在本文的结尾,我们将与您分享有关此主题的最有趣的材料列表。

新的方法
增强型多主体学习是一个不断发展且丰富的研究领域。但是,在多主体环境中不断使用单主体算法会使我们处于困境。由于许多原因,学习很复杂,尤其是由于:
- 独立代理人之间的不稳定;
- 动作空间和状态的指数增长。
研究人员发现了许多减少这些因素影响的方法。这些方法大多数都属于“集中式计划与分散式执行”的概念。
集中计划
每个代理都可以直接访问本地观测值。这些观察结果可能非常多样:环境图像,相对于某些地标的位置甚至相对于其他媒介的位置。此外,在培训期间,所有代理均由中央模块或评论员管理。
尽管每个座席只有本地信息和本地策略进行培训,但是有一个实体可以监视整个座席系统并告诉他们如何更新策略。因此,减少了非平稳性的影响。使用该模块的全球信息对所有座席进行培训。
分散执行
在测试期间,将删除中央模块,但是保留具有其策略和本地数据的代理。由于从未研究总体策略,因此减少了因动作和状态空间增加而造成的损害。相反,我们希望中央模块具有足够的信息来管理本地学习策略,以便在进行测试时尽快对整个系统进行优化。
开放AI
来自OpenAI,加利福尼亚大学伯克利分校和麦吉尔大学的研究人员已经使用“ 多代理深度确定性策略梯度”引入了一种新的多代理设置方法。这种方法受到其单一代理人DDPG的启发,采用了从参与者到批评者的培训,并且显示出非常可喜的结果。
建筑
本文假定您熟悉MADDPG的单代理版本:深度确定性策略梯度或DDPG。为了刷新您的记忆,您可以阅读Chris Yoon的精彩文章。
每个代理都有一个观察空间和一个连续动作空间。每个代理还具有三个组件:
- , ;
- ;
- , - Q-.
随着评论家逐渐了解一个函数的联合Q值,他将Q值的相应近似值发送给演员以帮助他学习。在下一节中,我们将更详细地研究这种交互。
请记住,评论者可以是所有N个代理之间的共享网络。换句话说,不是训练N个评估相同价值的网络,而是训练一个网络并使用它来帮助训练所有其他代理。如果代理是同质的,同样适用于参与者网络。
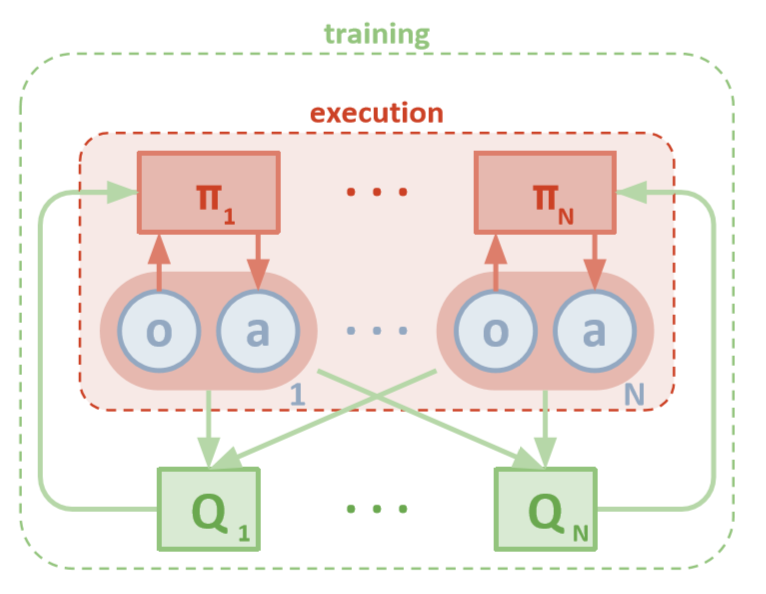
