我认为,几乎每个使用Ruby on Rails和Postgres作为后端主要武器的项目都在开发速度,代码的可读性/可维护性与项目生产速度之间不断挣扎。我将告诉您有关在入口处的可读性和工作速度受到损害的情况下,在这三条鲸鱼之间进行平衡的经验,最后,结果证明这是一些有才华的工程师试图在我之前做的未成功的事情。

整个故事分为几个部分。这是我将第一个谈论PMDSC在优化SQL查询,共享有用的工具以衡量postgres中的查询性能以及让我想起一个仍然有用的旧备忘单上的问题。
现在,经过一段时间,“事后看来”,我了解到,在此案开始时,我根本没想到自己会成功。因此,这篇文章对那些胆大的而不是最有经验的开发人员将是有用的,而不是对于那些看到过裸露的SQL的超级前辈有用的。
输入数据
我们Appbooster正在推广移动应用程序。为了轻松提出和检验假设,我们开发了几种应用程序。它们大多数的后端是Rails API和Postgresql。
自2013年底以来,该出版物的英雄一直在开发中-然后,rails 4.1.0.beta1刚刚发布。从那时起,该项目已发展成为一个完全加载的Web应用程序,该应用程序可在Amazon EC2中的多个服务器上运行,并具有Amazon RDS中的单独数据库实例(具有4个vCPU和16 GB RAM的db.t3.xlarge)。高峰负荷达到25k RPM,平均日负荷为8-10k RPM。
这个故事始于数据库实例,或更确切地说,是其信用余额。
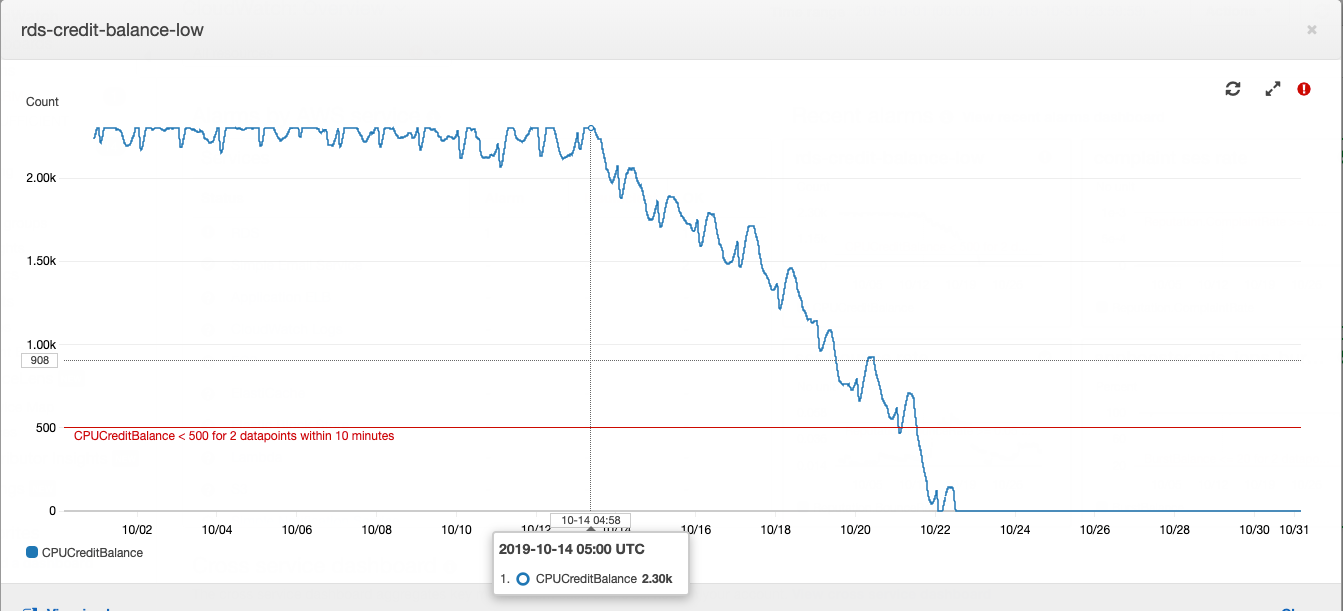
