
介绍
异步编程是一种并行编程,其中一个工作单元可以与主应用程序执行线程分开执行。工作完成后,主线程会收到工作流程完成或发生错误的通知。这种方法有很多好处,例如,提高了应用程序性能和响应速度。
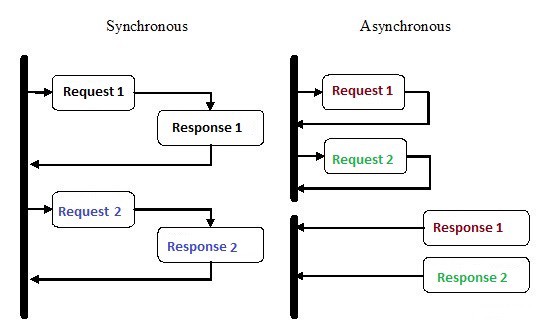
异步编程在过去几年中受到了很多关注,这是有充分理由的。尽管这种编程比传统的顺序执行要复杂得多,但效率却高得多。
例如,您可以发送请求并使用Python中的异步协程进行排队等待的其他工作,而不是在继续执行之前等待HTTP请求完成。
异步是Node.js广泛用于后端实现的主要原因之一。我们编写的许多代码,尤其是在I / O繁重的应用程序(如网站)中,都取决于外部资源。它可以包含从远程数据库调用到POST请求到REST服务的所有内容。将请求发送到这些资源之一后,您的代码将只等待响应。使用异步编程,可以让代码在等待资源响应时处理其他任务。
Python如何一次完成几件事?

1.多个进程
最明显的方法是使用多个进程。在终端上,您可以运行脚本两次,三遍,四遍,十遍,并且所有脚本将独立且同时执行。操作系统将负责在所有实例之间分配处理器资源。另外,您可以使用multiprocessing库,该库可以产生多个进程,如下例所示。
from multiprocessing import Process
def print_func(continent='Asia'):
print('The name of continent is : ', continent)
if __name__ == "__main__": # confirms that the code is under main function
names = ['America', 'Europe', 'Africa']
procs = []
proc = Process(target=print_func) # instantiating without any argument
procs.append(proc)
proc.start()
# instantiating process with arguments
for name in names:
# print(name)
proc = Process(target=print_func, args=(name,))
procs.append(proc)
proc.start()
# complete the processes
for proc in procs:
proc.join()输出:
The name of continent is : Asia
The name of continent is : America
The name of continent is : Europe
The name of continent is : Africa2.多个线程
并行运行多个作业的另一种方法是使用线程。线程是一个执行队列,与进程非常相似,但是,您可以在一个进程中拥有多个线程,并且所有线程都将共享资源。但是,因此将很难编写流代码。同样,操作系统将完成分配处理器内存的所有艰苦工作,但是全局解释器锁(GIL)将一次只允许运行一个Python线程,即使您具有多线程代码也是如此。这就是CPython上的GIL如何防止多核并发。也就是说,即使您有两个,四个或更多,您也只能强制在一个内核上运行。
import threading
def print_cube(num):
"""
function to print cube of given num
"""
print("Cube: {}".format(num * num * num))
def print_square(num):
"""
function to print square of given num
"""
print("Square: {}".format(num * num))
if __name__ == "__main__":
# creating thread
t1 = threading.Thread(target=print_square, args=(10,))
t2 = threading.Thread(target=print_cube, args=(10,))
# starting thread 1
t1.start()
# starting thread 2
t2.start()
# wait until thread 1 is completely executed
t1.join()
# wait until thread 2 is completely executed
t2.join()
# both threads completely executed
print("Done!")输出:
Square: 100
Cube: 1000
Done!3.协程和
yield:
协程是子例程的泛化。当进程
yield以某个频率或在等待期间允许多个应用程序同时工作时自愿放弃控制()时,它们可用于协作式多任务处理。协程与生成器类似,但是附加的方法和我们使用yield语句的方式略有变化。生成器产生用于迭代的数据,而协程也可以消耗数据。
def print_name(prefix):
print("Searching prefix:{}".format(prefix))
try :
while True:
# yeild used to create coroutine
name = (yield)
if prefix in name:
print(name)
except GeneratorExit:
print("Closing coroutine!!")
corou = print_name("Dear")
corou.__next__()
corou.send("James")
corou.send("Dear James")
corou.close()输出:
Searching prefix:Dear
Dear James
Closing coroutine!!4.异步编程
第四种方法是异步编程,其中不涉及操作系统。在操作系统方面,您只剩下一个线程的一个进程,但是您仍然可以同时执行多个任务。那么诀窍是什么?
答:
asyncio
Asyncio-Python 3.4中引入的异步编程模块。它旨在使用协程和期货来简化异步代码的编写,并且由于缺少回调,使其几乎与同步代码一样可读。
Asyncio使用不同的结构:,event loop协程和future。
- event loop . .
- ( ) – , Python, await event loop. event loop. Tasks, Future.
- Future , . exception.
