
回顾过去,我可以说此后的所有安置活动都是强制性的。直到现在,在第十五年,我们都可以根据需要配置基础结构。
现在,我们站在4个物理上不同的数据中心中,这些数据中心由一圈黑暗的光学系统相连,并在那里放置5个独立的资源池。碰巧的是,如果一颗陨石撞到了十字架上的一个,那么其中三个池将立即掉落,其余两个池不会拉负载。因此,我们进行了完全的重新平衡以恢复订单。
第一数据中心
最初没有数据中心。莫斯科国立大学的宿舍里有一位老系统主义者。然后,几乎立即-来自Masterhost的虚拟主机(魔鬼还活着)。带有火车时刻表的网站流量每4周翻一番,因此很快我们切换到了KVM-VPS,它发生在2005年左右。在某些时候,我们遇到了流量限制,因为那时有必要在传入和传出之间保持平衡。我们有两个装置,并且每晚将几个重文件从一个移到另一个,以保持所需的比例。
在2009年3月,只有VPS。这是一件好事,我们决定切换到主机托管。我们购买了几个物理铁服务器(其中一个是壁式服务器,我们将其存储为内存)。他们将Fiord放到了数据中心(他们还活着,很小的恶魔)。为什么?因为离当时的办公室不远,所以一位朋友推荐了,我不得不迅速起床。加上它相对便宜。
在服务器之间共享负载很简单:每个服务器都有一个后端,MySQL具有主从复制功能,前端与副本位于同一位置。好吧几乎没有按负载类型划分。他们很快也开始想念,买了三分之一。
在2009年10月1日左右,我们意识到已经有更多的服务器,但是我们将在新的一年里停产。流量预测显示,可能的容量将与边际重叠。并且我们遇到了数据库的性能。在流量增长之前需要准备一个半月。这是第一次优化的时候。我们仅在数据库下购买了几台服务器。他们专注于转速为15krpm的快速磁盘(我不记得我们为什么不使用SSD的确切原因,但是很可能它们的写入次数限制很低,同时它们的成本也像飞机一样)。我们划分了前端,后端和数据库,对nginx,MySQL设置进行了调整,并进行了后方切除以优化SQL查询。幸存下来。

现在,我们处于一对Tier-III数据中心中,并且处于UI的Tier-II中(在T3处摇摆,但没有证书)。但是Fiord甚至从来都不是T-II。他们的生存能力有问题,有些情况是“所有电源线都在一个收集器中,有火,发电机运转了三个小时”。总的来说,我们决定搬家。