Postgres类型“ t”实例在Amazon RDS中的工作方式:如果数据库运行时的平均CPU消耗低于某个值,则您会在您的账户上累积积分,该实例可以在高负载时间花费在CPU消耗上-这可以节省您多付的钱服务器容量和应付高负载。有关他们使用AWS支付的费用和金额的更多详细信息,请参见我们的CTO文章。
某一时刻的贷款余额已用完。一段时间以来,这并不是很重要,因为可以用钱补充贷款的余额-每月花费大约20美元,这对于租用计算能力的总成本而言并不是很明显。在产品开发中,习惯上主要注意由业务需求制定的任务。数据库服务器增加的CPU消耗增加了技术负担,并被购买信贷余额的少量费用所抵消。
有一天,我在每日摘要中写道,我非常厌倦了熄灭定期出现在项目不同部分的“大火”。如果这种情况继续下去,精疲力尽的开发人员将把时间用于业务任务。当天,我去了项目总经理,解释了对中问题,并要求时间调查定期起火和维修的原因。收到批准后,我开始从各种监视系统收集数据。
我们使用Newrelic跟踪每天的总响应时间。图片如下所示:
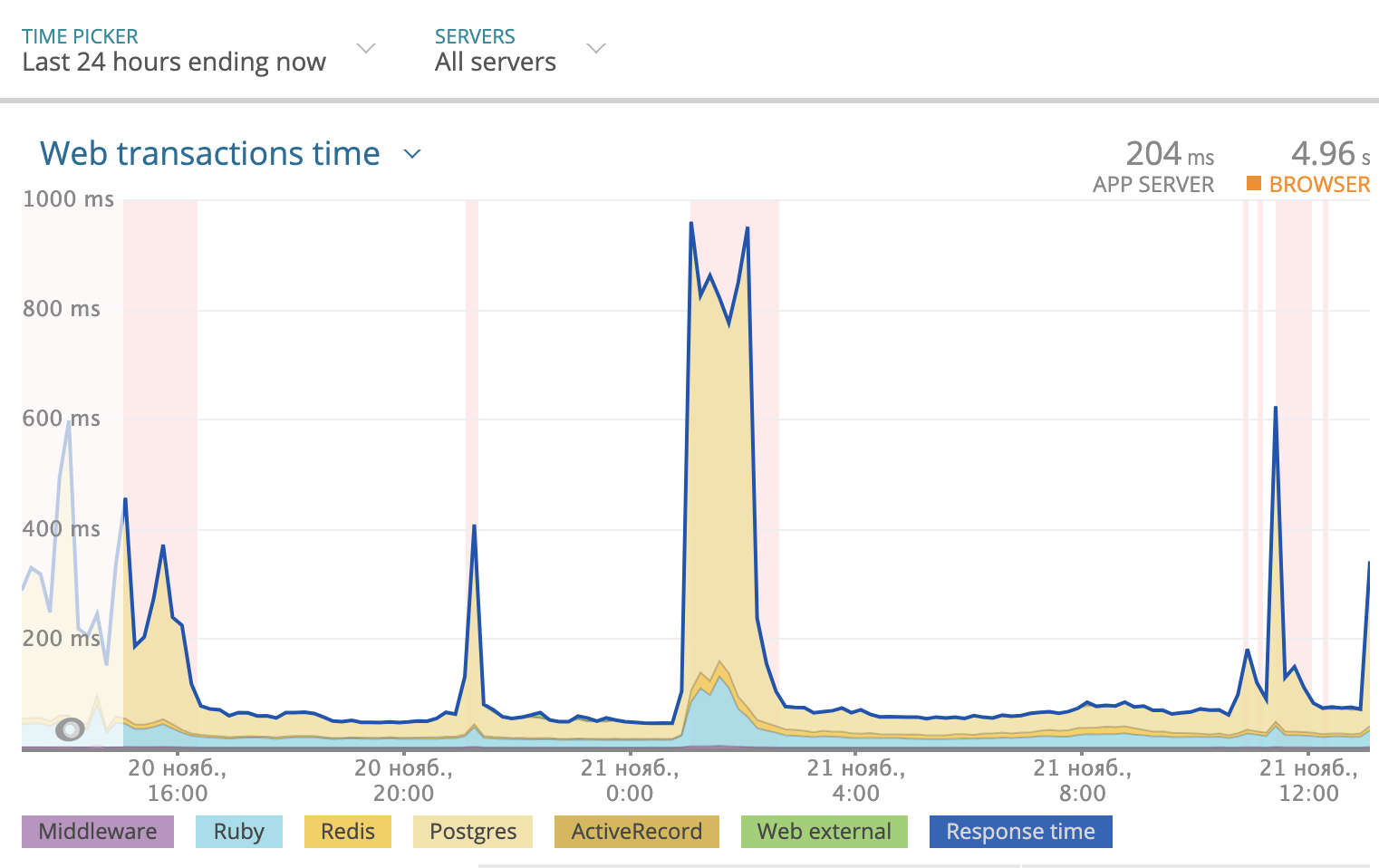
Postgres占用的部分响应时间在图中以黄色突出显示。如您所见,有时响应时间达到1000毫秒,而大多数时间是数据库在思考响应。因此,您需要查看SQL查询的情况。
PMDSC是任何无聊的 SQL优化工作的简单明了的实践
播放!
衡量吧!
画出来!
假设它!
核实!
播放!
