我曾经是团队负责人,负责一些批评家服务。如果他们出了什么问题,它就会停止实际的业务流程。例如,订单停止在仓库进行组装。
我最近成为领导者,现在负责三支团队,而不是一支。他们每个人都运行一个IT系统。我想了解每个系统中正在发生的事情以及可能会崩溃的事情。
在本文中,我将讨论
- 我们监控的是
- 当我们监控
- 最重要的是,我们如何处理这些观察结果。

Lamoda有许多系统。他们都被释放了,其中正在发生变化,技术正在发生变化。而且我至少希望有一种幻想,即我们可以轻松定位故障。我不断被试图找出的警报轰炸。为了避开抽象并讲究细节,我将告诉您第一个示例。
时不时发生爆炸:大事记
在一个温暖的夏天早晨,没有像通常那样发生战争宣战的情况,我们的监视工作奏效了。我们使用Icinga作为警报。 Alert说,DBMS服务器上还有50 GB的硬盘驱动器。最有可能的是,50 GB的存储桶中有钱,而且很快就会结束。我们决定确切地看到剩余了多少可用空间。您需要了解,这些不是虚拟机,而是铁服务器,并且数据库负载沉重。有一个1.5 TB的SSD。很快,这种记忆将很快结束:它将持续20到30天。这很小;您需要快速解决问题。
然后,我们还检查了1-2天实际消耗了多少内存。事实证明,50 GB的存储空间足以存储大约5-7天的时间。之后,可以预料的是,与此数据库一起使用的服务将结束。我们开始考虑后果:我们将紧急存档什么,删除哪些数据。数据分析部门拥有所有备份,因此您可以放心删除所有早于2015年的内容。
我们尝试将其删除,并记住MySQL不能半按那样工作。删除的数据非常棒,但是分配给表和DB的文件大小不会改变。然后,MySQL使用此空间。也就是说,问题没有解决,没有更多空间了。
尝试不同的方法:将标签从快到期的SSD迁移到速度较慢的SSD。为此,我们选择重量很大但负载很小的板,并使用Percona监测。我们已经移动了表格,并且已经在考虑移动服务器本身。第二步之后,服务器占用的空间不是4 TB,而是4 TB。
我们扑灭了这场大火:组织了一次行动,当然还进行了固定监控。现在,警告将不是在50 GB上触发,而是在0.5 TB上触发,并且临界监视值将在50 GB上触发。但实际上,这只是后方后方的毯子。它会持续一段时间。但是,如果我们允许情况重复发生而又没有将基础分解成几部分并且不考虑分片,那么一切都会以糟糕的结果结束。
假设我们进一步更改了服务器。在某个阶段,需要重新启动主服务器。在这种情况下,可能会出现错误。在我们的情况下,停机时间约为30秒。但是请求即将到来,无处可写,错误泛滥,监视得以实现。我们使用Prometheus监视系统-从中可以看到,创建订单时出现500个错误或错误数量的指标跳了起来。但是我们不知道细节:没有创建什么样的订单,依此类推。
此外,我将告诉您如何与监视一起工作,以免陷入这种情况。
审查监控并明确说明支持服务
我们有几个要监视的方向和指标。办公室中到处都有电视,在电视上有许多不同的技术和商业标签,除开发商外,还受支持服务的监视。
在本文中,我将讨论我们如何拥有它并添加我们想要得到的东西。这也适用于监视评论。如果我们定期清点我们的“财产”,那么我们可以更新和修复所有过时的东西,从而避免重复fakap。为此,您需要一个明确的清单。
我们在存储库中有带有警报的配置,现在有4678行。从该列表中,很难理解每个特定监视所指的是什么。假设我们的指标称为db_disc_space_left。支持服务不会立即了解其含义。关于自由空间的东西,很棒。
我们想更深入地挖掘。我们查看此监视的配置,并了解其来源。
pm_host: "{{ prometheus_server }}"
pm_query: ”mysql_ssd_space_left"
pm_warning: 50
pm_critical: 10 pm_nanok: 1
该指标具有名称,其自身的局限性,何时包括警告监视,报告紧急情况的警报。我们使用度量标准命名约定。每个指标的开头是系统的名称。由于这一点,责任领域变得清晰起来。如果系统负责人启动该度量标准,则可以立即清楚找到谁。
警报被灌入电报或闲暇中。支持服务是第一个24/7响应他们的人。伙计们正在看什么特别爆炸,这是正常情况。他们有指示:
- 那些要替换的
- 和持续融合在一起的固定说明。通过爆炸监控的名称,您可以找到它的含义。最关键的是,它描述了失败的原因,后果以及需要提出的人。
在负责关键系统的团队中,我们也有轮班制。每个团队都有一个随时待命的人。如果发生了什么,他们会捡起来。
触发警报后,支持团队需要快速找出所有关键信息。在错误消息中附加指向监视描述的链接会很好。例如,有这样的信息:
- 以可理解的相对简单的术语描述此监视;
- 地址位于;
- 度量标准的解释;
- 结果:如果我们不纠正错误,它将如何结束;
- , , . , , . -, .
