 关于计算语言学和智能技术的国际科学会议“ 对话2020”最近结束了。MIPT应用数学和信息学物理技术学院(FPMI)首次成为会议的合作伙伴。传统上,对话的关键事件之一是对话评估,这是语言文本分析自动系统的开发人员之间的竞争。我们已经在Habré上谈论了比赛参赛者去年解决的任务,例如,关于生成标题和查找文本中遗漏的单词的问题... 今天,我们与今年对话评估的两个方面的获胜者进行了交谈-弗拉迪斯拉夫·科尔佐恩(Vladislav Korzun)和丹尼尔·阿纳斯塔西耶夫(Daniil Anastasyev)-关于他们决定参加技术竞赛的原因,遇到的问题和解决的方式,这些人感兴趣的东西,研究的地方以及未来计划做的事情。欢迎来到猫!
关于计算语言学和智能技术的国际科学会议“ 对话2020”最近结束了。MIPT应用数学和信息学物理技术学院(FPMI)首次成为会议的合作伙伴。传统上,对话的关键事件之一是对话评估,这是语言文本分析自动系统的开发人员之间的竞争。我们已经在Habré上谈论了比赛参赛者去年解决的任务,例如,关于生成标题和查找文本中遗漏的单词的问题... 今天,我们与今年对话评估的两个方面的获胜者进行了交谈-弗拉迪斯拉夫·科尔佐恩(Vladislav Korzun)和丹尼尔·阿纳斯塔西耶夫(Daniil Anastasyev)-关于他们决定参加技术竞赛的原因,遇到的问题和解决的方式,这些人感兴趣的东西,研究的地方以及未来计划做的事情。欢迎来到猫!
Vladislav Korzun,对话评估RuREBus-2020曲目获得者

你是做什么?
我是ABBYY的NLP Advanced Research Group的开发人员。我们目前正在解决提取实体的一键式学习任务。也就是说,只有少量的培训样本(5-10个文档),您需要学习如何从相似的文档中提取特定实体。为此,我们将使用在标准实体类型(人,位置,组织)上训练好的NER模型的输出作为解决此问题的功能。我们还计划使用一种特殊的语言模型,该模型在主题与我们的任务相似的文档上进行了培训。
您在“对话评估”中解决了哪些任务?
在对话中,我参加了RuREBus竞赛,该竞赛致力于从经济发展部语料库的特定文档中提取实体和关系。这种情况与例如在Conll比赛中使用的情况有很大不同。首先,实体本身的类型不是标准的(人员,位置,组织),其中甚至还包括未命名和实质性的行为。其次,文本本身不是经过验证的句子集,而是真实的文档,导致了各种各样的列表,标题,甚至表格。结果,主要困难恰恰出现在数据处理中,而不是解决问题上。实际上,这些是经典的命名实体识别和关系提取任务。
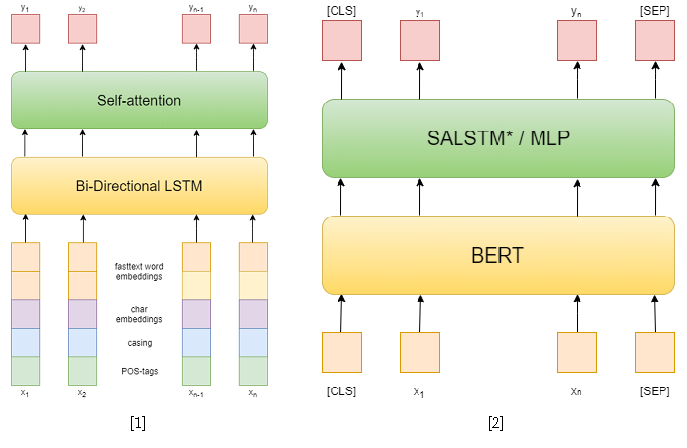
在比赛本身中,共有3条赛道:NER,具有给定实体的RE和端到端RE。我试图解决前两个问题。在第一个任务中,我使用了经典方法。首先,我尝试使用循环网络作为模型,并使用快速文本词嵌入,大写模式,符号嵌入和POS标签作为特征[1]。然后,我已经使用了各种预训练的BERT [2],它们比我以前的方法要好得多。但是,这还不足以在这一轨道上占据第一位。
但是在第二条轨道上,我成功了。为了解决提取关系的问题,我将其简化为对关系进行分类的问题,类似于SemEval 2010 Task 8。在这个问题中,对于每个句子,给出一对实体,为此需要对关系进行分类。在轨道中,每个句子可以包含任意数量的实体,但是,只需对每对实体采样该句子,就可以简化为上一个。另外,在训练过程中,我随机抽取了每个句子的否定示例,其大小不超过肯定句数的两倍,以减少训练样本。