也许是整个实践中最重要的部分。当有人说“优化SQL查询”这句话时,它反而使绝大多数人感到打哈欠和无聊。当您说出“侦探调查并寻找危险的恶棍”时,它会更加吸引您并使您自己处于合适的心情。因此,进入游戏很重要。我喜欢扮演侦探。我以为数据库问题可能是危险的罪犯或罕见的疾病。他想象自己扮演的是福尔摩斯,哥伦布中尉或豪斯医生。根据自己的喜好选择英雄,然后出发!
衡量吧!

为了分析请求统计信息,我安装了PgHero。这是从pg_stat_statements Postgres扩展读取数据的非常方便的方法。转到/查询,然后查看最近24小时内所有查询的统计信息。默认情况下,根据“总时间”列-数据库处理查询的总时间的比例-对查询进行排序-查找可疑对象的重要来源。平均时间-该请求平均执行多少次。通话次数-在选定的时间内发出了多少个请求。 PgHero认为,如果每天执行超过100次并且平均花费超过20毫秒,则请求会很慢。慢速查询的列表在首页上,紧接在重复索引列表之后。

我们采用列表中的第一个,并查看查询的详细信息,您可以立即看到它解释分析。如果计划时间比执行时间少得多,则此请求有问题,我们将注意力集中在此可疑对象上。
PgHero有其自己的可视化方法,但我更喜欢使用explain.depesz.com,在其中复制来自explain的数据。
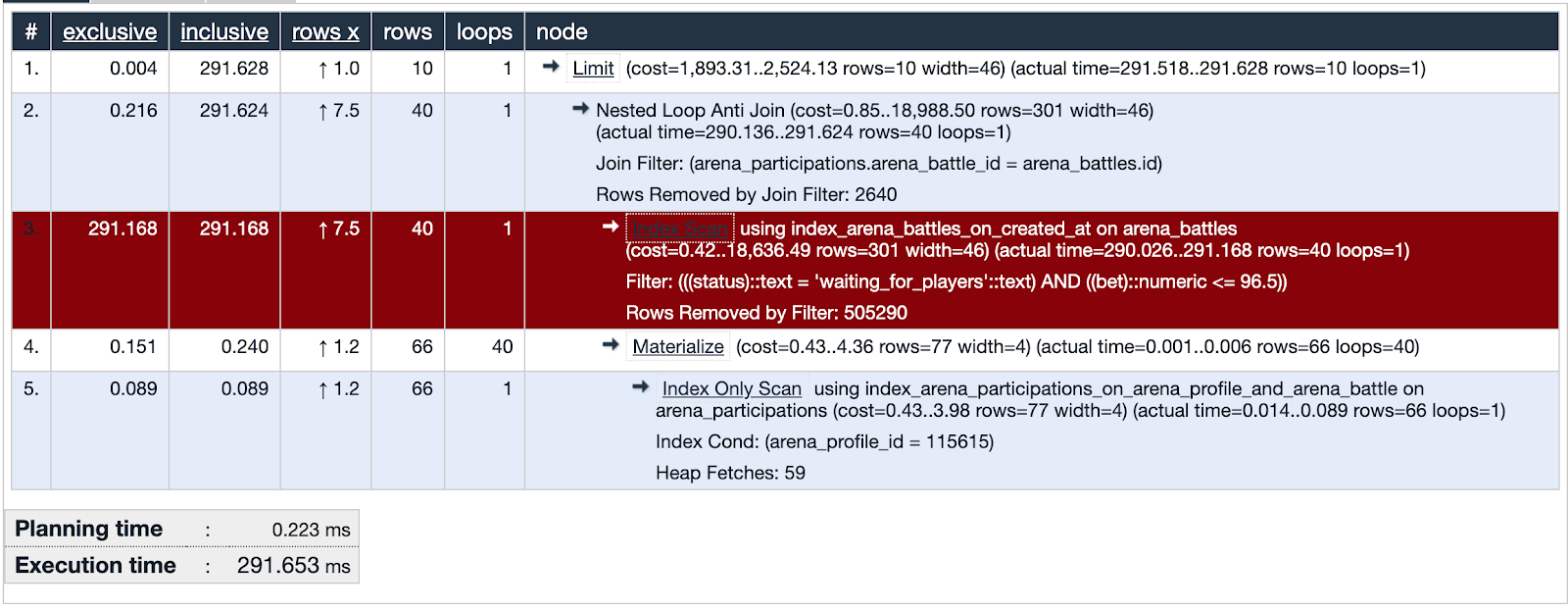
可疑查询之一是使用索引扫描。可视化显示该索引无效,并且是一个弱点-以红色突出显示。精细!我们检查了嫌疑人的踪迹,发现了重要的证据!正义是不可避免的!
画出来!
让我们绘制查询有问题的部分中使用的大量数据。与索引覆盖的数据进行比较将很有用。
