
使用Kubernetes时如何节省云成本?唯一正确的解决方案并不存在,但是本文介绍了一些工具,这些工具将帮助您更有效地管理资源并降低云计算成本。
我写这篇文章时着眼于Kubernetes for AWS,但它(几乎)将以相同的方式应用于其他云提供商。我假设您的集群已经配置了自动缩放(cluster-autoscaler)。删除资源并缩减部署规模只会节省您的工作程序节点(EC2实例)数量,因此可以节省您的时间。
本文将介绍:
- 清理未使用的资源(kube-janitor)
- 在非工作时间缩小(kube-downscaler)
- 使用水平自动缩放(HPA),
- 减少资源超量预订(kube-resource-report,VPA)
- 使用竞价型实例
清理未使用的资源
在快节奏的环境中工作很棒。我们希望技术组织加速发展。更快的软件交付还意味着更多的PR部署,预览环境,原型和分析解决方案。一切都可以部署在Kubernetes上。谁有时间手动清理测试部署?忘记删除为期一周的实验很容易。由于我们忘记了结账,云账单最终将上涨:

(Henning Jacobs:
Zhiza :(
引用)Corey Quinn:
神话:您的AWS账户是用户数量的函数。
事实:您的AWS账户是工程师数量的函数
。Ivan Kurnosov(作为回应):
实际情况:您的AWS账户的功能取决于您忘记禁用/删除的东西的数量。)
Kubernetes Janitor(kube-janitor)帮助清理您的集群。管理员配置可灵活用于全局和本地使用:
- 整个群集的通用规则可以定义PR /测试部署的最长生存时间(TTL)。
- 可以使用janitor / ttl注释单个资源,例如在7天后自动删除峰值/原型。
通用规则在YAML文件中定义。它的路径通过参数传递
--rules-file给kube-janitor。这是一个示例规则,用于-pr-在两天内删除具有名称的所有名称空间:
- id: cleanup-resources-from-pull-requests
resources:
- namespaces
jmespath: "contains(metadata.name, '-pr-')"
ttl: 2d以下示例规范了2020年所有新的Deployments / StatefulSet的Deployment和StatefulSet窗格上的应用程序标签的使用,但同时允许在没有该标签的情况下执行测试一周:
- id: require-application-label
# deployments statefulsets "application"
resources:
- deployments
- statefulsets
# . http://jmespath.org/specification.html
jmespath: "!(spec.template.metadata.labels.application) && metadata.creationTimestamp > '2020-01-01'"
ttl: 7d在运行kube-janitor的集群上运行限时演示30分钟:
kubectl run nginx-demo --image=nginx
kubectl annotate deploy nginx-demo janitor/ttl=30m成本上升的另一个来源是持续量(AWS EBS)。删除Kubernetes StatefulSet不会删除其持久卷(PVC-PersistentVolumeClaim)。EBS的未使用量很容易导致每月数百美元的成本。Kubernetes Janitor具有清理未使用的PVC的功能。例如,此规则将删除未由吊舱安装且未被StatefulSet或CronJob引用的所有PVC:
# PVC, StatefulSets
- id: remove-unused-pvcs
resources:
- persistentvolumeclaims
jmespath: "_context.pvc_is_not_mounted && _context.pvc_is_not_referenced"
ttl: 24hKubernetes Janitor可以帮助您保持群集清洁,并防止云计算成本的缓慢增长。有关部署和配置的说明,请遵循kube-janitor README。
在下班时间减少水垢
通常要求测试和登台系统仅在工作时间内运行。某些生产应用程序(例如后台办公/管理工具)也仅需要有限的可用性,并且可以在晚上关闭。
Kubernetes Downscaler(kube-downscaler)允许用户和操作员在下班时间缩减系统规模。部署和StatefulSets可以扩展到零个副本。 CronJobs可能会被暂停。 Kubernetes Downscaler为整个集群,一个或多个名称空间或单个资源配置。您可以设置“空闲时间”,反之亦然,可以设置“运行时间”。例如,为尽可能减少过夜和周末的缩放比例:
image: hjacobs/kube-downscaler:20.4.3
args:
- --interval=30
#
- --exclude-namespaces=kube-system,infra
# kube-downscaler, Postgres Operator,
- --exclude-deployments=kube-downscaler,postgres-operator
- --default-uptime=Mon-Fri 08:00-20:00 Europe/Berlin
- --include-resources=deployments,statefulsets,stacks,cronjobs
- --deployment-time-annotation=deployment-time这是一个用于在周末扩展集群工作节点的图表:

