
在第一部分中,我讨论了一般的模拟器以及建模级别。现在,基于此知识,我建议更深入地研究并讨论全平台仿真,如何组装轨道,以后如何处理它们以及逐周期微体系结构仿真。
完整的平台模拟器,或“实地不是战士”
如果您需要调查一个特定设备(例如网卡)的操作,或为此设备编写固件或驱动程序,则可以对此类设备进行单独建模。但是,与其他基础结构隔离使用它不是很方便。要运行相应的驱动程序,您需要中央处理器,内存,访问总线以进行数据传输等。另外,驱动程序需要操作系统(OS)和网络堆栈。此外,可能需要单独的数据包生成器和响应服务器。
全平台模拟器为启动完整的软件堆栈创建了一个环境,该环境包括从BIOS和引导加载程序到操作系统本身及其各个子系统的所有内容,例如相同的网络堆栈,驱动程序和用户级应用程序。为此,它实现了大多数计算机设备的软件模型:处理器和内存,磁盘,输入输出设备(键盘,鼠标,显示器)以及同一网卡。
下面是英特尔x58芯片组的框图。此芯片组上的全平台计算机模拟器需要实现大多数列出的设备,包括位于IOH(输入/输出集线器)和ICH(输入/输出控制器集线器)内部的设备,但未在框图中详细列出。尽管如实践所示,我们将要启动的软件中没有使用的设备很少。无法创建此类设备的模型。

最常见的是,全平台模拟器是在处理器指令级别上实现的(ISA,请参阅上一篇文章)。这使您可以相对快速,廉价地创建模拟器本身。ISA级别也很不错,因为它保持或多或少恒定,这与API / ABI级别不同,例如,API / ABI级别经常更改。另外,指令级的实现允许您运行所谓的未修改的二进制软件,即,运行已编译的代码而无需进行任何更改,就像在实际硬件上使用的一样。换句话说,您可以制作硬盘驱动器的副本(“转储”),将其指定为全平台模拟器中模型的图像,瞧!-OS和其他程序无需任何其他操作即可加载到模拟器中。
模拟器性能

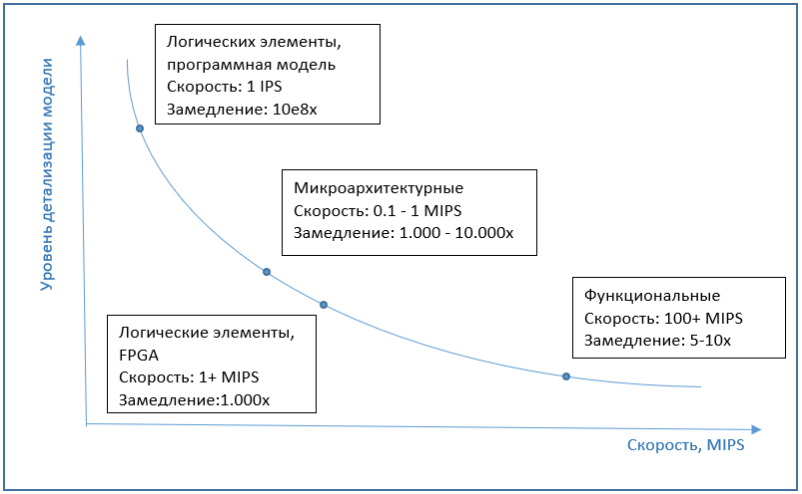
如前所述,模拟整个系统(即所有设备)的过程是相当快的事情。如果您还以非常详细的级别(例如,微体系结构或逻辑)来实现所有这些功能,则执行将变得非常缓慢。但是指令级别是一个合适的选择,它允许OS和程序以足以使用户舒适地与它们交互的速度运行。
在这里,仅需提及模拟器性能这一主题。通常以IPS(每秒指令)为单位,更精确地以MIPS(百万IPS)为单位,即,模拟器每秒执行的处理器指令数。同时,仿真速度还取决于运行仿真本身的系统的性能。因此,与原始系统相比,谈论模拟器的“减速”可能更正确。
