分散注意力和有用信息的提示

如果您是统计学的入门课程,您将意识到可以将数据用于寻找灵感或检验理论,但不能同时适用于两者。这是为什么?
人们太擅长在所有事物中找到模式。您自己确定哪些模式确实存在,哪些模式是发明的。我们是在薯片中发现猫王面孔的生物。如果您想将模式与概念等同起来,请记住存在三种模式:
- 数据集中和外部都存在的模式。
- 仅存在于数据集中的模式。
- 仅在您的想象力中存在的模式(无听力)。
数据模式可以(1)存在于整个目标人群中,(2)仅存在于样本中,或者(3)仅存在于您的头脑中。
哪些模式和数据模式对您有用?这取决于您的目标。
灵感
如果您需要纯粹的灵感,数据可以成就奇迹。即使是重音症(人类倾向于错误地理解无关事物之间的联系和含义)也可以使您的创造力发挥最大作用。创意没有正确的答案,因此您要做的就是查看数据并进行处理。另外,请不要浪费太多时间(您或感兴趣的人)。
事实
当您的政府想向您收取税款时,它不能忽略超出您当年财务数据的价值。国税局需要对您的欠款做出事实决定,而做出该决定的主要方式是分析过去一年的数据。换句话说,查看数据并应用公式。在这种情况下,我们正在谈论与可用数据相关的纯粹描述性分析。前两种模式中的任何一种都对此有好处。
与现有数据相关的描述性分析。
(我从未隐藏过我的财务报表,但是我认为,如果我使用从研究生院学到的数据计算方法来统计地纳税,以取代它们,美国政府不会感到高兴。)
面对不确定性的决策
有时事实与期望的不一致。当您没有做出决定所需的全部信息时,应该在不确定性的指导下,尝试选择合理的行动方案。
这就是统计学的意义-面对不确定性时如何改变主意的科学。游戏的目的是像伊卡洛斯(Icarus)一样跳入未知世界……而不是被铁匠铺砸死。
这是数据科学的主要挑战:如何不因数据科学而变得无知。
从悬崖上跳下来之前,最好希望您在有限的现实视图中找到的模式确实在视图之外起作用。换句话说,为了对您有用,应该对模板进行概括。

在这三种类型的模式中,在不确定性下进行决策时,只有第一个(广义)模式是安全的。不幸的是,您会在数据中发现其他类型的模式-这是数据科学的核心问题:如何避免由于数据探索而失去意识。
概括
如果您认为在数据中查找无用的模式是纯粹的人类特权,请三思!如果您不小心,机器可以自动执行相同的操作。
机器学习和AI的重点是适当地推广新情况。
机器学习是一种做出许多类似决策的方法,其中包括算法搜索数据中的模式并使用它们来正确响应全新数据。在机器学习和AI行话中,泛化是指模型利用以前从未见过的数据表现良好的能力。基于模板的模型仅对旧数据有效的作用是什么?为此,您可以简单地使用查找表。机器学习和AI的全部重点是在新情况下进行正确的概括。

这就是为什么我们列表中的第一类模式是唯一非常适合机器学习的模式的原因。此类数据只是一个信号,其他所有东西都只是噪声(仅存在于旧数据中并且会干扰创建通用模型的因素)。
信号:既存在于数据集中也存在于外部的模式。
噪声:仅存在于数据集中的模式。
实际上,获得一种处理旧噪声而不是新数据的解决方案就是所谓的机器学习过拟合(我们用与您喜欢的诅咒词相同的语气来发音该术语)。在机器学习中,几乎所有的事情都会避免过度拟合。
那么,这个样本属于什么类型?
假设您(或计算机)从数据中提取的模式超出了您的想象-它属于什么类别?它是存在于您感兴趣的集合中的真实现象(信号)还是它是数据集的特征(噪声)?您如何确定在处理数据时发现的模式类型?
如果您检查所有可用数据,则将无法执行此操作。您会很困惑,无法判断您的模板是否存在于其他位置。有关测试统计假设的所有措辞都取决于意外情况,并假装众所周知的模式会使您感到不愉快(实际上,这是黑客行为)。