有点背景。我们测试了一种将观众吸引到应用程序中的方法之一-类似于彩票,您可以在其中赢得一些当地货币。您下注,猜一个从0到100的数字,如果您的数字最接近随机数生成器收到的数字,则拿整个彩池。我们称它为“竞技场”,称集会为“战斗”。

调查时的数据库包含大约五十万次战斗记录。在请求的问题部分,我们正在寻找价格不超过用户余额且战斗状态正在等待玩家的战斗。我们看到集合的交集(以橙色突出显示)是很少的记录。
请求的可疑部分中使用的索引涵盖了created_at字段上所有已创建的战斗。该请求遍历505330记录,从中选择40条记录,然后505290删除。看起来很浪费。
假设它!
我们提出了一个假设。什么能帮助数据库从五十万条记录中找到四十条?让我们尝试建立一个涵盖费率字段的索引,仅适用于处于“等待玩家”状态的战斗-部分索引。
add_index :arena_battles, :bet,
where: "status = 'waiting_for_players'",
name: "index_arena_battles_on_bet_partial_status"
部分索引 -仅针对符合条件的记录存在:状态字段等于“正在等待玩家”,并为费率字段编制索引-完全符合查询条件。使用此特定索引非常有益:它仅占用40 KB,并且不会覆盖已经进行的战斗,因此我们不需要获取样本。为了进行比较,犯罪嫌疑人使用的index_arena_battles_on_created_at索引大约需要40 MB,带有战斗的表大约需要70 MB。如果其他查询不使用该索引,则可以安全删除。
核实!