立即在Prometheus界面中查看流量动态也很方便。
我想对每个监视进行这样的描述。他们将帮助您进行审核并进行调整。我们正在介绍这种做法:在结冰配置中已经存在与该信息融合的链接。我在一个系统上工作了将近4年,基本上没有关于它的描述。因此,现在我正在一起收集知识。说明还解决了团队无知的问题。
对于大多数警报,我们都有说明,在其中写明会导致一定的业务影响。这就是为什么我们必须迅速解决这种情况。可能发生的事件的严重性由支持服务与企业共同确定。
我将举一个例子:如果触发了对订单处理服务的RabbitMQ服务器上的内存消耗的监视,这意味着队列服务可能在几小时甚至几分钟内崩溃。反过来,这将停止许多业务流程。结果,客户将无法成功等待订单,SMS /推送通知,状态更改等。
发生严重事件后,通常会进行与业务监视有关的讨论。如果发生故障,我们将收取代表方向的佣金,该佣金与我们的释放或事件挂钩。在会议上,我们分析了事件的原因,如何确保事件不再发生,我们遭受了什么损失,损失了多少钱以及损失了什么。
碰巧您需要建立业务联系以解决为客户带来的问题。在这里,我们讨论积极的行动:开始哪种监视,这样就不会再次发生。
支持服务使用电报机器人监视指标的值。当出现新的监视时,支持人员需要一个简单的工具来找出故障所在以及如何处理。警报中描述的链接可解决此问题。
我认为事实是事实:使用Sentry进行汇报
仅查找错误,还需要查看详细信息,这还不够。我们的标准用例如下:推出版本,并从K8S堆栈接收警报。多亏了监视,我们才能查看Pod的状态:推出了哪个版本的应用程序,部署如何结束,一切都很好。
然后,我们看一下RMM,它具有底座和负载。对于Grafana和木板,我们看一下与Rabbit的连接数。他很酷,但是知道内存耗尽时如何泄漏。我们监视这些东西,然后检查哨兵。它使您可以在线观看下一次惨败如何发生的所有细节。在这种情况下,发布后的监视将报告发生了什么以及如何发生。
在PHP项目中,我们使用了乌鸦客户端,此外还丰富了数据。哨兵很好地汇总了所有内容。而且,我们可以看到每个fakap的动态情况,发生的频率。此外,我们还将查看示例,哪些请求失败,哪些请求失败。
看起来像这样。我看到在下一发行版中,错误比平时更多。我们将检查具体损坏的内容。然后,如有必要,我们将在上下文中获取失败的订单并进行修复。
我们有一个很酷的东西-绑定到Jira。这是一个票务跟踪器:我按下了一个按钮,Jira创建了一个错误任务,其中包含指向Sentry的链接以及该错误的堆栈跟踪。该任务带有某些标签。
其中一位开发人员提出了一项明智的建议-“清洁项目,清洁哨兵”。在计划过程中,每次我们将至少1-2个由Sentry创建的任务放入sprint中。如果系统中始终有故障,则Sentry会被数百万个小傻虫淹没。我们会定期清洁它们,以免意外遗漏真正严重的灰尘。
出于任何原因大发雷霆:我们摆脱了监视,每个人都在此阻塞
- 习惯错误
如果某物不断闪烁并看上去很破损,则会给人以错误规范的感觉。可以使服务台误以为情况适当。当严重的故障发生时,它将被忽略。就像一个关于一个男孩大喊的寓言:“狼,狼!”
