
-, , .
, , . – , , – .
, ,
前几篇文章(一,二,三)中列出的所有物理效应,不仅是为了了解世界的运转原理,对于理解也很重要。在建立知道如何正确预测未来的模型时,很可能必须考虑它们。如果仍然无法预测石油和冠状病毒的价格,为什么我们能够预测石油生产的未来?然后,为什么以及在哪里:做出正确的决定。

就油田而言,我们无法直接观察井之间地下发生的情况。我们几乎所有可用的东西都与井相关,也就是说,与广阔的沼泽中的稀有点有关(我们可以测量的一切都包含在约0.5%的岩石中,我们只能“猜测”其余99.5%的属性)。这些是建造井时在井上进行的测量。这些是安装在井中的仪器的读数(井底压力,输出中油水和天然气的比例)。这些是油井的测量参数和设定参数-何时开启,何时关闭,以什么速度泵送。
正确的模型是正确预测未来的模型。但是,由于未来还没有到来,我想了解模型现在是否良好,因此他们这样做:他们根据假设添加了对未知信息的猜测,将有关该领域的所有可用事实信息放入模型中(流行语“两位地质学家- “三个观点”(仅针对这些猜想),它们模拟了过滤过程,地下压力重新分布等过程。该模型给出了应该观察哪些油井性能指标,并将其与实际观察到的指标进行比较。换句话说,我们正在尝试建立一个再现故事的模型。
实际上,您可以作弊,只需要模型即可生成所需的数据。但是,首先,这无法完成,其次,他们仍然会注意到(需要提交模型的国家机构的专家)。
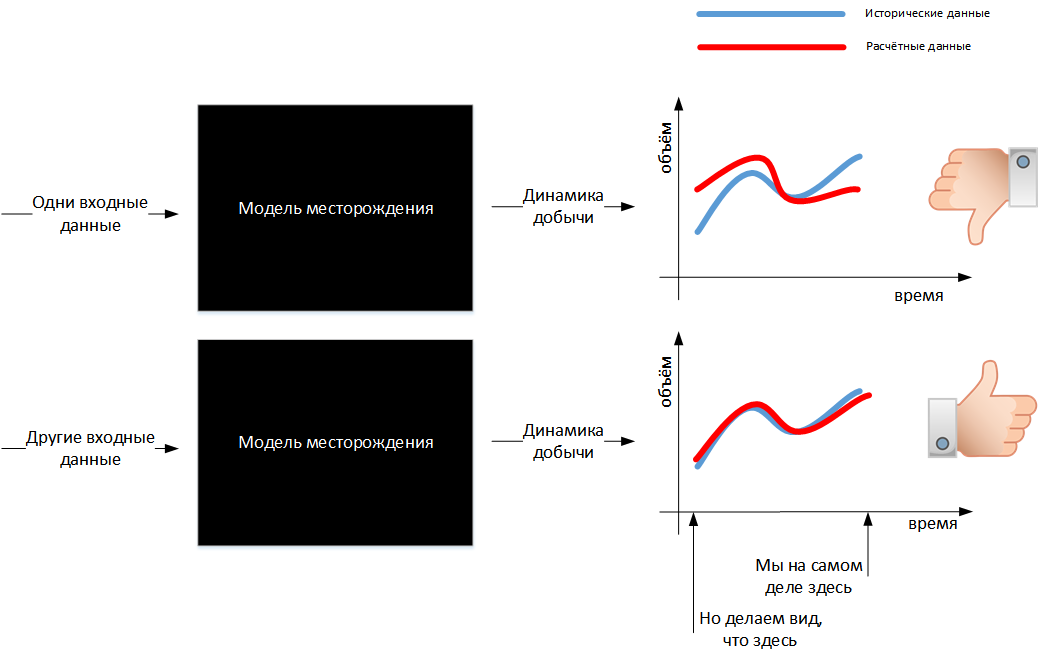