选择另一个数据中心,商队。挑战:如何在不停机的情况下移动服务器?我们决定在两个数据中心中住一段时间。幸运的是,当时系统内部的流量并不像现在那么多,有可能在一段时间之间(尤其是过时)通过位置之间的VPN驱动流量。流量均衡。完全搬到那里后,逐渐增加了商队的份额。现在我们剩下一个数据中心了。由于Fiord的失败,我们需要两个,我们已经了解了这一点。回顾当时,我可以说TIER III也不是万能药,生存能力将是99.95,但可访问性是另一个。因此,一个数据中心的99.95及更高可用性绝对是不够的。Stordata被
选为第二,并且已经有可能与Caravan网站建立光学链接。我们设法伸展了第一条静脉。随着Caravan宣布他们拥有资产,刚刚开始加载新的数据中心。他们不得不离开现场,因为建筑物正在被拆除。已经。惊喜!有一个新站点,他们提议熄灭一切,用起重机用设备抬起机架(那时我们已经有2.5个铁架子),平移,打开它,一切都会正常工作……4个小时的一切……童话故事……我已经沉默了,我们甚至有一个小时的停机时间不合适,但故事在这里至少会拖延一天。所有这些都本着“一切都消失了,除去了灰泥,客户离开了!”的精神来服务。在9月29日,即第一个电话会议上,以及10月10日,他们想拿走一切。在3-5天的时间里,我们不得不制定移动计划,分3个阶段,一次关闭1/3的设备,同时完全保留服务和正常运行时间,以将汽车运输到Stordata。结果,在一项不是最关键的服务中,停机时间为15分钟。
所以我们又剩下一个数据中心了。
此时此刻,我们已经厌倦了在服务器下闲逛并玩装载机。再加上在数据中心处理硬件本身的烦恼。他们开始看向公共云。
从2到5个(几乎)数据中心
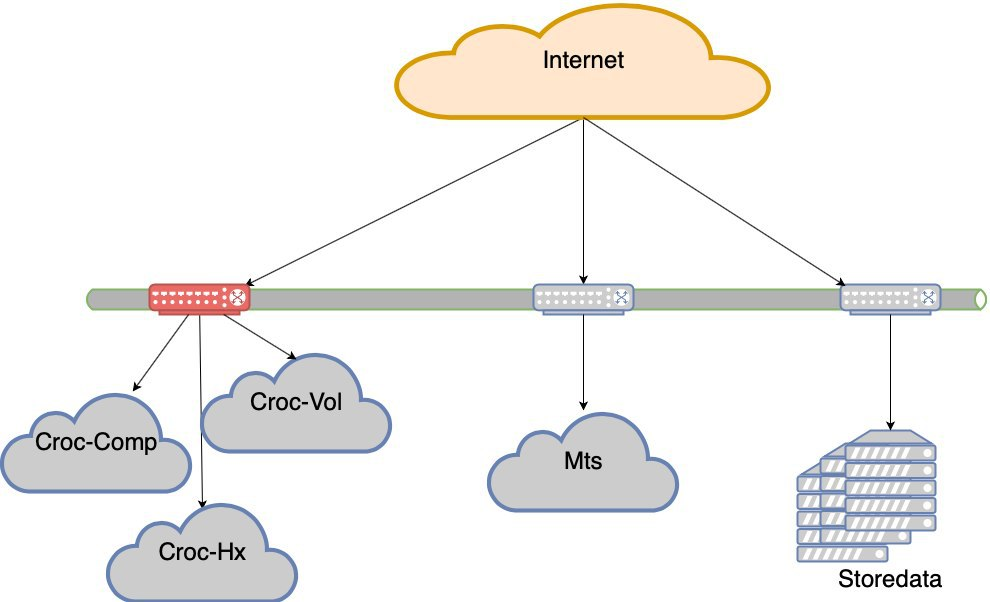
开始寻找带有云的选项。我们去了Krok,尝试了一下,测试了一下,并同意了条款。我们进入了Compressor数据中心中的云。他们在Stordata,Compressor和办公室之间制造了一圈黑暗的光学系统。到处都有自己的上行链路和两个光学臂。切断任何光线不会破坏网络。上行链路的丢失不会破坏网络。拥有LIR状态,拥有自己的子网,BGP公告,网络冗余,美观。我不会从网络的角度描述它们如何进入云计算,但是会有细微差别。
因此,我们有2个数据中心。
Krok在Volochaevskaya上也有一个数据中心,他们在那里扩展了云,并愿意在那儿转移我们的部分资源。但是我想起了大篷车的故事,事实上,在拆除数据中心后它从未恢复过,我想从不同的提供商那里获取云资源,以减少该公司将不复存在的风险(这个国家使得这种风险不容忽视)。因此,当时没有联系Volochaevskaya。好吧,第二个供应商也对价格具有魔力。因为当您可以灵活取货时,它可以为您提供强大的议价能力。
