该说明描述了一种在技术条件非常有限的情况下创建企业数据仓库的小型副本的实验。即基于单板计算机的Raspberry Pi。
该模型和体系结构将得到简化,但类似于企业级存储。结果是评估了在数据处理和分析领域使用Raspberry Pi的可能性。

#1
甲骨文公司的Exadata X5平台(一个部门)将扮演一个经验丰富且实力雄厚的角色。
数据处理过程包括以下步骤:
- 从10.3 GB的文件中读取-90分钟内可读取3.5亿条记录。
- 处理和数据清理-2个SQL查询和15分钟的时间(加密个人数据180分钟)。
- 加载测量-10分钟。
- 向事实表加载2000万新记录-5个SQL查询和35分钟。
在2.5小时内总共集成了3.5亿条记录,相当于每分钟230万条记录,或每秒约39000原始数据记录。
2号
实验对手将是具有1.4 GHz 4核处理器的Raspberry Pi 3 Model B +。
Sqlite3用作存储,使用PHP读取文件。文件和数据库位于内置读取器中的32GB 10级SD卡上。在连接到USB的64 GB闪存驱动器上创建备份。关于小型存储
的文章中介绍了sqlite3关系数据库和报告中的数据模型。
资料模型
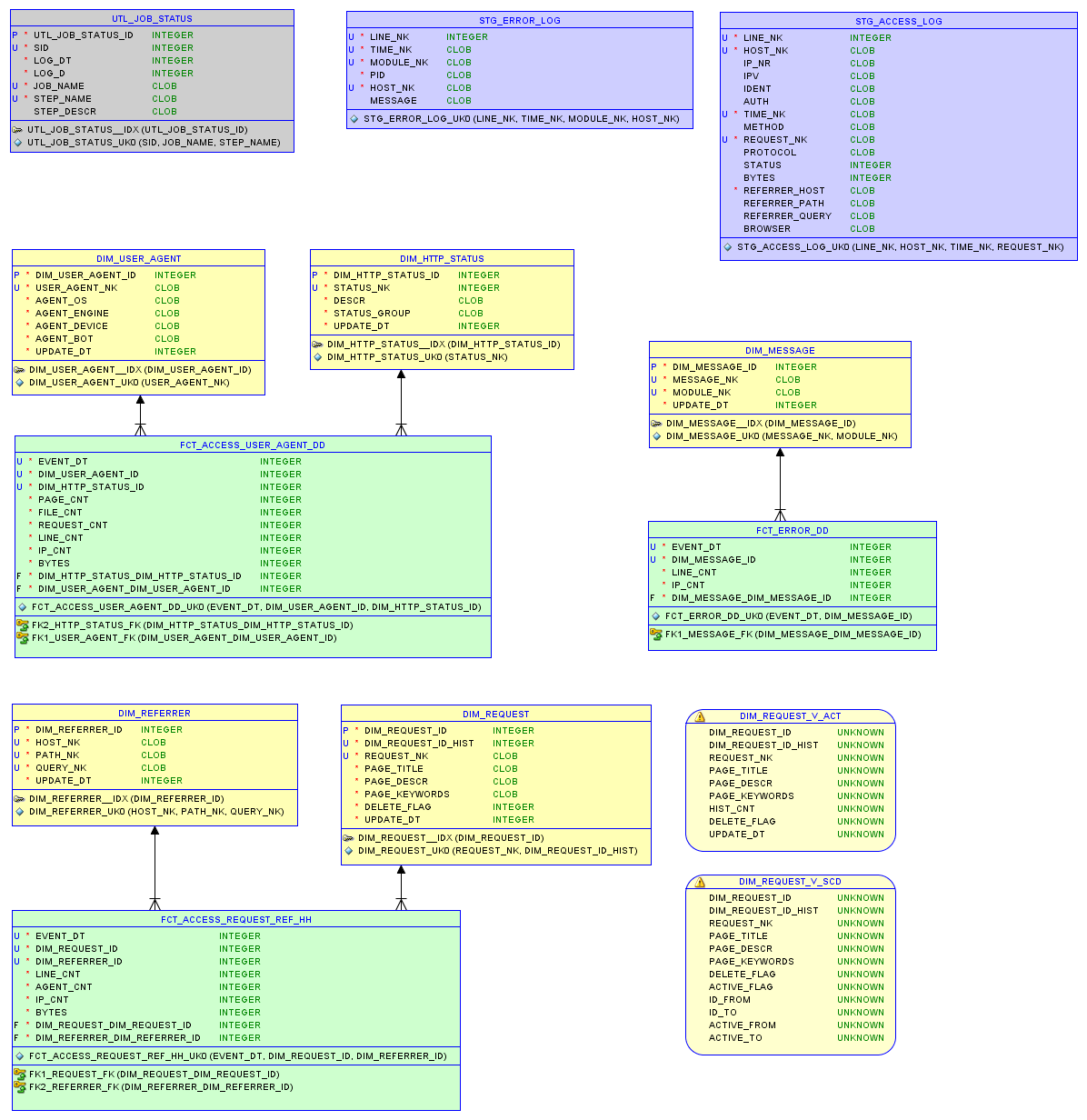
测试一
原始的access.log文件为37 MB,包含200,000个条目。
- 花费了340秒读取日志并将其写入数据库。
- 加载具有5000条记录的测量值需要5秒钟。
- 用9万条新记录加载事实表-32秒。
总计 20万条记录的整合耗时近7分钟,相当于每分钟28000条记录或每秒470条源数据记录。数据库为7.5 MB;仅8个SQL查询用于数据处理。
第二次测试
更多活动站点文件。原始的access.log文件为67 MB,包含29万个条目。
- 花费了670秒的时间来读取日志并写入数据库。
- 加载具有2.5万条记录的测量结果需要8秒钟。
- 向事实表加载24万条新记录-80秒。
总共 290,000条记录的集成仅花费了12分钟以上的时间,相当于每分钟23,000条记录或每秒380条原始数据记录。数据库是22.9 MB
输出量
为了获得能够进行有效分析的模型形式的数据,在任何情况下都需要大量的计算和物质资源,并且需要时间。
例如,一个Exadata单元的成本超过10万。一台Raspberry Pi售价为60单位。
它们无法进行线性比较,因为随着数据量和可靠性要求的增加,出现了困难。
但是,如果您想象一千个Raspberry Pi并行工作的情况,那么根据实验,它们将每秒处理约40万条源数据记录。
而且,如果将Exadata的解决方案优化为每秒60或10万条记录,那么这将大大少于40万条。这证实了企业解决方案价格过高的内在感觉。
无论如何,Raspberry Pi非常适合处理适当规模的数据和关系模型。
链接
家用Raspberry Pi已配置为Web服务器。我将在下一篇文章中描述此过程。
你可以用树莓派的性能和access.log文件自己实验的。可以从此处下载数据库模型(DDL),加载过程(ETL)和数据库本身。这个想法是通过最近几周的数据从日志中快速了解站点的状态。
更改
由于有了注释,修复了Exadata文件加载错误,并且注释中的数字也已修复。Sqlloader用于读取,一些甲虫删除了BINDSIZE和ROWS参数。由于从远程驱动器启动不稳定,因此选择了常规方法,而不是直接路径,这可以使速度再提高30-50%。