我们将使用新索引的迁移部署到生产中,并观察端点在战斗中的响应如何变化。
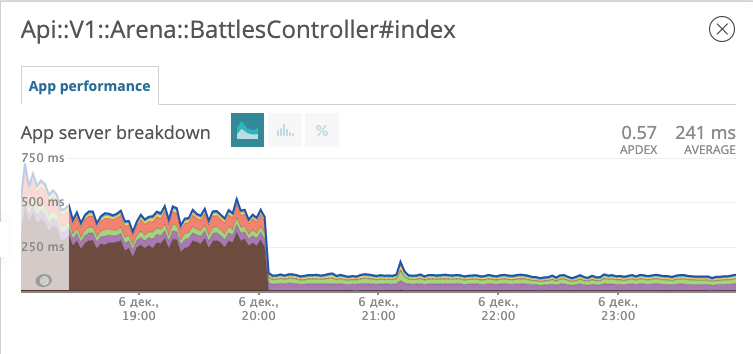
该图显示了我们何时开始进行迁移。在12月6日晚上,响应时间从〜500 ms减少到〜50ms减少了大约10倍。犯罪嫌疑人在法庭上已获得囚徒身份,目前正在监狱中。精细!
越狱
几天后,我们意识到我们很开心。囚犯似乎找到了同伙,制定并实施了逃生计划。
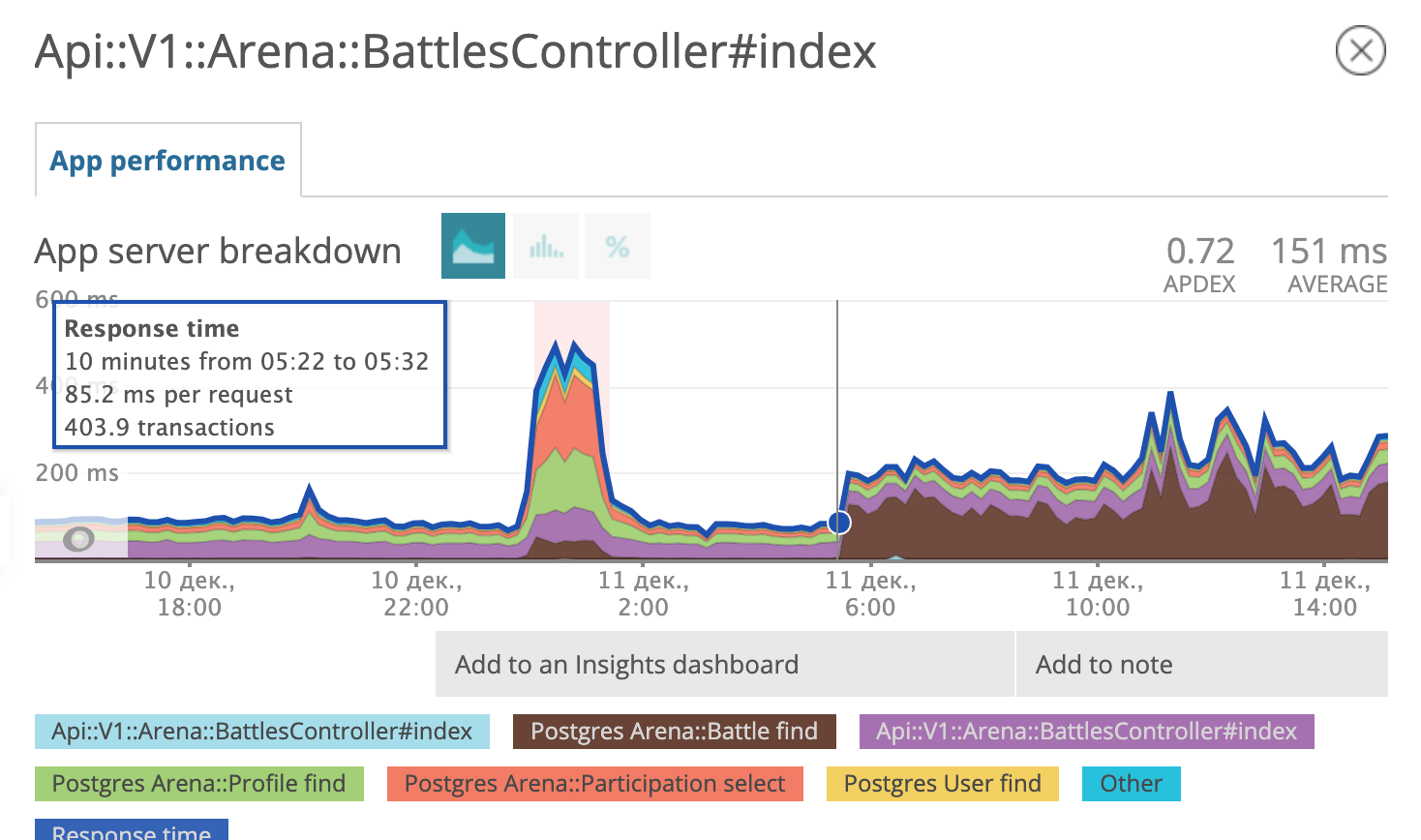
12月11日上午,postgres查询调度程序决定使用新的已解析索引不再对其有利可图,并再次开始使用旧索引。
我们回到了假设阶段!按照豪斯博士的精神,对鉴别诊断进行汇总:
- 可能需要优化postgres设置;
- 也许可以将Postgres升级到较新的版本(9.6.11-> 9.6.15);
- 也许再次仔细研究哪种SQL查询形成Rails?
我们检验了所有三个假设。后者将我们引向了同谋。
SELECT "arena_battles".*
FROM "arena_battles"
WHERE "arena_battles"."status" = 'waiting_for_players'
AND (arena_battles.bet <= 98.13)
AND (NOT EXISTS (
SELECT 1 FROM arena_participations
WHERE arena_battle_id = arena_battles.id
AND (arena_profile_id = 46809)
))
