
实际上,这就是寻找银行站点布局中的缺陷的历史,这导致在搜索时其主页面的显示不正确。在由例如在线构造器组装或由例如不熟悉搜索引擎优化基础知识的布局设计师设计的站点上经常会遇到类似的问题。
如果这个故事没有触及其他网站维护专家可能想知道的一项未记录的索引编制功能,那么它只会对一小撮实践的塞奥尼克人保持有趣。我邀请他们在猫下。
简短介绍
任何经验丰富的SEO主管都知道搜索引擎搜寻器对网站页面进行语义解析的规则。这些规则受某些Internet技术标准的某些规定的约束。例如:
- <title>标签是整个文档的唯一名称,仅在其标题部分使用,并且只能使用一次;
- <h1>标签成为文档的特定部分的标题,并且可以重复使用,但是只能在另一部分使用,并且在同一文档的所有<h1>标签之间保持唯一性;
- <h2>标记是段字幕,即使在该段的对等字幕中是唯一的,也可以在同一段中重复使用;
- <h3>标签是上级字幕的字幕;
- …等等
当然,在对页面进行索引分析之前,这些规则有不同的细微差别,每个搜索服务器都会以自己的方式来解释这些细微差别:
- , «», — , <p> ;
- (outlines), «» — , <h2> <p> () ;
- … .
这些语义分析和细微差别的规则对我们来说还不重要。而且,如果您对内容索引所基于的技术标准的某些条款非常感兴趣,则概述出版物[1]中会在网站的一页上明确允许使用多个<h1>标签,这些条款的主要部分已经非常清楚地说明了。
我将仅指出,SEO管理员已经习惯了这种细微差别,这并不是他们第一次根据自己的经验来验证其有效性,并且长期以来一直在考虑将标签的优先级视为考虑因素来推广搜索网站。毕竟,了解索引编制的原理使得可以部分“控制”文本,以响应用户的请求显示站点的搜索摘要。
但是几天前,内部信息显示,在与乌克兰Monobank官方网站相关的自然搜索结果中,该片段的行为令人难以理解:搜索引擎根本没有使用<title>或<h1>标记该片段。也就是说,撰稿人可以编写最独特的标题和文本,内容管理员可以在站点中插入文本,但是搜索仍然是错误的。
有必要了解原因,我将进一步讨论。
研究的第一步
因此,首先,我清除了缓存和浏览器的历史记录,将其重新启动,打开了Google搜索框并输入了银行名称。为了使即使我没有SEO经验的人也能理解我所采取的每个步骤,我为第一步做了一张照片。
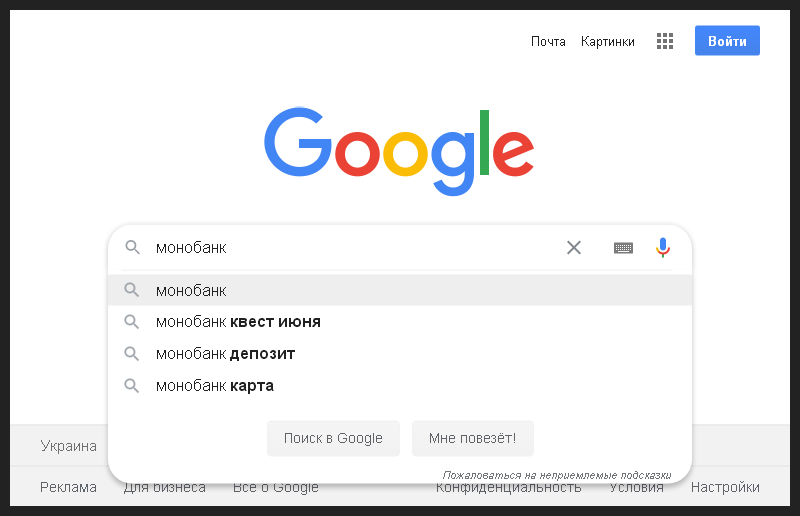
这是一个品牌信息请求,这意味着首先要取得自然结果,因此有理由期望该银行的主页出现一个摘要。
一切都按预期进行,该代码段是搜索中的第一个,并且还包含指向该网站主要部分的快速链接。我在下一张照片中捕捉了这一刻。
到目前为止,一切看起来都很正常。

为了确保不清楚的情况仅出现在Google搜索结果中,我在Yandex搜索中重复了相同的查询,并愉快地注意到该搜索巨头遵循通常的规则:该代码片段的标题为monobank-移动银行 -完全与所需代码的<title>标记中所写的相同。页面。