我们研究了不同的选择,但是选择落在#CloudMTS上。造成这种情况的原因有很多:在测试中,云被证明是不错的,这些家伙还知道如何与网络(毕竟是电信运营商)合作,并且制定了非常激进的营销策略来占领市场,因此价格很有趣。
共有3个数据中心。
之后,我们也连接了Volochaevskaya-我们需要其他资源,但是Compressor已经有点局促了。通常,我们在Stordat中的三朵云和我们的设备之间重新分配负载。
4个数据中心。就生存能力而言,T3无处不在。似乎并非每个人都有证书,但我不确定。
MTS有细微差别。 MGTS只能走到最后一英里。同时,不可能将MGTS的深色光学器件完全从数据中心拉到数据中心(很长很长时间,如果我不混淆,它们不会提供这种服务)。我必须做一个关节,将两束光束从数据中心输出到最近的井,那里是我们的深色光学器件供应商Mastertel。他们在整个城市拥有广泛的光学网络,如果有的话,它们就可以焊接所需的路线,并为您提供便利。与此同时,FIFA世界杯出人意料地来到了这座城市,就像冬天的雪一样,莫斯科的水井也被关闭。我们在等待这个奇迹的结束,我们可以扔掉我们的联系。似乎有必要将MTS数据中心放在手边,吹口哨以到达所需的舱口并将其放下。有条件的。我们做了三个半月。更准确地说,第一束射线很快就形成了,到八月初(让我提醒您,世界杯于7月15日结束)。但是我不得不调整第二个肩膀-第一个选项意味着有必要挖开Kashirskoe高速公路,为此它被封锁了一个星期(在重建过程中,一些隧道被封锁了,通讯所在,有必要将其挖出)。幸运的是,他们找到了另一种选择:另一条路线,与地理位置无关。事实证明,从这个数据中心到我们存在的不同点有两个方面。光学环已变成带手柄的环。事实证明,从这个数据中心到我们存在的不同点有两个方面。光学环已变成带手柄的环。事实证明,从这个数据中心到我们存在的不同点有两个方面。光学环已变成带手柄的环。
展望未来,我会说他们还是把它交给了我们。幸运的是,在开始运行时,没有转移太多。一口井着火了,安装人员在泡沫中发誓,而第二口井中有人拔出接头看(我想知道这是一种新设计)。从数学上讲,同时发生故障的可能性可以忽略不计。实际上,我们抓到了他。实际上,在峡湾地区,我们很幸运-在那儿切断了主电源,而没有重新打开电源,而是有人混淆了开关并关闭了备用线路。
不仅在分配位置之间的负载方面存在技术要求:没有奇迹,而且价格合理的激进营销政策意味着资源消耗的一定增长率。因此,我们始终牢记必须将多少百分比的资源发送到MTS。我们在其他数据中心之间或多或少平均分配的所有其他内容。