如果模型无法重现故事,则需要更改其输入,但是哪些输入需要更改?实际数据无法更改:这是观察和测量现实的结果-来自设备的数据。设备当然有其自身的错误,并且设备的使用者也可能会撒谎和撒谎,但是模型中实际数据的不确定性通常很小。有可能而且有必要改变不确定性最大的东西:我们对油井之间发生的情况的假设。从这个意义上讲,建立模型是为了减少我们对现实的不确定性(在数学上,此过程称为解决反问题,而在我们所在地区则称为反问题,例如北京的自行车!)。
如果模型足够正确地再现了故事,我们希望模型中嵌入的关于现实的知识与该现实本身没有太大区别。然后,只有到那时,我们才能为未来推出这样的预测模型,我们将有更多的理由相信这种预测。
如果您设法制作一个模型,而不是几个模型,这些模型都可以很好地重现历史,但同时又给出不同的预测,该怎么办?我们别无选择,只能忍受这种不确定性,铭记于心做出决定。此外,拥有多个模型给出了一系列可能的预测,我们可以尝试量化做出决策的风险,而拥有一个模型时,我们将毫无根据地相信所有事物都会如模型所预测的那样。
生活领域中的模型
为了在油田开发期间做出决策,需要整个油田的整体模型。而且,现在没有这种模型,根本不可能发展一个领域:俄罗斯联邦政府机构需要这种模型。

这一切都始于地震模型,该模型是由地震勘探的结果创建的。这样的模型使得有可能“看到”地下的三维表面-从中可以很好地反射地震波的特定层。它几乎没有提供有关我们需要的属性(孔隙度,渗透率,饱和度等)的信息,但它显示了某些层在空间中如何弯曲。如果您制作了一个多层三明治,然后以某种方式弯曲了它(好吧,或者有人坐在上面),那么您就有理由相信所有层都被弯曲得大致相同。因此,即使我们仅看到地震模型上的一层(幸运的是,它可以很好地反射地震波),也可以了解各种沉积物的层状蛋糕如何攻击海床弯曲。在这个地方,数据科学工程师复兴了,因为在立方体中自动选择了这样的反射层,这是我们其中一位参与者的黑客马拉松 -模式识别的经典任务。