从约13个工作节点缩减到4个工作节点无疑会在AWS账单上产生巨大的差异。
但是,如果我需要在集群的“停机时间”内工作怎么办?通过添加降级器/ exclude:true批注,可以将某些部署永久地从扩展中排除。可以使用降级器/ exclude-until批注(带有绝对时间戳)以YYYY-MM-DD HH:MM(UTC)格式暂时排除部署。如有必要,可以通过部署带注释的pod来缩减整个集群
downscaler/force-uptime,例如通过运行nginx dummy:
kubectl run scale-up --image=nginx
kubectl annotate deploy scale-up janitor/ttl=1h #
kubectl annotate pod $(kubectl get pod -l run=scale-up -o jsonpath="{.items[0].metadata.name}") downscaler/force-uptime=true有关部署说明和其他选项,请参见README kube-downscaler。
使用水平自动缩放
许多应用程序/服务都处理动态加载方案:有时它们的模块处于空闲状态,有时它们以最大容量运行。以恒定的炉床数量来应对最大峰值负荷是不经济的。 Kubernetes通过HorizontalPodAutoscaler(HPA)资源支持水平自动缩放。 CPU使用率通常是扩展的好指标:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: my-app
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 100
type: UtilizationZalando创建了一个组件,可以轻松连接自定义指标以进行缩放:Kube Metrics适配器(kube-metrics-adapter)是Kubernetes的通用指标适配器,可以收集和维护用于水平炉床自动缩放的自定义指标和外部指标。它支持基于Prometheus指标,SQS队列和其他设置的扩展。例如,要扩展由应用程序本身表示为/指标中的JSON的自定义指标的部署,请使用:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
annotations:
# metric-config.<metricType>.<metricName>.<collectorName>/<configKey>
metric-config.pods.requests-per-second.json-path/json-key: "$.http_server.rps"
metric-config.pods.requests-per-second.json-path/path: /metrics
metric-config.pods.requests-per-second.json-path/port: "9090"
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metric:
name: requests-per-second
target:
averageValue: 1k
type: AverageValue使用HPA配置水平自动缩放应该是提高无状态服务效率的默认操作之一。Spotify的演讲介绍了他们的经验以及对HPA的建议:扩展您的部署,而不是您的钱包。
减少冗余资源预留
Kubernetes工作负载通过“资源请求”确定其CPU /内存需求。 CPU资源以虚拟核心为单位进行测量,或更常用“千分之一”来衡量,例如500m表示50%vCPU。内存资源以字节为单位,可以使用常见的后缀,例如500Mi表示500兆字节。资源请求“锁定”了工作节点上的容量,即,在具有4个vCPU的节点上具有1000m CPU请求的模块将仅使3个vCPU可供其他模块使用。[1]
松弛(储备过多)-这是请求的资源与实际使用之间的差异。例如,请求2 GiB内存但仅使用200 MiB的Pod具有〜1.8 GiB的“多余”内存。多余的钱。可以粗略估计出1 GiB的额外内存每月需要花费约10美元。[2]
Kubernetes资源报告(kube-resource-report)显示多余的储备,可以帮助您确定潜在的节省:

Kubernetes资源报告显示按应用程序和团队汇总的多余金额。这使您可以找到可以减少资源请求的位置。生成的HTML报告仅提供资源使用情况的快照。您应该查看一段时间内的CPU /内存使用情况,以确定足够的资源请求。这是“典型的”高CPU使用率服务的Grafana图:所有Pod使用的CPU内核数明显少于3个:
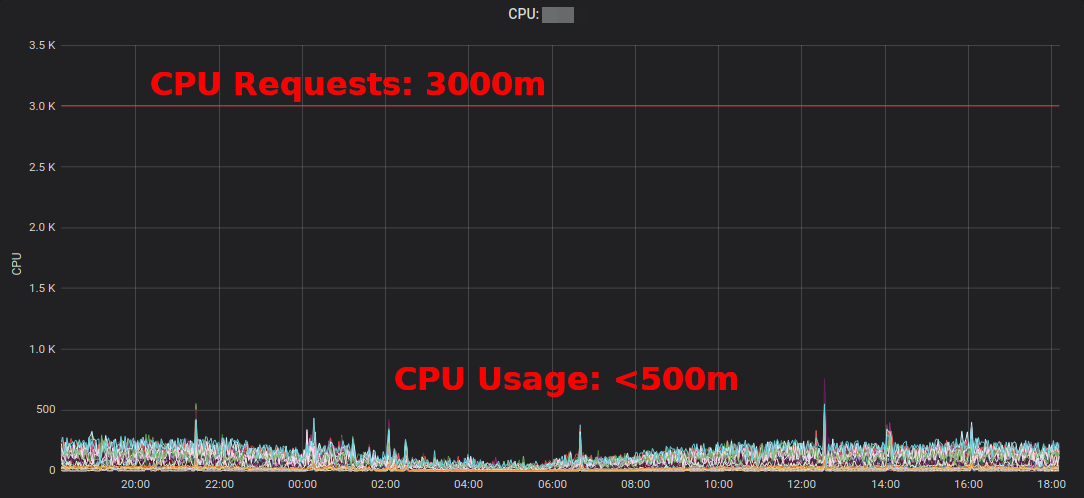
将CPU请求从3000m减少到〜400m释放了用于其他工作负载的资源,并允许集群缩减。
“ EC2实例的平均CPU使用率通常在百分之一的范围内,” Corey Quinn写道。而对于EC2,估计正确的大小可能是一个错误的决定在YAML文件中更改某些Kubernetes资源请求很容易,并且可以节省大量资金。
但是我们真的希望人们更改YAML文件中的值吗?不,汽车可以做得更好! Kubernetes Vertical Pod Autoscaler(VPA)就是这样做的:调整资源请求和约束以适应工作负载。这是VPA随时间变化的Prometheus CPU请求(蓝色细线)图的示例:

Zalando在其所有群集中将VPA用于基础架构组件。非关键应用程序也可以使用VPA。
金发姑娘Fairwind的“工具”工具可为命名空间中的每个部署创建VPA,然后在其仪表板中显示VPA建议。它可以帮助开发人员为其应用程序设置正确的cpu /内存请求:

我在2019年撰写了一篇有关VPA的小型博客文章,最近在CNCF最终用户社区中对VPA进行了讨论。
使用EC2竞价型实例
最后但并非最不重要的一点是,可以通过使用Spot实例作为Kubernetes工作节点来降低AWS EC2成本[3]。竞价型实例可按需提供最高90%的折扣。在EC2 Spot上运行Kubernetes是一个很好的组合:您需要指定几种不同的实例类型以提高可用性,这意味着您可以以相同或更低的价格获得一个更大的节点,而增加的容量可用于容器化的Kubernetes工作负载。
如何在EC2 Spot上运行Kubernetes?有几种选择:使用诸如SpotInst(现在称为Spot,不要问我为什么)之类的第三方服务,或简单地将Spot AutoScalingGroup(ASG)添加到您的集群中。例如,这是一个CloudFormation代码段,用于具有多个实例类型的“容量优化”竞价型ASG:
MySpotAutoScalingGroup:
Properties:
HealthCheckGracePeriod: 300
HealthCheckType: EC2
MixedInstancesPolicy:
InstancesDistribution:
OnDemandPercentageAboveBaseCapacity: 0
SpotAllocationStrategy: capacity-optimized
LaunchTemplate:
LaunchTemplateSpecification:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
Overrides:
- InstanceType: "m4.2xlarge"
- InstanceType: "m4.4xlarge"
- InstanceType: "m5.2xlarge"
- InstanceType: "m5.4xlarge"
- InstanceType: "r4.2xlarge"
- InstanceType: "r4.4xlarge"
LaunchTemplate:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
MinSize: 0
MaxSize: 100
Tags:
- Key: k8s.io/cluster-autoscaler/node-template/label/aws.amazon.com/spot
PropagateAtLaunch: true
Value: "true"关于将Spot与Kubernetes结合使用的一些注意事项:
摘要
我希望您发现此处介绍的一些工具可减少您的云计算费用。您还可以在我的DevOps Gathering 2019 YouTube演讲和幻灯片中找到大部分内容。
在Kubernetes上节省云成本的最佳实践是什么?请在Twitter(@try_except_)上告诉我们。
[1]实际上,由于保留的系统资源会降低节点的吞吐量,因此少于3个虚拟CPU将保持可用状态。Kubernetes区分节点的物理容量和“分配的”资源(Node Allocatable)。
[2]计算示例:带有8 GiB内存的m5.large的一个副本每月约为84 USD(eu-central-1,按需),即 1/8结阻塞约为每月$ 10。
[3]还有许多减少EC2帐户的方法,例如预留实例,储蓄计划等。-我在这里不介绍这些主题,但是您一定应该了解它们!
了解有关该课程的更多信息。