再次你的铁
使用公共云的经验向我们表明,当您需要快速添加资源,进行实验,进行试验等时,使用公共云非常方便。当在恒定负载下使用时,它比扭曲自己的烙铁更昂贵。但是我们不能再放弃容器,集群内虚拟机的无缝迁移等想法了。我们编写了自动化程序以在夜间熄灭某些汽车,但经济仍然无法解决。我们没有足够的能力来支持私有云,因此我们不得不对其进行扩展。
我们正在寻找一种解决方案,以使您可以相对轻松地在硬件上安装云。当时,我们从未与Cisco服务器合作,而仅与网络堆栈合作,这是一个风险。德拉拥有简单,熟悉的硬件,与卡拉什尼科夫突击步枪一样可靠。我们已经有很多年了,但仍然有一个地方。但是Hyperflex背后的想法是,它支持开箱即用的最终解决方案的超融合。在Della,一切都生活在普通路由器上,并且有细微差别。特别是,由于开销,性能实际上不如演示文稿中那样酷。我的意思是,它们可以正确设置,而且效果很好,但是我们认为这不是我们的事,请让Dell为那些发现这项职业的人做好准备。结果,我们选择了Cisco Hyperflex。总的来说,此选项是最有趣的:设置和操作中的痔疮更少,测试期间一切都很好。在2019年夏天,我们将集群投入战斗。我们在Compressor中有一个半空的机架,大部分只被网络设备占用,我们将其放置在那里。因此,我们得到了第五个“数据中心”-物理上是四个,而资源池是五个。
我们计算了恒定载荷的体积和变量的体积。他们把常数变成了铁的负担。但是,这样一来,在硬件级别上,它就具有了云在弹性和冗余方面的优势。
钢铁项目的投资回收期为该年度云的平均价格。
你在这里
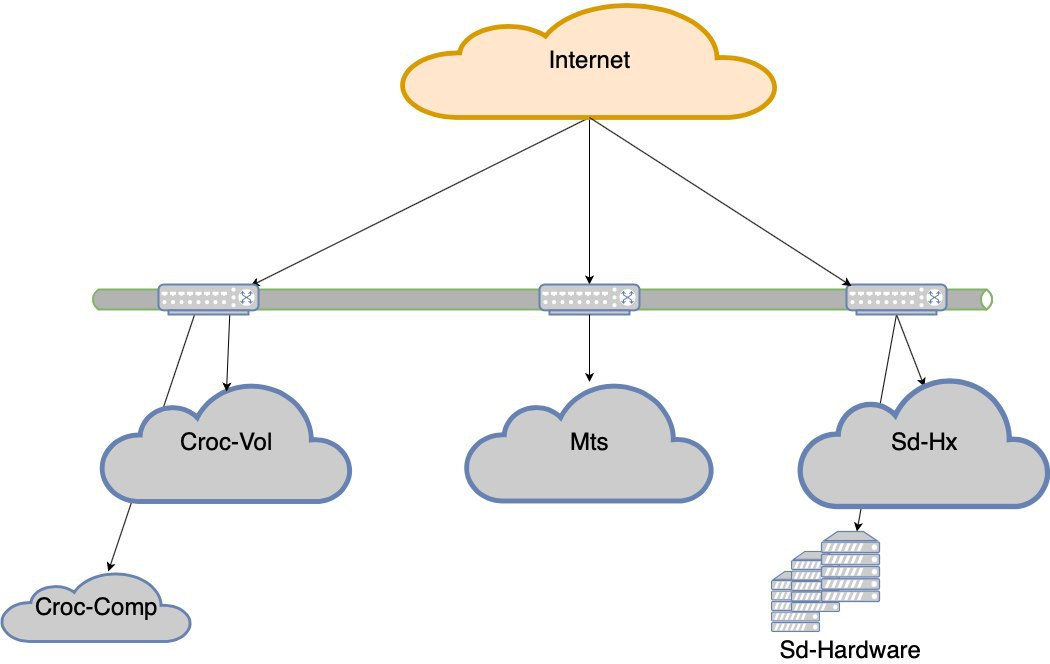
此刻,我们结束了强迫行动。如您所见,我们没有太多的经济选择,并且由于某些原因,我们不断加载必须承受的负担。这导致了负载不均匀的奇怪情况。任何网段的故障(以及具有Krok数据中心的网段都在两个Nexus瓶颈中保持)会丢失用户体验。也就是说,将保留该站点,但是在可访问性方面将存在明显的困难。
整个数据中心的MTS出现故障。其他两个。周期性地,云层脱落,云控制器或某种复杂的网络问题出现了。简而言之,我们会不时丢失数据中心。是的,时间很短,但仍然令人不愉快。在某些时候,他们认为数据中心正在崩溃。
我们决定采用数据中心级的容错能力。