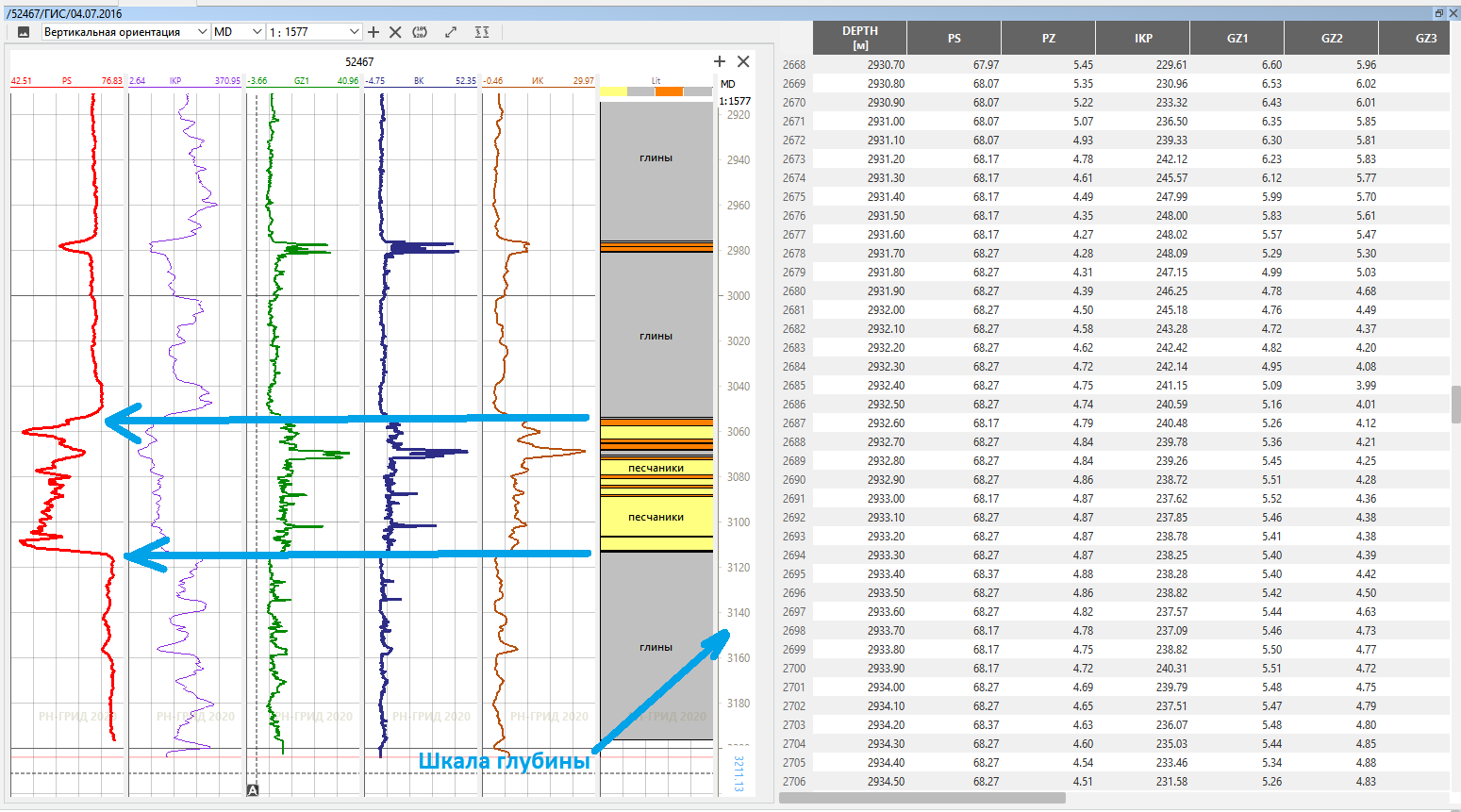
然后,开始探索性钻探,并在钻探井时,将仪器放下电缆以测量沿井眼的各种不同指标,即,它们执行GIS(井的地球物理勘测)。这项研究的结果是测井,即沿整个井眼以一定步长测量的一定物理量的曲线。不同的仪器测量不同的数量,然后由受过训练的工程师解释这些曲线以获得有意义的信息。一种仪器可测量岩石的自然伽马放射性。粘土“ fonit”更强,砂岩“ fonit”更弱-任何口译工程师都知道这一点,并在测井曲线上突出显示:这里有粘土,这里是一层砂岩,在两者之间。另一个设备测量相邻点之间的自然电势,由钻探泥浆渗透到地层中引起。工程师知道并确认了渗透岩的存在,高电位表明地层之间存在过滤连接。第三种仪器测量的是使岩石饱和的流体的阻力:盐水使电流通过,油不使电流通过,并且它可以使油饱和的岩石与水饱和的岩石等分离。
此时,数据科学工程师又恢复了活力,因为此问题的输入数据是简单的数字曲线,并用可以得出岩石性质结论的ML模型代替了解释器,而不是使用曲线形状的工程师意味着解决了经典分类问题。直到后来,数据科学工程师才开始抽动他们的眼睛,结果发现这些来自旧井的累积曲线中的一些只是长纸脚巾的形式。
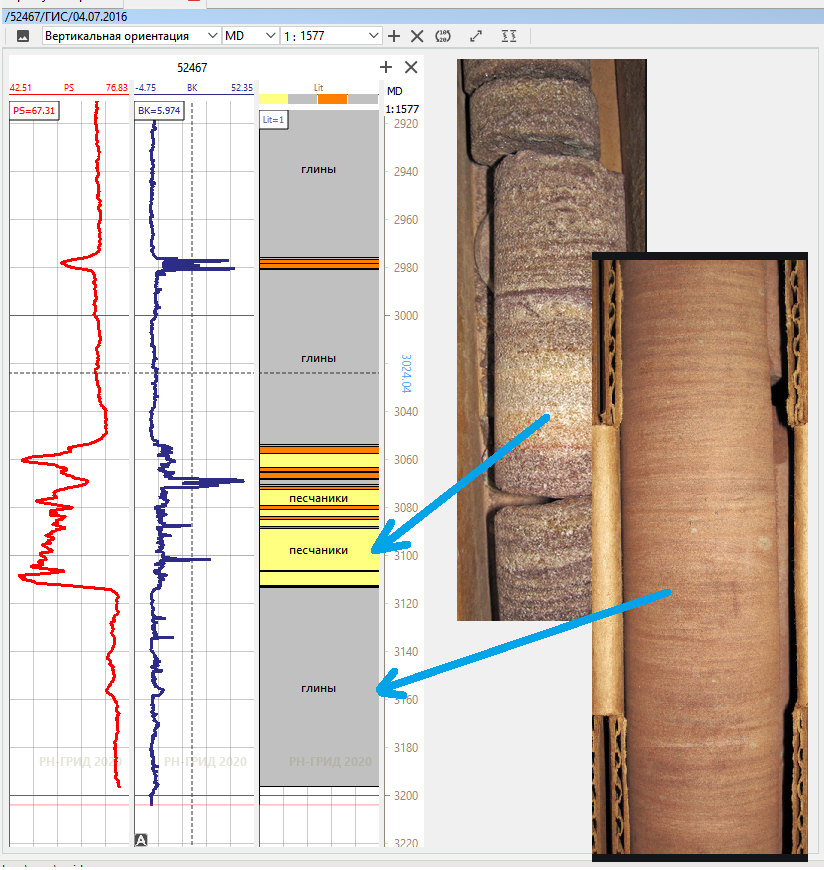
