因果关系和认知心理学,4)互动性和可学习性。此外,作者还描述了主要的研究趋势:交互式学习和与系统的交互。
用户研究
最后,第四领域是用户对解释机器学习模型的算法和系统的研究。换句话说,这些是关于新系统在实践中是否变得更加清晰和透明,用户在使用解释性模型而不是原始模型时面临的困难,如何确定系统是否按计划使用(或已找到新应用程序)的研究。 -可能不正确),用户的需求是什么,开发人员是否向他们提供了他们真正需要的东西。
有许多解释工具和算法,因此出现了一个问题:如何理解选择哪种算法?在质疑AI中:为可解释的AI用户体验提供指导的设计实践讨论了使用解释性算法的动机问题,并发现了使用各种方法尚未充分解决的问题。作者得出一个出乎意料的结论:大多数现有方法的构建方式都可以回答问题“为什么”(“为什么会有这样的结果”),而用户也需要回答问题“为什么不这样”(“为什么不是另一个”),有时是-”如何更改结果。”
该论文还说,用户需要了解方法适用性的限制是什么,他们有什么限制-这需要在建议的工具中明确实现。在文章中更清楚地显示了此问题解释可解释性:了解数据科学家对机器学习的可解释性工具的使用。作者与机器学习领域的专家进行了一个小实验:他们展示了几种解释机器学习模型的流行工具的结果,并要求他们回答与基于这些结果做出决策有关的问题。事实证明,即使是专家,也对此类模型过于信任,并且对结果并不严格。像任何工具一样,解释性模型可能会被滥用。在开发工具包时,重要的是要考虑到这一点,使用人机交互领域中积累的知识(或专家)来考虑潜在用户的特征和需求。
Data Science, Notebooks, Visualization
HCI的另一个有趣领域是分析处理数据的认知方面。最近,科学提出了一个问题,即研究人员的“自由度”如何影响数据的收集,实验设计和分析方法的选择,这些因素如何影响研究结果及其可重复性。尽管许多讨论和批评都与心理学和社会科学有关,但许多问题关系到数据分析师总体上结论的可靠性,以及将这些发现传达给分析消费者的困难。
因此,这个HCI领域的主题是开发新方法以可视化模型预测中的不确定性,创建用于比较以不同方式进行的分析的系统以及使用诸如Jupyter笔记本之类的工具来分析分析师的工作。
可视化不确定性
不确定性可视化是将科学图形与演示和业务可视化区分开的功能之一。长期以来,极简主义原则和关注主要趋势被视为后者的关键。但是,这会导致用户对幅度或预测的点估计过分自信,这可能很关键,尤其是当我们必须比较具有不同程度不确定性的预测时。使用分位数点图或CDF的作业不确定性显示可改善运输决策通过使用从移动应用程序的数据估计公交车到达时间的问题的示例,研究了散点图和累积分布函数的预测中不确定性的可视化如何帮助用户做出更合理的决策。特别好的是,其中一位作者为R 维护了ggdist包,并提供了多种可视化歧义的选项。