MADDPG体系结构(Lowe,2018)
训练
首先,MADDPG使用经验重播来进行有效的非政策学习。在每个时间间隔,代理存储以下过渡:
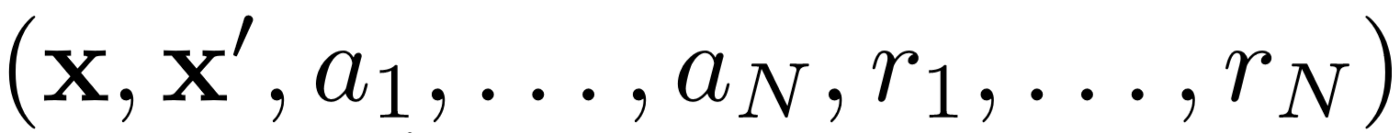
我们在其中存储联合状态,下一个联合状态,联合动作以及代理收到的每个奖励。然后,我们从体验重播中获取了一系列这样的过渡,以训练我们的经纪人。
批评更新
要更新代理的主要批评者,我们使用超前TD错误:
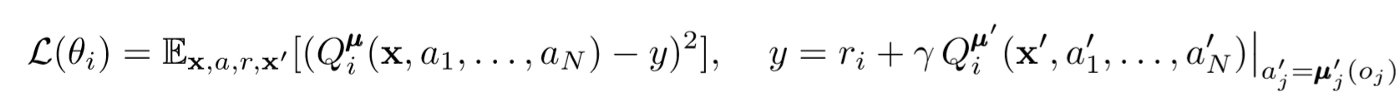
其中μ是参与者。请记住,这是一个中央批评者,也就是说,他使用常规信息来更新其参数。基本思想是,如果您知道所有代理都采取的措施,那么即使策略更改,环境也将保持稳定。
计算Q值时,请注意表达式的右侧。尽管我们从不保存下一个协同作用,但我们使用代理的每个目标参与者来计算更新过程中的下一个动作,以使学习更加稳定。目标角色的参数会定期更新,以匹配代理角色的参数。
演员更新
像单代理DDPG一样,我们使用确定性策略梯度来更新每个代理参与者参数。
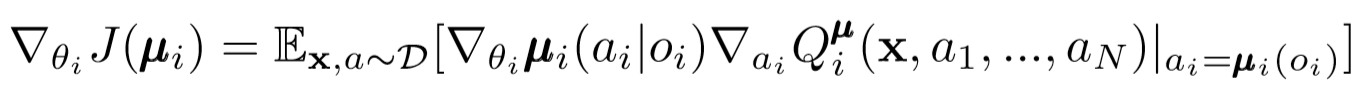
其中,μ是代理角色。
让我们更深入地了解这种更新的表达方式。我们使用中心注释器来获取相对于演员参数的梯度。要注意的最重要的事情是,即使演员只有局部的观察和动作,在训练过程中,我们也会使用中央评论员来获取有关他的动作在整个系统中的最优性的信息。这减少了非平稳性的影响,并且学习策略仍保留在较低的状态空间中!
政客的结论和政客团体
我们可以在权力下放问题上再迈出一步。在以前的更新中,我们假定每个代理将自动识别其他代理的操作。但是,MADDPG建议从其他代理商的政策中得出结论,以使学习更加独立。实际上,每个代理都会添加N-1个网络来评估所有其他代理的策略有效性。我们使用概率网络来最大化对数推论出另一代理的观察到的对数概率。
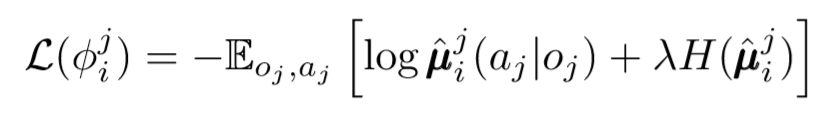
在这里,我们看到第i个代理的损失函数使用熵正则化器评估第j个代理的策略。结果,当我们用预测的动作替换座席的动作时,我们的目标Q值会略有不同!