另外,在钻探期间,从井中取出岩心-钻探过程中或多或少完整(如果幸运的话)和完整岩石的样本。这些样品被送往实验室,在那里他们确定其孔隙率,渗透率,饱和度以及各种不同的机械性能。如果知道(并且正确地做到了)从特定岩心样品取了什么深度,那么当实验室的数据到达时,将有可能比较所有地球物理仪器在该深度显示的值以及孔隙度,渗透率和渗透率的值。根据实验室核心研究,饱和度使岩石达到了此深度。因此,有可能“瞄准”地球物理仪器的读数,然后仅从其数据中获取数据,而无需任何核心,即可得出我们需要建立模型的岩石特性的结论。整个魔鬼都在细节中:仪器无法准确测量实验室中确定的内容,但这是一个完全不同的故事。
因此,在钻了几口井并进行了研究之后,我们可以放心地断定在这些井中钻出的岩石是什么,具有什么性质。问题是,我们不知道井之间发生了什么。这就是地震模型为我们提供帮助的地方。

在井眼中,我们确切地知道岩石在什么深度具有什么性质,但是我们不知道在井眼处观察到的岩石层如何在它们之间传播和弯曲。地震模型不允许您准确确定哪个层位于哪个深度,但是可以自信地显示所有层的传播和弯曲性质,即地层性质。然后,工程师在井上标记某些特征点,并在一定深度处放置标记:在此井上此深度-地层顶部,在该深度-底部。粗略地说,井表面和井之间的底部的表面平行于地震模型中看到的表面绘制。结果是一组三维表面覆盖了我们感兴趣的空间,当然,我们对含油地层也很感兴趣。那发生的事情称为结构模型,因为它描述了地层的结构,而不是内部内容。结构模型没有说明地层内部的孔隙率和渗透率,饱和度和压力。
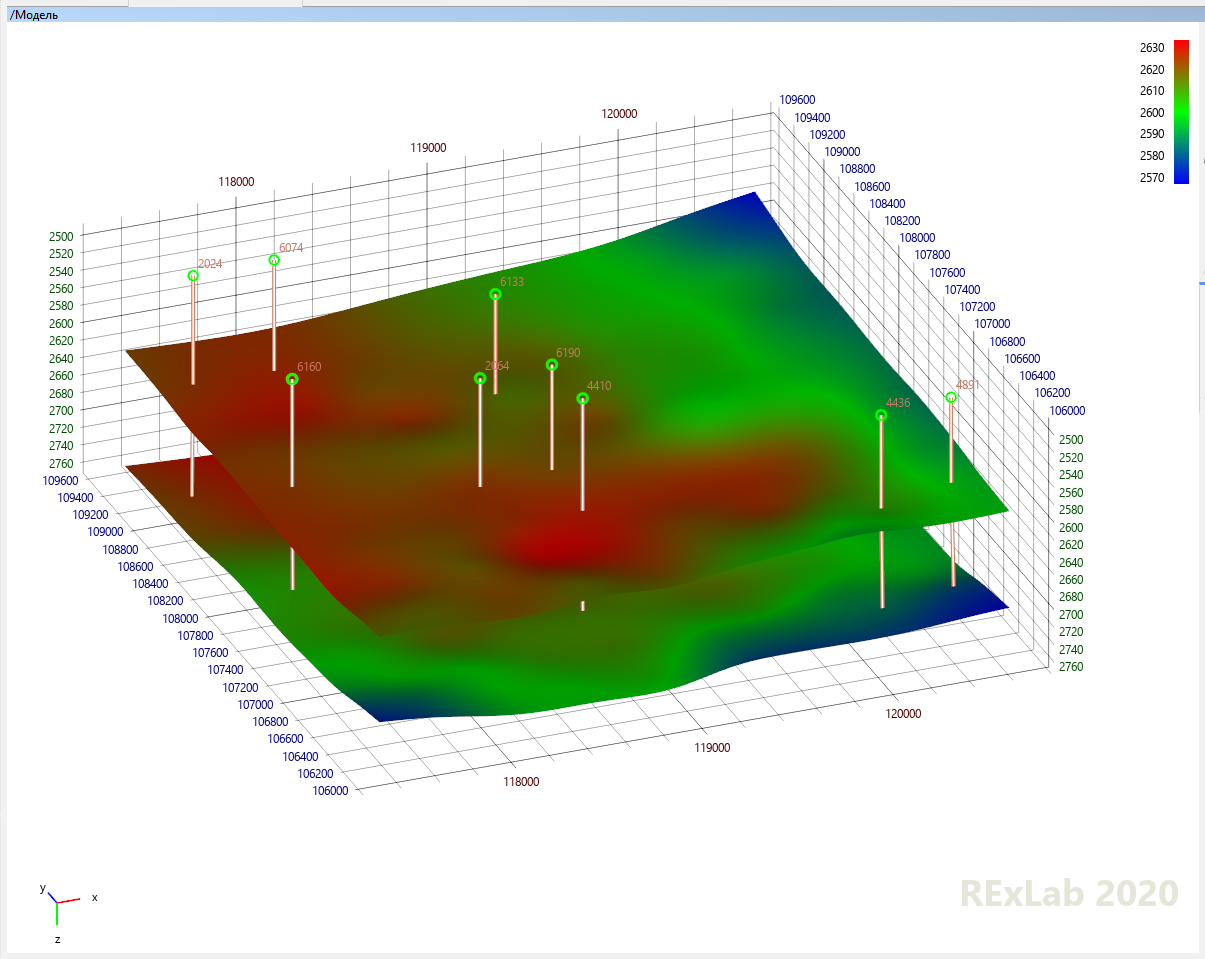
然后进入离散化阶段,在该阶段中,根据层理(在地震模型中仍然可以看到其特征!),将田地所占据的空间区域划分为由单元构成的弯曲平行六面体。弯曲的平行六面体的每个单元由三个数字I,J和K唯一标识。此弯曲的平行六面体的所有层均根据层的分布而定,并且K中的层数以及I和J中的单元数取决于我们能提供的细节。