Google搜索快照的答案至少在标题方面根本不同。此外,我对Google摘录标题下的荒谬文字感到有些困惑。
我认为这仅仅是一个事实的后果,经过SMM品牌的推广和它的移动应用程序,这是由Promodo在2017年至二○一八年进行[2]对于前者域monobank.com.ua,雇佣更多的搜索引擎优化大师,以保持新域的单一银行.ua不再有意义。毕竟,广告战取得了预期的效果。该银行的管理层很可能在推广新域的搜索引擎方面取得了目标,或者将责任分配给了专职的IT专家。
因此,我将当前文本的笨拙归因于普通员工不愿检查要求的结果,这是典型的银行用户永远不会实际拨打的。
毕竟,银行的客户大部分是通过移动应用程序访问该网站的,几乎没有观察到银行页面在搜索中的外观。通过互联网搜索的那部分客户主要使用以下形式的查询:
- Monobank美元汇率;
- 单一银行汇率;
- 开一个单一银行账户;
- 制作银行卡;
- 创建一个monobank卡;
- 银行信用卡;
- 获得单一银行贷款;
- 接受单一银行贷款;
- …等等
在任何一家银行中,都可以找到满足模板“在哪里找到什么+哪里”或“哪里+什么”并带来自然搜索带来的最大胆流量的此类搜索短语的完整列表。
检查美味查询
对于大多数查询,当搜索结果中出现相同的标题,标题和愚蠢的文本而几乎与输入的查询不匹配时,我感到非常惊讶。
我在下一张照片中拍摄了这样一个请求的示例,并指出了问题所在。

而且,几乎所有请求的代码片段的目标地址(URL)都指向首页的顶部,甚至没有将其部分锚定在与当前请求相关的地址中。
好吧,假设,如果请求是关于汇率的,并且相应的部分将出现在目标登录页面上,则将链接与该部分的链接锚定到该散列(如monobank.ua/#kurs-valut)并用相同锚定URL的规范化将是合乎逻辑的,以便搜索机器人能够着陆页具有对应搜索词组的多个着陆点,这将由常规SEO在由他们放置在站点上或站点外(例如,社交网络中)的链接的锚定文本中详细说明。
否则,所有内容似乎都由网站开发人员分配给主页的多节着陆角色,但他们没有告诉服务人员,他们提出了带有计划锚文本的链接,但没有节锚。结果,用于不同类型请求的所有链接似乎都落入了主页的初始入口点,并且不可避免地收到了一个带有与主页的主要部分相关的标题的片段。
小题外话
为了以防万一,我将在下一张图片中显示HTML标记的示例,该示例说明了如何使用语义布局来解决网站的单个着陆页上的多个着陆点的问题。

当然,只要我们使用与信息案例相对应的锚点放置指向登录页面的链接,该方案就可以工作。即:
- monobank.ua-基本信息;
- monobank.ua/#kurs-valut-关于汇率;
- monobank.ua/#otkryt-schet-关于开设帐户;
- monobank.ua/#kreditnaja-karta-关于信用卡。
但是回到检测到的SEO门框
该错误虽然不是很严重,但是由于客户的主要流量仍然流经移动应用程序,尽管如此,由于该错误,银行损失了部分搜索流量。由于搜索用户分为两种-匆忙的多数和悠闲的少数:
- 前者仅读取摘要的标题,如果标题的含义与输入的请求匹配,则单击它们;
- 后者会仔细阅读标题及其下方的文本,并仅在含义一致时单击。
很明显,在银行页面的僵化的搜索代码片段中,消息的含义仅与很小一部分请求重合。有必要了解错误的出处。
查看母版页的标记
我按照摘录中的链接打开了银行的主页。此页面的源代码包含单个<h1>标记,通常用于编写主页标题,该标题通常也位于代码段标题中。
此外,在标题<h> -tags其余部分之前的页面代码中使用了此主标题标签。因此乍看之下,它似乎没有SEO错误。
我为该页面拍照,并在其上标记了前两个标题<h>标签的位置。
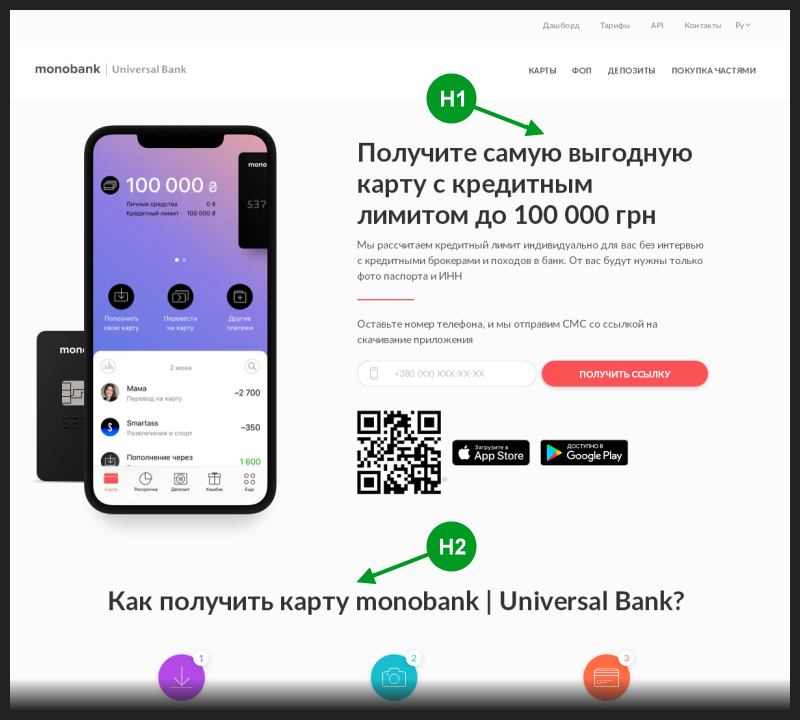
合理地期望<h1>标签将代替搜索代码片段的标题。但是由于某种原因,每次都会降级一个标签。
起初,我认为此案仅涉及包括银行名称在内的查询。 <h1>标记没有它,但是<h2>标记却有-因此,尽管该标记的排名较低,但仍具有接管代码片段标题的优势。
但是,此假设很容易验证:您需要编写一个完全等于<h1>标记的请求,然后确保该标题标记具有基于与请求的绝对匹配来占据摘录标题的权利。我所做的,同时在下一张照片中修复了结果。