作为解决关系分类问题的方法,我使用了两个基于BERT-e的模型。在第一个中,我简单地将BERT输出与NER嵌入连接起来,然后使用自我注意[3]对每个令牌的特征求平均值。第二个模型是SemEval 2010 Task 8的最佳解决方案之一-R-BERT [4]。这种方法的本质如下:在每个实体之前和之后插入特殊令牌,对每个实体的令牌的BERT输出求平均,将结果向量与对应于CLS令牌的输出合并,并对结果特征向量进行分类。结果,该模型在赛道上排名第一。比赛结果可在此处获得。
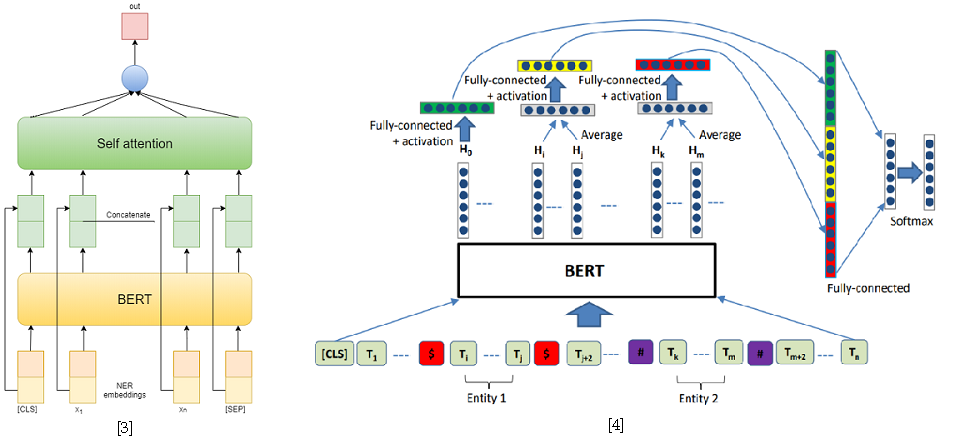
[4] Wu,S.,He,Y.(2019年11月)。使用实体信息丰富预训练语言模型以进行关系分类。在第28届ACM国际信息和知识管理会议论文集(pp。2361-2364)中。
在您看来,这些任务中最困难的是什么?
问题最大的是案件的处理。任务本身尽可能地经典,对于它们的解决方案,已经有现成的框架,例如AllenNLP。但是答案必须与保存令牌跨度有关,所以我不能不使用大量现成的代码而仅使用现成的管道。因此,我决定用纯PyTorch编写整个管道,以免遗漏任何东西。尽管我仍然使用AllenNLP的一些模块。
语料库中还有很多相当长的句子,这在教大型变压器(例如BERT)时带来不便,因为 随着句子长度的增加,它们对视频存储的要求也越来越高。但是,这些句子中大多数都是用分号分隔的枚举,并且可以用该字符分隔。我只是将剩余报价除以令牌的最大数量。
您以前参加过对话和曲目吗?
去年,我在学生会上讲了我的硕士学位。
您为什么决定今年参加比赛?
这时候,我只是在解决关系提取的问题,但是是针对其他军团的。我试图基于解析树使用其他方法。树中从一个实体到另一个实体的路径用作输入。但是遗憾的是,尽管这种方法与基于递归网络的方法处于同一水平,但使用令牌嵌入和其他特征作为标志,例如从令牌到根或语法树中实体之一的路径长度,尽管这种方法与基于递归网络的方法处于同一水平。解析以及实体的相对位置。
我决定参加此竞赛,因为我已经为解决类似问题做好了一些基础工作。为什么不将它们应用到比赛中并发布呢?事实证明,这并不像我想象的那么容易,而是由于与船体的交互问题。结果,对我来说,它不仅仅是研究工作,而是工程任务。
你参加过其他比赛吗?
同时,我们的团队参加了SemEval。伊利亚·迪莫夫(Ilya Dimov)主要参与任务,我只是提出了一些想法。宣传的任务是分类:选择文本的跨度,有必要对其进行分类。我建议使用R-BERT方法,即在标记中选择该实体,在其前面和后面插入一个特殊的标记,然后对输出求平均值。结果,这增加了一点。这是科学价值:为了解决问题,我们使用了为完全不同的事物设计的模型。
我还参加了ACM icpc的ABBYY hackathon,这是第一年的体育节目竞赛。那时我们还没走的很远,但是很有趣。这种竞赛与在对话中提出的竞赛有很大的不同,在对话中有足够的时间冷静地实施和测试几种方法。在黑客马拉松比赛中,您需要快速进行所有操作,没有时间放松身心,没有茶。但这就是此类事件的美-它们具有特定的氛围。
您在比赛或工作中解决的最有趣的问题是什么?
即将举行GENEA手势产生比赛,我要去那里。我认为这将很有趣。这是ACM 国际智能虚拟代理大会上的一个研讨会。在该竞赛中,提出了基于语音生成用于3D人体模型的手势。我今年在“对话”中谈到了类似的话题,并简要概述了从语音自动生成面部表情和手势的方法。我需要获得经验,因为我仍然必须为类似主题的论文辩护。我想尝试创建一个具有面部表情,手势和语音的阅读虚拟代理。当前的语音合成方法允许从文本生成相当真实的语音,而手势生成方法允许从语音生成手势。那么,为什么不结合使用这些方法呢?