我们沿井眼(即垂直方向)有多少详细的岩石信息?地球物理仪器在沿井眼移动时多久进行一次尺寸测量,即通常每20至40厘米测量一次,因此每层可以为40厘米或1 m。
我们的横向信息有多详细,即远离井眼?没有多少:我们在井边没有任何信息,因此沿I和J分成非常小的单元格通常毫无意义,并且最常见的是沿两个坐标分别为50或100 m。这些电池尺寸的选择是重要的工程挑战之一。
在将整个空间区域划分为单元格之后,可以进行预期的简化:在每个单元格内,将任何参数(孔隙度,渗透率,压力,饱和度等)的值都视为恒定。当然,实际情况并非如此,但是由于我们知道海底沉积物的沉积是分层的,因此岩石的特性在垂直方向上比水平方向上的变化要大得多。
因此,我们有一个单元格网格,每个单元格都有描述岩石及其饱和度的每个重要参数的自身值(我们不知道)。到目前为止,这个网格是空的,但是井在我们与设备一起通过的一些单元格中通过,并获得了地球物理参数曲线的值。口译工程师使用对岩心,相关性,经验等的实验室研究,将地球物理参数曲线的值转换为我们所需的岩石和饱和流体的特性值,并将这些值从井转移到该井通过的网格单元中。结果是在某些地方网格中的单元格中有值,但在大多数单元格中仍然没有值。所有其他像元中的值都必须使用内插法和外推法来想象。地质学家的经验,他的知识由于岩石的属性通常是分布的,因此您可以选择正确的插值算法并正确填写参数。但是无论如何,您都必须记住,所有这些都是对井间未知物的猜测,他们说的不是什么都不是,再次提醒大家一个常识,我要提醒您,两个地质学家对同一矿床会有三种不同的见解。