市场上最常见的全平台模拟器,相同的QEMU,VirtualBox或VmWare工作站,都具有良好的性能。用户甚至不会注意到模拟器中的工作正在进行。这是由于处理器中实现了特殊的虚拟化功能,二进制转换算法和其他有趣的东西。这都是单独一篇文章的全部主题,但总而言之,虚拟化是现代处理器的硬件功能,如果模拟器和处理器的体系结构相似,那么模拟器就不必模拟指令,而是将指令直接发送给真实的处理器以执行。二进制翻译是将来宾计算机代码翻译为主机代码,然后在真实处理器上执行。结果是,仿真只会稍微慢一点,每5-10次一次,并且通常以与实际系统相同的速度运行。尽管这受很多因素影响。例如,如果我们要模拟一个具有数十个处理器的系统,那么速度将立即下降数十倍。另一方面,最新版本中的Simics之类的模拟器支持多处理器主机硬件,并将模拟内核有效地并行化为实际处理器内核。最新版本中的Simics等模拟器支持多处理器主机硬件,并有效地将模拟内核与实际处理器内核并行化。在最新版本中,诸如Simics之类的模拟器支持多处理器主机硬件,并有效地将模拟内核与实际处理器的内核并行化。
如果我们谈论微体系结构仿真的速度,那么它通常是几个数量级,大约是1000-10000倍,比没有仿真的常规计算机上的执行速度要慢。逻辑元素级别的实现甚至要慢几个数量级。因此,FPGA在此级别用作仿真器,可以显着提高性能。
下图显示了仿真速度对模型细节的近似依赖性。
逐周期仿真
尽管执行速度很慢,但微体系结构模拟器还是很普遍的。为了准确地模拟每个指令的执行时间,必须对处理器的内部模块进行模拟。此处可能会产生误解-毕竟,看来,为什么不仅仅为每条指令花费执行时间并对程序进行编程。但是,由于同一条指令的执行时间可能因调用而异,因此这样的模拟器会非常不准确。
最简单的示例是内存访问指令。如果请求的内存位置在高速缓存中可用,则执行时间将最少。如果高速缓存中没有此类信息(“高速缓存未命中”,高速缓存未命中),则这将大大增加指令的执行时间。因此,需要一个高速缓存模型来进行精确的仿真。但是,缓存模型不限于此。如果数据不在高速缓存中,则处理器将不只是等待数据从内存中接收。相反,它将开始执行下一条指令,选择不依赖于从内存读取结果的指令。这是最大限度地减少处理器停机时间所需的所谓的乱序执行(OOO)。在计算指令执行时间时,对相应处理器模块的仿真将有助于考虑所有这些因素。在这些正在执行的指令中,在等待从内存中读取结果时,可能会发生条件分支操作。如果此时满足条件的结果未知,则处理器不会再次停止执行,而是做出“假设”,执行相应的转换,并继续从转换位置抢先执行指令。这种称为分支预测器的块也必须在微体系结构模拟器中实现。