经典案例是我们的项目,该项目负责订单处理。它与仓库自动化系统配合使用并在那里传输数据。该系统通常在早上7点发布,此后监控闪烁。每个人都习惯它并堵塞,这不是很好。关闭这些控件是明智的。例如,要通过Prometheus链接特定系统的发布和某些警报,只需不要打开不必要的信号即可。
- 监视不考虑业务指标
订单处理系统将数据传输到仓库。我们已将监视器添加到该系统。他们都没有开除,看来一切都很好。计数器指示数据正在离开。这种情况下使用肥皂。实际上,计数器可能看起来像这样:绿色部分是传入的交换,黄色部分是传出的交换。
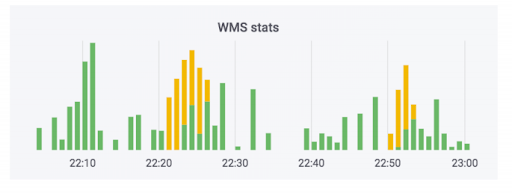
我们曾有一个案例,数据确实令人满意,但曲线。订单未付款,但被标记为已付款。也就是说,买家将能够免费取货。这似乎很可怕。但是相反的做法更有趣:一个人来接一个已付款的订单,由于系统错误,他被要求再次付款。
为了避免这种情况,我们不仅监视技术,还监视业务指标。我们有一个特定的监视程序,该命令监视需要在收货时付款的订单数量。如果出现问题,此指标的任何重大飞跃都会显示出来。
监视业务指标是显而易见的事情,但是当包括我们在内的新服务发布时,它们常常被人们遗忘。每个人都使用与磁盘,进程等相关的纯粹技术指标来涵盖新服务。作为在线商店,我们有一个关键问题-创建的订单数量。我们知道人们通常会购买多少,并根据营销促销进行调整。因此,我们在发布期间监视该指标。
另一重要的事情是:当客户反复下订单将送货到同一地址时,我们不会通过与呼叫中心的沟通来折磨他,而是会自动确认订单。系统崩溃对客户体验有巨大影响。我们还会监视此指标,因为不同系统的发布会强烈影响它。
我们正在观察现实世界:我们关心健康的冲刺和表现
为了使业务跟踪不同的指标,我们写下了一个小型的实时仪表板系统。最初,这样做是出于不同的目的。该公司有一个计划,要在下个月的特定日期我们要卖出多少订单。该系统显示了计划的执行情况,并且是事实。对于图表,她从生产数据库中获取数据,并从那里实时读取数据。
一旦我们的副本崩溃了。没有监视,因此我们没有时间去了解它。但是该业务部门发现我们没有实现10个常规订单单位的计划,因此发表了评论。我们开始了解原因。原来,不相关的数据是从损坏的副本中读取的。在这种情况下,企业会观察到有趣的指标,并且在出现问题时我们会互相帮助。
我将告诉您有关现实世界的另一种监视,这种监视已经开发了很长时间,并且每个团队都在不断对其进行调整。我们有一个Jira Viewer-它使您可以监视开发过程。该系统非常简单:PHP框架Symfony,它连接到Jira Api并从那里获取有关任务,冲刺等数据,具体取决于输入的内容。Jira Viewer定期向Prometeus编写与团队及其项目有关的度量标准。在那里,它们受到监视,警报,并从那里显示在Grafana中。借助此系统,我们可以跟踪正在进行的工作。
- 我们监视从完成任务到将产品投入生产的整个过程。如果数量太大,从理论上讲,这表明流程,团队,任务描述等存在问题。任务的寿命是一个重要的指标,但其本身还不够。
- . , , . , .
- – ready for release, . - - , « ».
- : , . .
- . 400 150. , , .
- 我在团队中监控了在工作时间以外来自开发人员的拉取请求的数量。特别是晚上8点以后。当度量标准出炉时,这是一个令人震惊的信号:一个人没有时间做某事,或者投入过多的精力,迟早会变得筋疲力尽。
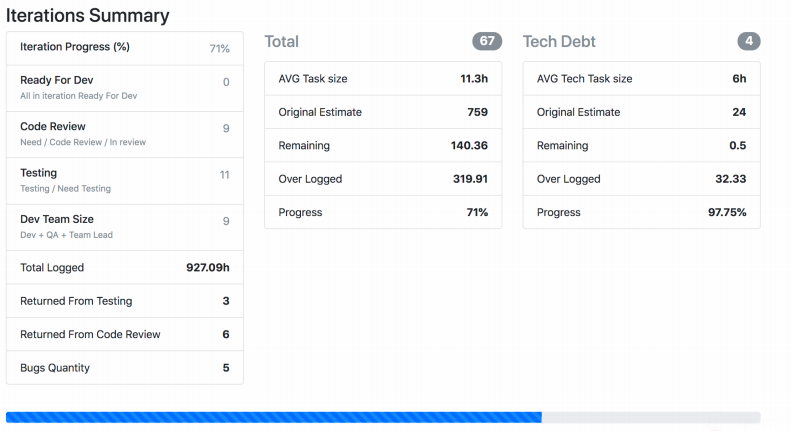
屏幕快照显示了Jira Viewer如何输出数据。这是一个页面,其中包含有关冲刺任务状态,每个任务的权重等的摘要信息。这些东西也聚集起来并飞往普罗米修斯。
不仅是技术指标:我们已经监控的内容,我们可以监控的内容以及为什么需要所有这些
综上所述,我建议同时监视与流程,开发和业务相关的技术和指标。仅技术指标是不够的。
- , -, Grafana-. . , , .
- : , . , , crontab supervisor. . , , .
- – , , .
- : , - , . , .
- , . – Sentry . - , . - , . Sentry , , .
- . , , .
- , . , - , - . .