这项工作的结果将是一个地质模型-一个三维弯曲的平行六面体,分为多个单元格,描述了场的结构以及这些单元格中的多个三维属性阵列:最常见的是孔隙度,渗透率,饱和度和属性``砂岩''-``粘土''的阵列。
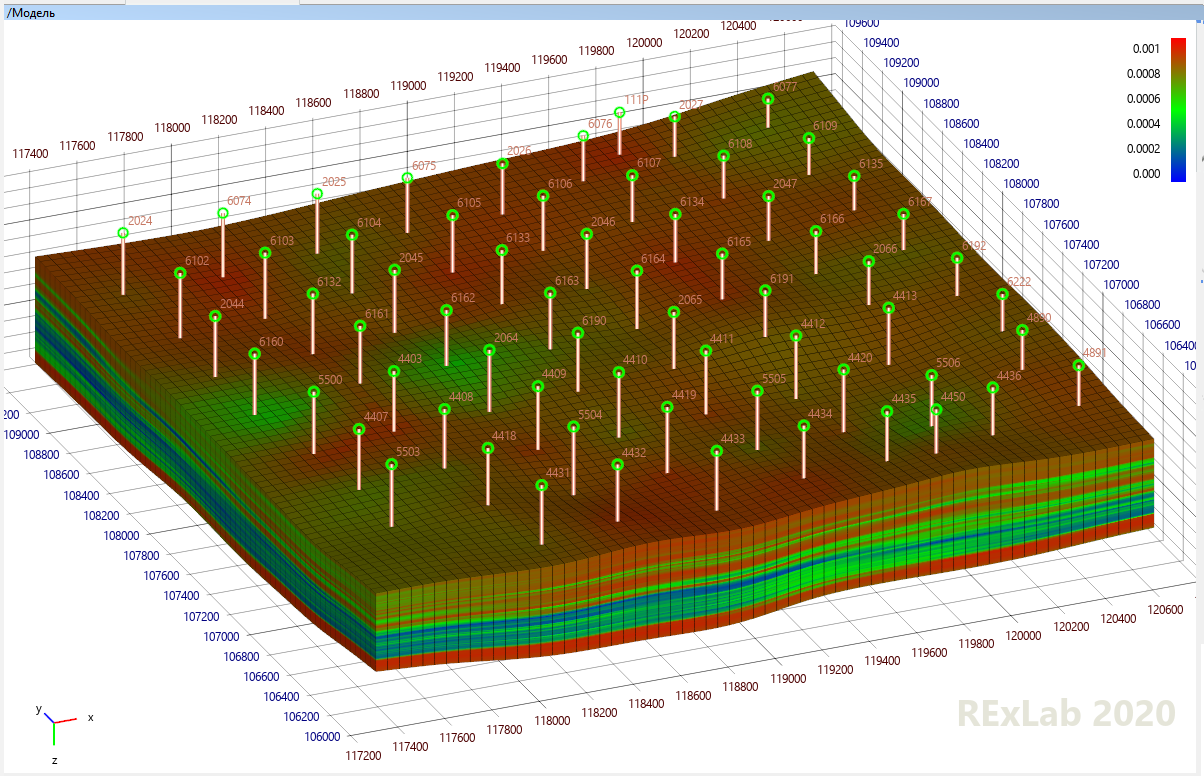
然后,水动力专家接手。他们可以通过垂直组合多个层并重新计算岩石属性来扩大地质模型(这称为“放大”,这是一个单独的挑战)。然后,它们添加了其余必要的属性,以便流体动力学模拟器可以模拟在何处流动:除了孔隙度,渗透率,油,水,气体饱和度外,还包括压力,气体含量等。他们将向模型添加井,并在其上输入有关何时以及以何种模式工作的信息。您没有忘记我们正在尝试重现故事,以便对正确的预测抱有希望吗?流体力学将从实验室获得报告,并在模型中添加石油,水,天然气和岩石的物理化学特性,它们的所有依存关系(通常是压力)以及发生的所有事情(将是水动力模型)将被发送到水动力模拟器。他将诚实地计算出什么时间点什么物质将从哪个单元流入哪个位置,给出每个井的技术指标图,并将其与真实历史数据进行认真地比较。流体力学工程师会叹气,看他们的差异,然后去更改他试图猜测的所有未定义的参数,以便下次启动模拟器时,他将获得与实际观察到的数据接近的信息。或者,也许在下一个开始。或者下一个,依此类推。它将生成每个井的技术指标图,并将其与真实历史数据进行仔细比较。流体力学工程师会叹气,看他们的差异,然后去更改他试图猜测的所有未定义的参数,以便下次启动模拟器时,他将获得与实际观察到的数据接近的信息。或者,也许在下一个开始。或者下一个,依此类推。