就像看到兔子形状的云,然后检查所有云是否看起来都像兔子……看着同一朵云。我希望您了解您将需要新的云来检验您的理论。
用于表述理论或问题的任何数据均不能用于验证同一理论。
如果您知道自己只能访问一个云,该怎么办?在储藏室里沉思,就是这样。在查看数据之前先问您的问题。
数学永远不会违背常识。
在这里,我们得出最可悲的结论。如果将数据集用于启发,则无法再次使用它来彻底测试其启发的理论(无论您使用什么数学柔术技巧,数学都不会违背常识)。
艰难的选择
关键是您必须做出选择!如果您只有一个数据集,那么您将被迫问自己:“我在壁橱里冥想,为统计检验制定我的假设,然后仔细采取严格的方法-所有这些,以便我能认真对待自己?还是我只是在收集数据以获取灵感,同时我了解自己会自欺欺人,还记得我应该使用“我感觉”或“它激发”或“我不确定”等短语?” 艰难的选择!
还是有办法两次吃一块蛋糕?问题在于您只有一个数据集,并且需要多个数据集。如果您有足够的数据,那么我有一个窍门。爆炸。你的。脑。

棘手的把戏
要在数据科学中取得成功,只需将数据划分成一个(至少)一个数据集就变成两个。然后使用其中一个进行启发,使用另一个进行严格的测试。如果最初启发您的模式也存在于不会影响您观点的数据中,则该模式很可能是从猫砂中获取数据的通用规则。
如果两个数据集中都出现相同的现象,则这可能是一条适用于该数据集所有源的通用规则。
RSChD!
由于没有探索的生活根本就不是生活,因此有四个词可以依靠:分享您该死的数据。
如果每个人都共享他们的数据,那么世界将会变得更加美好。我们将有更好的答案(感谢统计数据)和更好的问题(感谢分析数据)。人们不将数据共享视为强制性习惯的唯一原因是因为在上个世纪,它是一种极少数人负担不起的奢侈品。数据集是如此之小,以至于您尝试拆分它们时,可能没有剩余。
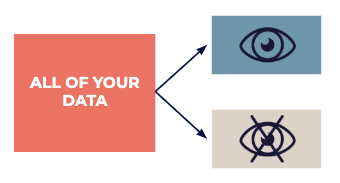
将您的数据划分为可用于启发的公共探索性数据集,然后将由专家使用测试数据集来确定在探索阶段发现的任何“猜测”。
有些项目仍然面临这个问题,尤其是在医学研究中(我曾经做过神经生物学,所以我非常尊重使用小数据集的复杂性),但是其中许多人拥有的数据太多,因此您需要聘请工程师,只是为了安排他们的活动...您有什么借口?不要跳过,共享您的数据。
如果您不习惯共享数据,则可能会陷入20世纪。
如果您有大量数据,并且没有对它们的集合进行分割,那么您将处于过时的范式中。存在于这种范式中的人们已经屈服于古老的思想,并拒绝及时发展。
机器学习-数据分区的后代
最后,这个想法很简单。使用一个数据集来形成理论,理解这些数据,然后做魔术-在全新的数据集上证明您的想法的真实性。
数据共享是更健康的数据文化的最简单快速解决方案。
这样,您可以安全地使用统计方法,并确保自己不会过度拟合。实际上,机器学习的历史就是数据共享的历史。
如何在数据科学中运用最佳创意
要利用数据科学中的最佳创意,您所要做的就是确保将测试数据放在无法窥探的范围之内,然后让您的分析师为其余的事情疯狂。
要在数据科学领域取得成功,只需通过拆分数据将一个数据集变成(至少)两个数据集即可。
当您确定他们为您带来了超越他们所学的有用信息时,请使用您的测试数据秘密缓存来验证您的发现。

通过完成SkillFactory付费在线课程,了解如何从头开始或成为技能和薪资水平升级的热门职业的详细信息:
- 机器学习课程(12周)
- 从头开始培训数据科学专业(12个月)
- (9 )
- «Python -» (9 )