顺便问一下,您现在在哪里学习?
我是MIPT应用数学和信息学物理技术学院 ABBYY计算语言学系的研究生。我将在两年内为我的论文辩护。
现在在大学获得的哪些知识和技能对您有帮助?
奇怪的是,数学。即使我不是每天都在积分,也不在我脑海中相乘矩阵,但数学仍会教授分析性思维和找出任何事物的能力。毕竟,任何考试都包括证明定理,而试图学习这些定理是没有用的,但是理解和证明自己,只记得一个主意是可能的。我们还开设了不错的编程课程,从低级学习,以了解一切工作原理,分析了各种算法和数据结构。现在,处理新框架甚至编程语言将不再是问题。是的,当然,我们开设了机器学习课程,特别是关于NLP的课程,但是在我看来,基本技能仍然更为重要。
Daniil Anastasyev,“对话评估GramEval-2020”曲目获得者

你是做什么?
我正在开发语音助手“爱丽丝”,我正在寻找意义小组。我们分析了对Alice的要求。查询的标准示例是“明天莫斯科的天气如何?” 您需要了解这是关于天气的请求,该请求询问的是位置(莫斯科),并且有时间指示(明天)。
在“对话评估”曲目之一中告诉我们您今年解决的问题。
我所做的任务非常接近ABBYY所做的事情。有必要建立一个模型来分析句子,进行形态和句法分析,并定义引理。这与他们在学校所做的非常相似。建立模型花了我大约5天的时间。

该模型使用普通俄语进行了研究,但是,正如您所看到的,它也可以使用问题所在的语言。
这听起来像您的工作吗?
可能不是。在这里,您需要了解,此任务本身并没有多大意义-在解决一些重要的业务问题的框架中,将其作为子任务来解决。因此,例如,在我曾经工作过的ABBYY中,语素-句法分析是解决信息提取问题的初始阶段。在当前任务的框架内,我不需要进行此类分析。但是,使用诸如BERT之类的经过预训练的语言模型的额外经验似乎肯定对我的工作很有用。总的来说,这是参与的主要动机-我不想赢,但要练习并获得一些有用的技能。另外,我的文凭部分与问题有关。
您以前参加过对话评估吗?
在第5年参加了MorphoRuEval-2017赛道,然后获得了第1名。然后有必要仅定义形态和引理,而没有句法关系。
立即将模型应用于其他任务是否现实?
是的,我的模型可以用于其他任务-我已经发布了所有源代码。我计划使用更轻,更快,但精度更低的模型发布代码。从理论上讲,如果有人愿意,可以使用当前模型。问题在于,对于大多数人来说,它将太大而又缓慢。在竞争中,没人在乎速度,要达到最高的质量很有趣,但是在实际应用中,一切通常都是相反的。因此,此类大型模型的主要好处是知道最可实现的质量,以便了解您要牺牲的质量。
您为什么参加对话评估和其他类似比赛?
黑客马拉松和此类比赛与我的工作没有直接关系,但仍然是有益的经历。例如,去年我参加AI Journey hackathon时,我学到了一些我后来在工作中使用的东西。任务是学习如何通过俄语考试,即解决测试问题并撰写论文。显然,所有这些都与工作无关。但是快速提出并训练可以解决某些问题的模型的功能非常有用。顺便说一句,我和我的团队赢得了第一名。
您获得了什么教育,大学毕业后您做了什么?
他毕业于莫斯科物理技术学院计算语言学系ABBYY的学士和硕士学位,于2018年毕业。他还曾在数据分析学院(SHAD)学习。在第二年选择基础部门时,我们小组中的大多数人都去了ABBYY部门-计算语言学或图像识别和文本处理。在本科课程中,我们被教导要很好地编程-有非常有用的课程。从第四年开始,我在ABBYY工作了2.5年。首先,在形态学小组中,然后我从事与语言模型有关的任务,以改善ABBYY FineReader中的文本识别。我编写了代码,训练有素的模型,但现在我做的是相同的,只是针对完全不同的产品。
你如何度过你的空闲时间?
我喜欢看书。根据季节,我会尝试跑步或滑雪。我在旅行时喜欢摄影。
您有未来5年的计划或目标吗?
5年的规划视野太远了。我什至没有5年的工作经验。在过去的5年中,发生了很多变化,现在显然有一种与生活不同的感觉。我几乎无法想象还有什么可以改变的,但是有人想到要在国外获得博士学位。
您可以给从事计算语言学的年轻开发人员什么建议?
最好练习,尝试和竞争。完整的初学者可以参加许多课程之一:例如,来自SHAD,DeepPavlov甚至我自己的课程,我曾经在ABBYY 任教过。
, ABBYY : () (). 15 brains@abbyy.com , , GPA 5- 10- .
, ABBYY – .