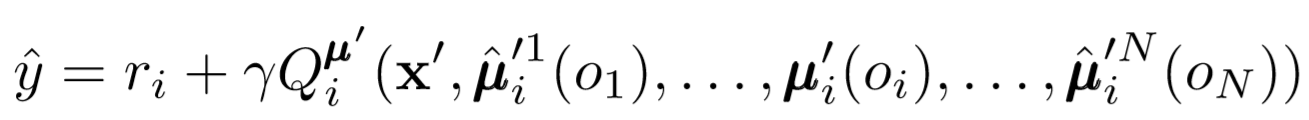
那么到底发生了什么?我们删除了代理之间相互了解对方政策的假设。取而代之的是,我们尝试通过一系列观察来训练代理商以预测其他代理商的政策。实际上,每个代理都是独立学习的,从环境中接收全局信息,而不是默认情况下只有全局信息。
政治团体
上述方法存在一个大问题。在许多多代理设置中,尤其是在竞争性设置中,代理可以创建可以重新训练其他代理行为的策略。这将使该策略脆弱,不稳定并且通常不是最佳的。为了弥补这一缺点,MADDPG为每个代理训练了K个子策略集合。在每个时间步长,代理都会随机选择一个子策略来选择操作。然后他做到了。
政治梯度变化很小。我们对K个子策略进行平均,使用等待线性,并使用Q值函数传播更新。
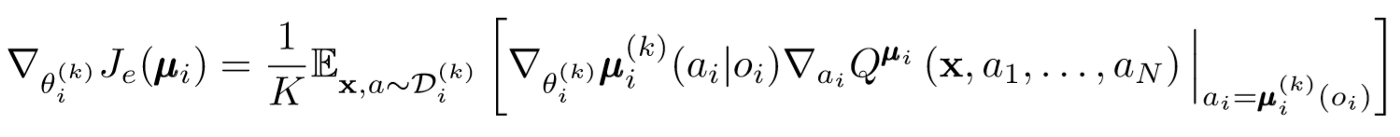
让我们退后一步
这就是整个算法的整体外观。现在,我们需要回过头来,了解我们所做的事情,并直观地了解其工作原理。基本上,我们做了以下工作:
- 已为仅使用本地观察结果的代理商确定了演员。这样,可以控制状态和动作空间呈指数增长的负面影响。
- 为每个使用共享信息的代理确定了一个中央批评家。因此,我们能够减少非平稳性的影响,并帮助参与者成为全球系统的最佳选择。
- 确定了来自策略的结论网络,以评估其他代理的策略。通过这种方式,我们能够限制代理的相互依赖性,并消除了代理获取完美信息的需求。
- 已定义的策略集合,以减少对其他代理的策略的影响和再培训的可能性。
该算法的每个组件都具有特定的独特目的。使MADDPG功能强大的因素如下:它的组件经过专门设计,克服了多代理系统通常面临的主要障碍。接下来,我们将讨论算法的性能。
结果
MADDPG已在许多环境中经过测试。可以在文章[1]中找到对其工作的完整评论。在这里,我们只讨论合作交流的问题。
环境概况
有两个代理:说话者和听者。在每次迭代中,侦听器都会在您要移动到的地图上收到一个彩色圆点,并收到与到该点的距离成比例的奖励。但这很重要:收听者仅知道他的位置和终点的颜色。他不知道应该转移到哪一点。但是,说话者知道当前迭代的正确点的颜色。结果,两个代理必须交互才能完成此任务。
比较方式
为了解决这个问题,本文对比了MADDPG和现代的单代理方法。使用MADDPG可以看到明显的改进。
研究还表明,即使没有对政治家进行理想的培训,来自政策的推论也能获得与使用真实观察所能达到的相同结果。此外,融合没有明显放缓。
最后,一群政客已经显示出非常有希望的结果。论文[1]探讨了合奏在竞争环境中的影响,并证明了相对于单一策略代理的显着性能改进。
结论
就这样。在这里,我们研究了一种多主体强化学习的新方法。当然,有无数种与MARL相关的方法,但是MADDPG为解决多智能体系统最全局问题的方法提供了坚实的基础。
资料来源
[1] R. Lowe,Y。Wu,A。Tamar,J。Harb,P。Abbeel,I。Mordatch,混合合作竞争环境下的多代理演员-批评家(2018)。
有用文章清单
, , , . .