将发布每口井的技术指标图,并将其与真实历史数据进行仔细比较。流体力学工程师会叹气,看他们的差异,然后去更改他试图猜测的所有未定义的参数,以便下次启动模拟器时,他将获得与实际观察到的数据接近的信息。或者,也许在下一个开始。或者下一个,依此类推。
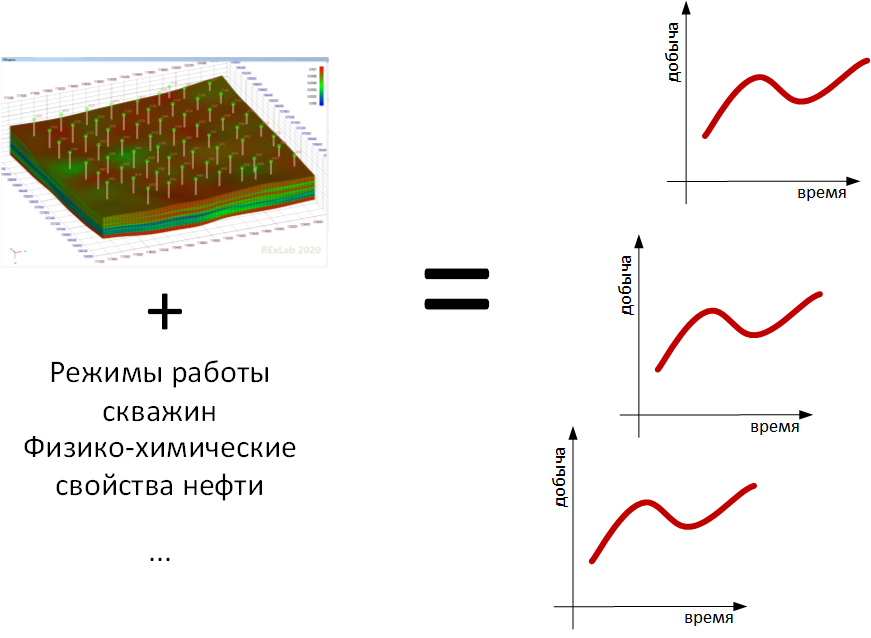
准备地面基础设施模型的工程师将根据建模结果将油田产生的流量纳入模型,从而计算出哪个管道将承受何种压力,以及现有的管道系统是否能够“消化”该油田的产出:清洗产出的天然气。油,准备所需量的注入水等。
最后,在最高层次上,在经济模型的层次上,经济学家将计算油井的建设和维护费用流,泵和管道运行所需的电力以及从输油到管道系统的收入流,再乘以所需的折现系数度,即可得出总净现值来自完成的现场开发项目。
当然,所有这些模型的准备都需要积极地使用数据库来存储信息,使用专门的工程软件来实现对所有输入信息的处理以及实际的建模,即预测过去的未来。
为了构建以上每个模型,使用单独的软件产品,通常是资产阶级,实际上没有争议,因此非常昂贵。这样的产品已经发展了几十年,在一个小型机构的帮助下重复其发展之路并非易事。但是恐龙不是被其他恐龙吃掉的,而是被小的,饥饿的,有目的的雪貂吃掉的。重要的是,就像在Excel中一样,日常工作仅需要10%的功能,而我们的工作,例如Strugatskys,将“只能做到……-但是能做到这一点的人”只是这10%。总的来说,我们充满希望,我们已经有了某些理由。
本文仅描述了整个领域模型生命周期的支柱路径,并且已经有软件开发人员可以漫游的地方,并且使用当前的定价模型,竞争对手将可以长期工作。在下一篇文章中,将衍生出
未完待续…