从快照可以看出,搜索服务器仍然可以看到并理解<h1>标记的文本,但是由于某种原因,它并不将其视为该银行网站上的主要标题。这有两种情况:
- 搜索引擎优化大师向页面布局添加了特定的语义微标记,从而指示另一个标签成为主要标题;
- 或存在所谓的“在线设计师问题”,这是由于构件的搜索次优性导致他们的文本标签出现在HTML文档的不同部分中,而主要标题标签比非主要标题标签在其部分的轮廓中被省略得更深。
我决定先检查第一种情况,然后在结构化数据验证工具中打开该站点。但是,仅发现了开放图谱微标记,没有暗示强制重新分配标签语义的迹象。
我在下一张照片中捕捉了这一刻。

然后,我打开问题页面的源代码,格式化空格以便于研究,出于相同目的删除了标签属性,然后在下一张图片中指出了问题的实质。

因此,我们对事务状态进行了以下解释,在此我将预先写下一个重要的结论:在网站启动一个月后(这大约是索引机器人的平均爬网时间),请确保检查几个关键查询,搜索引擎如何看待您的页面标记,即哪些部分他实际编入索引的内容。
结果的解释
Yandex在新的Monobank域上解析页面时,未找到语义布局(因为所有内容均使用<div>进行布局),并且由于没有说明来分析隐式语义,因此没有按标记类进行猜测,并且在选择摘要标题时,它仅使用了规范中的规则:tag <title>是文档的主要标题。
Google在解析同一页面时也没有找到语义布局,但是其人工智能能够分析隐藏的语义特征,因此它注意到四个具有隐式语义类内容的 <div>表示当前标记情况下的剖面轮廓。因此,有关<title>标记的规则被拒绝,搜索引擎使用了节概述规范中的规则,试图从声明的四个中找到合适的节。第一部分是不合适的,因为它的标题标签比第2、3和4部分中的标题标签更远离轮廓。在这些更合适的部分中,根据第二部分与文档开头的接近程度来选择第二部分。这就是标题的标题。
实际上,对于两个搜索引擎来说,摘要的标题选择逻辑是相同的。仅仅是Yandex从文档的第一个大纲(隐式地为<head>标记)中选择了第一个标题标记,而Google-从语义标记的大纲中选择了第一个标题标记(显然是<div class =“ content”>标记)。
这就是搜索的惊人功能,在我调查开始时称为“未记录”。<h1>标记实际上没有任何重要迹象。基于用户的搜索查询,在不考虑使用的数字标题级别的情况下,选择了文档中的匹配节大纲和大纲中的第一个标题。
二手材料
[1] 一个H1或更多-为什么这样呢?,2020年3月。Impera,SEO文件。HTML标准规范的摘录显示,在两种情况下,在页面上写入一个或多个H1标签都被认为是正确的。
[2] Monobank移动应用推广案例,2017年8月至2018年3月。Promodo,案例。在代理商使用的事件的示例中,描述了如何使用AdWords,Facebook,Instagram,Twitter,YouTube推广iOS和Android上的移动应用程序,以及如何在App Store和Google Play中进行优化。