借助该帮助,
asyncio您可以构建代码结构,以便将子任务定义为协程,并允许您安排它们按需运行,包括同时运行。协程包含yield我们定义可能的上下文切换点的点。如果等待队列中有任务,则将切换上下文;否则,否。
上下文切换
asyncio是event loop一种将控制流从一个协程转移到另一个协程的开关。
在以下示例中,我们运行3个异步任务,分别向Reddit发出请求,检索和输出JSON内容。我们使用aiohttp -http客户端库,可确保即使HTTP请求也将异步执行。
import signal
import sys
import asyncio
import aiohttp
import json
loop = asyncio.get_event_loop()
client = aiohttp.ClientSession(loop=loop)
async def get_json(client, url):
async with client.get(url) as response:
assert response.status == 200
return await response.read()
async def get_reddit_top(subreddit, client):
data1 = await get_json(client, 'https://www.reddit.com/r/' + subreddit + '/top.json?sort=top&t=day&limit=5')
j = json.loads(data1.decode('utf-8'))
for i in j['data']['children']:
score = i['data']['score']
title = i['data']['title']
link = i['data']['url']
print(str(score) + ': ' + title + ' (' + link + ')')
print('DONE:', subreddit + '\n')
def signal_handler(signal, frame):
loop.stop()
client.close()
sys.exit(0)
signal.signal(signal.SIGINT, signal_handler)
asyncio.ensure_future(get_reddit_top('python', client))
asyncio.ensure_future(get_reddit_top('programming', client))
asyncio.ensure_future(get_reddit_top('compsci', client))
loop.run_forever()输出:
50: Undershoot: Parsing theory in 1965 (http://jeffreykegler.github.io/Ocean-of-Awareness-blog/individual/2018/07/knuth_1965_2.html)
12: Question about best-prefix/failure function/primal match table in kmp algorithm (https://www.reddit.com/r/compsci/comments/8xd3m2/question_about_bestprefixfailure_functionprimal/)
1: Question regarding calculating the probability of failure of a RAID system (https://www.reddit.com/r/compsci/comments/8xbkk2/question_regarding_calculating_the_probability_of/)
DONE: compsci
336: /r/thanosdidnothingwrong -- banning people with python (https://clips.twitch.tv/AstutePluckyCocoaLitty)
175: PythonRobotics: Python sample codes for robotics algorithms (https://atsushisakai.github.io/PythonRobotics/)
23: Python and Flask Tutorial in VS Code (https://code.visualstudio.com/docs/python/tutorial-flask)
17: Started a new blog on Celery - what would you like to read about? (https://www.python-celery.com)
14: A Simple Anomaly Detection Algorithm in Python (https://medium.com/@mathmare_/pyng-a-simple-anomaly-detection-algorithm-2f355d7dc054)
DONE: python
1360: git bundle (https://dev.to/gabeguz/git-bundle-2l5o)
1191: Which hashing algorithm is best for uniqueness and speed? Ian Boyd's answer (top voted) is one of the best comments I've seen on Stackexchange. (https://softwareengineering.stackexchange.com/questions/49550/which-hashing-algorithm-is-best-for-uniqueness-and-speed)
430: ARM launches “Facts” campaign against RISC-V (https://riscv-basics.com/)
244: Choice of search engine on Android nuked by “Anonymous Coward” (2009) (https://android.googlesource.com/platform/packages/apps/GlobalSearch/+/592150ac00086400415afe936d96f04d3be3ba0c)
209: Exploiting freely accessible WhatsApp data or “Why does WhatsApp web know my phone’s battery level?” (https://medium.com/@juan_cortes/exploiting-freely-accessible-whatsapp-data-or-why-does-whatsapp-know-my-battery-level-ddac224041b4)
DONE: programming使用Redis和Redis Queue RQ
使用
asyncio和aiohttp并不总是一个好主意,尤其是在使用旧版本的Python时。另外,有时您需要在不同服务器之间分配任务。在这种情况下,可以使用RQ(Redis Queue)。这是一个通用的Python库,用于将作业添加到队列并由后台的工作人员对其进行处理。为了组织队列,使用Redis-键/值的数据库。
在下面的示例中,我们
count_words_at_url使用Redis 向队列添加了一个简单的函数。
from mymodule import count_words_at_url
from redis import Redis
from rq import Queue
q = Queue(connection=Redis())
job = q.enqueue(count_words_at_url, 'http://nvie.com')
******mymodule.py******
import requests
def count_words_at_url(url):
"""Just an example function that's called async."""
resp = requests.get(url)
print( len(resp.text.split()))
return( len(resp.text.split()))输出:
15:10:45 RQ worker 'rq:worker:EMPID18030.9865' started, version 0.11.0
15:10:45 *** Listening on default...
15:10:45 Cleaning registries for queue: default
15:10:50 default: mymodule.count_words_at_url('http://nvie.com') (a2b7451e-731f-4f31-9232-2b7e3549051f)
322
15:10:51 default: Job OK (a2b7451e-731f-4f31-9232-2b7e3549051f)
15:10:51 Result is kept for 500 seconds结论
例如,让我们参加一次国际象棋展览,其中最好的国际象棋棋手之一与众多人竞争。我们有24个游戏和24个您可以玩的人,并且如果国际象棋棋手与他们同步进行游戏,则至少需要12个小时(假设平均每局游戏需要30步,国际象棋棋手会思考5秒钟,然后对手-大约55秒。)但是,在异步模式下,国际象棋棋手将可以采取行动,让对手有时间思考,同时继续前进到下一个对手并分步进行。因此,您可以在2分钟内完成全部24场比赛的举动,而仅需一小时即可赢得全部胜利。
这就是他们说异步加速工作的意思。我们正在谈论这样的速度。优秀的棋手不会更快开始下棋,只是时间会更优化,而且不会浪费在等待上。这就是它的工作方式。
以此类推,下象棋者将是处理器,其主要思想是使处理器保持空闲状态的时间尽可能短。问题是他总是上课。
在实践中,异步被定义为一种并行编程方式,其中某些任务在等待期间释放处理器,以便其他任务可以利用它。Python有多种方法来实现并发以满足您的需求,代码流,数据处理,体系结构和用例,您可以从任何一种中进行选择。
.