ORDER BY "arena_battles"."created_at" ASC
LIMIT 10 OFFSET 0让我们一起看一下该SQL。我们从战表中选择状态等于“等待玩家”且速率小于或等于一定数量的所有战场。到目前为止,一切都很清楚。条件中的下一项看起来令人毛骨悚然。
NOT EXISTS (
SELECT 1 FROM arena_participations
WHERE arena_battle_id = arena_battles.id
AND (arena_profile_id = 46809)
)我们正在寻找不存在的子查询结果。从战斗参与表中获取第一个字段,其中战斗ID匹配且参与者的个人资料属于我们的玩家。我将尝试绘制子查询中描述的集合。
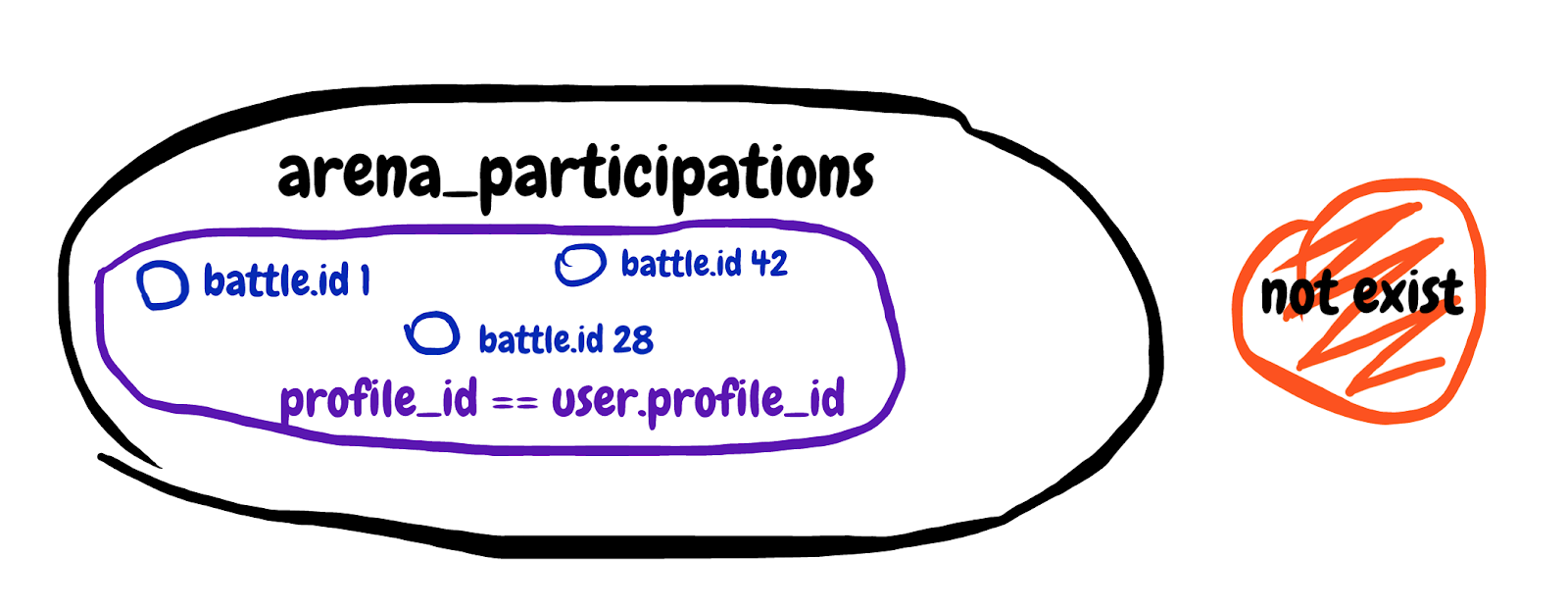
很难理解,但是最后,通过此子查询,我们试图排除玩家已经参与的那些战斗。我们查看查询的一般解释,然后参阅计划时间:0.180毫秒,执行时间:12.119毫秒。我们找到了同伙!
现在是我最喜欢的备忘单的时候了,该备忘单自2008年以来一直在互联网上流行。这是:

是的!一旦查询遇到某些应基于来自另一个表的数据的特定数量记录的记录,该带有胡须和卷发的模因应该在内存中弹出。
实际上,这就是我们需要的:

自行保存此图片,或者更好的是,将其打印并挂在办公室的几个位置。
我们将子查询重写为LEFT JOIN WHERE B.key IS NULL,得到:
SELECT "arena_battles".*
FROM "arena_battles"
LEFT JOIN arena_participations