现在,如果五个数据中心之一发生故障,我们就不会上床睡觉。但是,如果我们失去Croc的肩膀,将会出现非常严重的亏损。因此,数据中心弹性项目诞生了。目的是-如果DC死亡,网络在其死亡之前或设备在死亡之前,站点应在没有人工干预的情况下工作。另外,事故发生后,我们必须适当地康复。
有什么陷阱
现在:
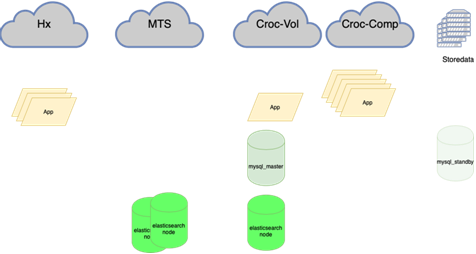
需要:
现在:
需要:
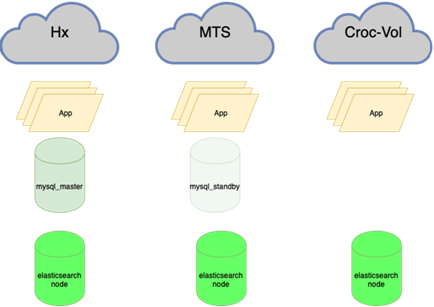
Elastic可以抵抗一个节点的丢失:
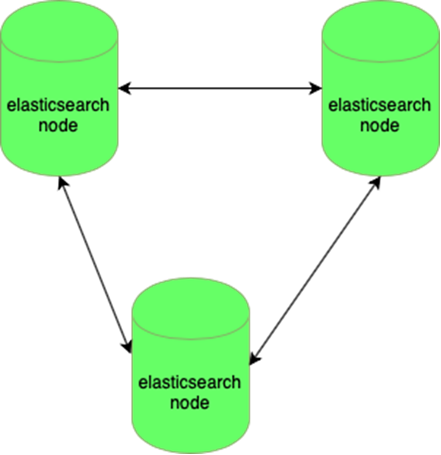
MySQL数据库(许多小型数据库)难以管理:
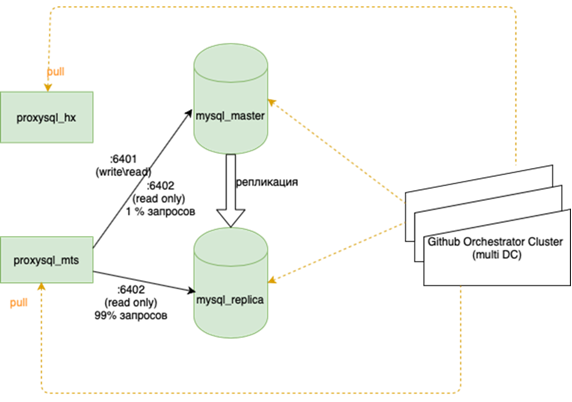
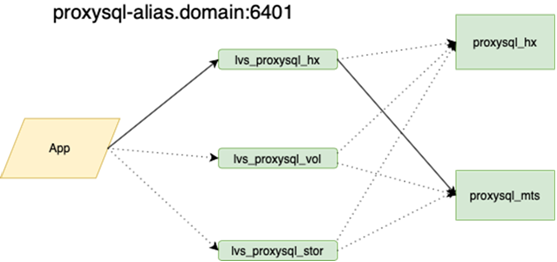
我的同事,做了平衡工作,将对此进行详细介绍。重要的是,在我们挂掉它之前,如果我们丢失了母版,那么我们必须动手去备用,并在那儿放上标记r / o = 0,用ansible将所有副本重建到这个新的母版上,并且在主花环中有两个以上的副本。数十个,更改应用程序配置,然后推出配置并等待更新。现在,该应用程序遍历一个Anycast-ip,它查看LVS平衡器。永久配置不会更改。协调器上的所有基本拓扑。
现在,黑暗的光学器件在我们的数据中心之间延伸,这使我们可以作为本地资源访问环网中的任何资源。数据中心之间的响应时间与内部的正负时间相同。这是与其他制造地理集群的公司的重要区别。我们与硬件和我们的网络紧密相连,我们不尝试在数据中心内部本地化请求。一方面,这很酷,但另一方面,如果我们要去欧洲或中国,那么我们将不会撤出我们的深色光学器件。
这意味着重新平衡几乎所有内容,主要是数据库。有很多方案可以使活动的读写主机承担整个负载,而在其旁边是同步副本以快速切换(我们不能一次写入两次,即进行复制,否则不能很好地工作)。主要基础位于一个数据中心,而副本数据库位于另一个数据中心。在第三份中,对于个别应用程序也可以有部分副本。根据季节的不同,这种情况有10到15种。 Orchestrator是数据中心和3个数据中心之间的延伸集群。在这里,当您有能力描述所有这些音乐的播放方式时,我们将更详细地告诉您。
您将需要深入研究应用程序。现在仍然需要这样做:有时,如果连接断开,则熄灭旧的连接,然后打开新的连接是正确的。但是有时,请求会在循环中已经丢失的连接中重复,直到进程终止。他们抓到的最后一件事是王冠的任务,没有发出关于火车的提醒
总的来说,还有事情要做,但是计划很明确。