不确定性可视化示例(https://mjskay.github.io/ggdist/)
但是,经常遇到可视化替代方案的任务,例如,针对Web分析或应用程序分析中的用户操作序列。可视化事件序列预测中的不确定性和替代方案的工作分析了基于时间感知递归神经网络(TRNN ) 模型的替代方案的图形表示,如何帮助专家做出决定并信任他们。
型号比较
与可视化不确定性一样重要,分析师工作的一个方面是比较研究人员在其所有阶段选择的建模方法不同(通常是隐藏的)如何导致不同的分析结果。在心理学和社会科学领域,研究设计的预先注册以及探索性研究和确认性研究的明确区分正变得越来越流行。但是,在研究更多地由数据驱动的任务中,可以选择一种工具,使您可以通过比较模型来评估分析的隐患。通过可探索的多元分析提高工作论文的透明度建议对文章中的几种分析方法使用交互式可视化。从本质上讲,本文变成了一个交互式应用程序,读者可以在其中评估如果采用不同的方法,结果和结论将发生什么变化。对于实际分析而言,这似乎也是一个有用的想法。
使用用于组织和分析数据的工具
最后的工作与研究分析师如何使用Jupyter Notebooks等系统有关,该系统已成为组织数据分析的流行工具。计算笔记本中的文章探索与解释分析了Github交互式文档中的研究与解释学习目标与计算笔记本中的管理展览之间的矛盾作者分析了注释,代码段和可视化在迭代分析器工作流程中的演变方式,并提出了可能添加的工具来支持此过程。最后,在CHI 2020上,文章“计算笔记本有什么问题?”中总结了分析人员在各个工作阶段的主要问题,从加载数据到将模型转移到生产中,以及改进工具的想法。痛点,需求和设计机会。
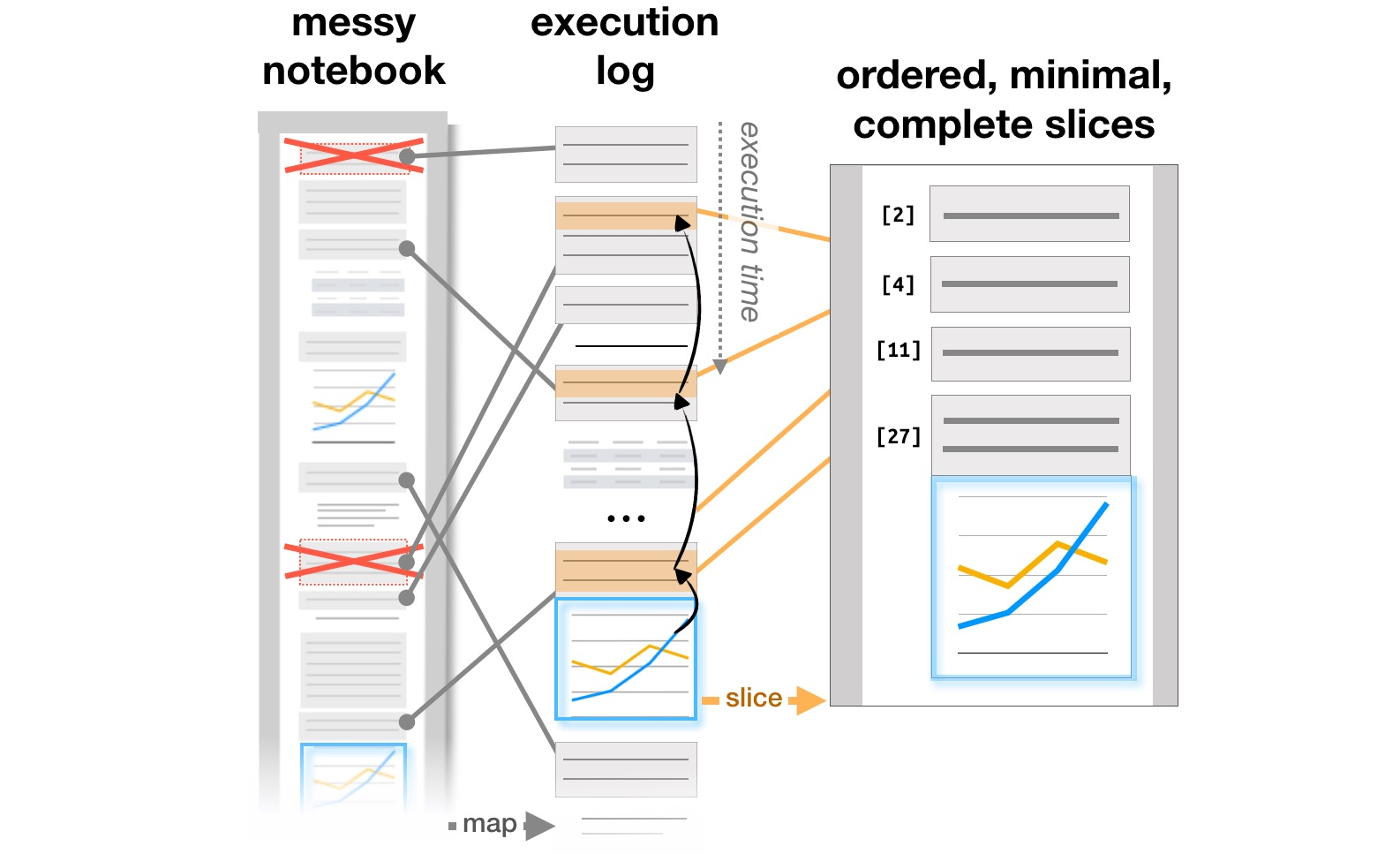
基于执行日志的报表结构转换(https://microsoft.github.io/gather/)
总结
在讨论部分“ HCI做什么”和“ HCI专家为何了解机器学习”的部分结束时,我想从这些研究的动机和结果中重申总体结论。一旦有人出现在系统中,就会立即引发许多其他问题:如何简化与系统的交互并避免错误,用户如何更改系统,实际使用是否与计划的不同。结果,我们需要那些了解使用人工智能设计系统的过程如何工作,并且知道如何考虑人为因素的人。
我们在硕士课程“ 信息系统与人机交互 ”上教授所有这些课程”。如果您对人机交互研究感兴趣,请查看指示灯(招生活动刚刚开始)。或关注我们的博客:我们将向您详细介绍学生们今年正在从事的项目。