ON arena_participations.arena_battle_id = arena_battles.id
AND (arena_participations.arena_profile_id = 46809)
WHERE "arena_battles"."status" = 'waiting_for_players'
AND (arena_battles.bet <= 98.13)
AND (arena_participations.id IS NULL)
ORDER BY "arena_battles"."created_at" ASC
LIMIT 10 OFFSET 0更正后的查询一次跨两个表运行。我们在“左侧”添加了一个表格,其中包含用户参与战斗的记录,并添加了不存在参与标识符的条件。让我们看一下分析接收到的查询的解释:计划时间:0.185 ms,执行时间:0.337 ms。精细!现在,查询计划者会毫不犹豫地使用部分索引,但会使用最快的选项。逃脱的囚犯及其同伙在严格的政权机构中被判处无期徒刑。他们将更难逃脱。
摘要是简短的。
- 使用Newrelic或其他类似的服务来查找潜在客户。我们意识到问题恰在数据库查询中。
- 使用PMDSC做法-它有效并且在任何情况下都非常吸引人。
- 使用PgHero查找可疑对象并调查SQL查询统计信息中的线索。
- 使用explain.depesz.com-可以轻松地在其中阅读解释分析查询。
- 当您不知道请求到底在做什么时,尝试绘制大量数据。
- 当您看到一个子查询正在寻找另一个表中没有的东西时,想想硬汉满头卷曲。
- 扮演侦探,您甚至可能会获得徽章。