下图显示了处理器的主要模块,没有必要知道它,仅为了说明微体系结构实现的复杂性而给出。
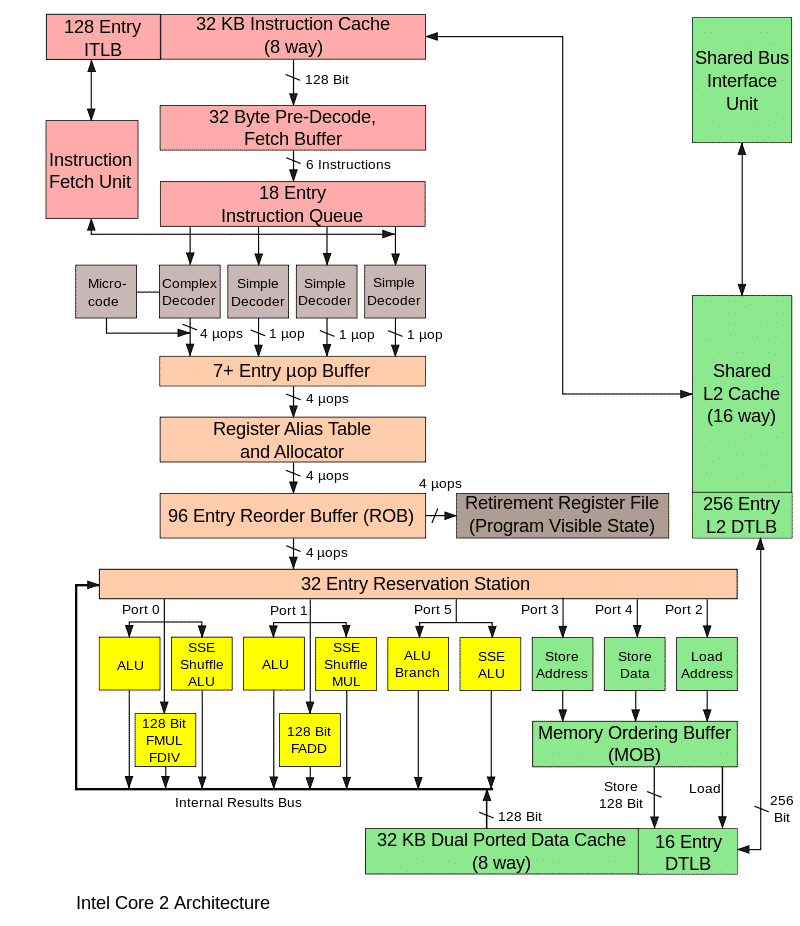
实际处理器中所有这些模块的操作都与特殊的时钟信号同步,并且在模型中也是如此。这种微体系结构模拟器称为周期精确。其主要目的是准确预测正在开发的处理器的性能和/或计算某个程序(例如某个基准)的执行时间。如果值低于必要值,则有必要完善算法和处理器块或优化程序。
如上所示,逐周期仿真非常慢,因此仅在检查程序操作的某些点时才使用它,在这种情况下,有必要找出程序执行的实际速度并估算其原型被仿真的设备的未来性能。
在这种情况下,将使用功能模拟器来模拟其余的程序运行时。这种组合使用实际上是如何发生的?首先,启动功能模拟器,在其上加载操作系统和运行所研究程序所需的一切。毕竟,我们对操作系统本身,启动程序的初始阶段,其配置等都不感兴趣。但是,我们也不能跳过这些部分而直接从中间执行程序。因此,所有这些初步步骤都在功能模拟器上运行。在执行完程序直到我们感兴趣的时刻,有两种选择。您可以逐周期替换模型并继续执行。模拟模式,其中使用可执行代码(即普通的编译程序文件),称为执行驱动的仿真。这是最常见的模拟选项。另一种方法也是可能的-跟踪驱动模拟。
基于轨道的模拟
它包括两个步骤。使用功能模拟器或在实际系统上,将收集程序操作日志并将其写入文件。这样的日志称为跟踪。根据所调查的内容,路由可能包括可执行指令,内存地址,端口号,有关中断的信息。
下一步是在逐周期模拟器读取跟踪并执行其中写入的所有指令时“播放”跟踪。最后,我们获得了给定程序的执行时间,以及该过程的各种特征,例如,高速缓存命中率。
使用轨道的一个重要特征是确定性,也就是说,通过如上所述开始仿真,我们一遍又一遍地再现相同的动作序列。通过更改模型的参数(高速缓存,缓冲区和队列的大小)并使用各种内部算法或对其进行调整,可以研究特定参数如何影响系统性能以及哪个选项可提供最佳结果。在创建真正的硬件原型之前,可以使用设备的原型模型完成所有这些操作。
这种方法的复杂性在于需要预先运行应用程序并收集跟踪,以及跟踪的巨大文件大小。优点包括仅模拟感兴趣的设备或平台的一部分就足够了,而执行模拟通常需要完整的模型。
因此,在本文中,我们研究了全平台仿真的功能,讨论了不同级别上的实现速度,拍子仿真和跟踪。在下一篇文章中,我将针对个人目的以及从大型公司的发展角度来描述使用模拟器的主要方案。